大数据环境搭建-HBase和Zookeeper
前言
推荐HBase版本2.1.10。
特点
是一种面向列族存储的非关系型数据库。
用于存储结构化和非结构化的数据 适用于单表非关系型数据的存储,不适合做关联查询,类似 JOIN 等操作。
基于HDFS,数据持久化存储的体现形式是 HFile,存放于 DataNode 中, 被 ResionServer 以 region 的形式进行管理。
延迟较低,接入在线业务使用。
通过JPS查看进程
Master可能的进程:
| 进程名 | 是否必须 | 所属 | 说明 |
|---|---|---|---|
| HMaster | 必须 | Hbase | 表明该Hbase是Master |
| HRegionServer | 非必须 | Hbase | 因为我们也将该Master设置为Region |
| QuorumPeerMain | 必须 | Zookeeper | 单独配置的Zookeeper集群,如果是内置的则为HQuorumPeer |
| NameNode | 必须 | Hadoop | Hadoop NameNode |
| SencondNameNode | 必须 | Hadoop | 任务调度器 |
HRegion可能的进程:
| 进程名 | 是否必须 | 所属 | 说明 |
|---|---|---|---|
| HRegionServer | 必须 | Hbase | 表明是Hbase存储节点 |
| QuorumPeerMain | 必须 | Zookeeper | 单独配置的Zookeeper集群,如果是内置的则为HQuorumPeer |
| DataNode | 必须 | Hadoop | 数据存储 |
部署模式
HBase的部署方式包括:
| 部署模式 | 说明 |
|---|---|
| 单机模式(支持Windows) | 常用于本地开发 |
| 伪集群模式(不支持Windows) | 使用HBase自带的zookeeper |
| 集群模式(不支持Windows) | 使用HBase自带的zookeeper |
| 集群模式(不支持Windows) | 单独安装zookeeper |
HBase的安装
本文的HBase安装是在Hadoop已经安装好的基础上实现的,所以之前要导出JAVA_HOME、HADOOP_HOME( 单机模式不需要,伪分布式模式和分布式模式需要)等环境变量以及配置好SSH互信等。
下载地址
https://archive.apache.org/dist/hbase/2.1.10/
安装
1 | mkdir -p /data/tools/bigdata/ |
环境变量
环境变量
1 | cd /etc/profile.d/ |
创建配置文件
1 | vi /etc/profile.d/hbase.sh |
内容设置为
1 | # HBase |
配置生效
1 | source /etc/profile |
查看是否生效
1 | echo $HBASE_HOME |
查看hbase版本 :
1 | hbase version |
环境变量分发
1 | ha-fenfa.sh /etc/profile.d/hbase.sh |
HBase的配置
单机模式
配置hbase-env.sh 在hbase-env.sh添加如下内容
1 | export JAVA_HOME=/usr/java/jdk1.8.0_221-amd64 |
说明:
其中
HBASE_MANAGES_ZK=true,表示由hbase自己管理zookeeper,不需要单独的zookeeper
HBASE_MANAGES_ZK=false则表示使用独立部署的zookeeper。
配置hbase-site.xml
1 |
|
说明:
hbase.rootdir,用于指定HBase数据的存储位置,因为如果不设置的话,hbase.rootdir默认为/tmp/hbase-${user.name},这意味着每次重启系统都会丢失数据。
此配置中HBase直接使用默认的文件系统。
启动和停止
1 | $HBASE_HOME/bin/start-hbase.sh |
伪集群模式
配置hbase-env.sh 在hbase-env.sh添加如下内容
1 | export JAVA_HOME=$JAVA_HOME |
export HBASE_MANAGES_ZK=true,表示由hbase自己管理zookeeper,不需要单独的部署zookeeper。
export HBASE_CLASSPATH="", 表示使用hdfs作为HBase的储存。
配置hbase-site.xml
1 | <configuration> |
说明:
base.rootdir,用于指定HBase数据的存储位置,此时已经使用了hdfs。 hbase.cluster.distributed设置集群处于分布式模式;
启动和停止
启动HBase
1 | $HBASE_HOME/bin/start-hbase.sh |
停止HBase
1 | $HBASE_HOME/bin/stop-hbase.sh |
启动HDFS
1 | $HADOOP_HOME/sbin/start-dfs.sh |
停止HDFS
1 | $HADOOP_HOME/sbin/stop-dfs.sh |
集群模式(内置Zookeeper)
配置hbase-env.sh 在hbase-env.sh添加如下内容
1 | export JAVA_HOME=$JAVA_HOME |
HBASE_MANAGES_ZK=true,表示使用hbase自带的zookeeper。
配置hbase-site.xml
1 | <configuration> |
说明:
- base.rootdir 用于指定HBase数据的存储位置;
- hbase.cluster.distributed 设置集群处于分布式模式;
- hbase.master 指定hbase的hmaster的主机名和端口 ;
- base.zookeeper.quorum 指定使用zookeeper的主机地址,必须是奇数个;
- hbase.zookeeper.property 指定zookeeper数据存储目录,默认路径是/tmp,如果不配置,重启之后数据将被清空。
配置regionservers 在regionservers文件中添加HBase的slave节点,类似hadoop中的slaves,一行一个。
1 | hadoop01 |
启动和停止 启动(包括启动hdfs和hbase)
1 | $HBASE_HOME/sbin/start-dfs.sh |
停止(包括停止hbase和hdfs)
1 | $HBASE_HOME/bin/stop-hbase.sh |
HBase启动成功之后:
master节点上的进程有:HMaster
slave节点上的进程有:HRegionServer、HQuorumPerr
集群模式(独立Zookeeper)
Zookeeper参见
https://www.psvmc.cn/article/2022-05-23-bigdata-zookeeper.html
配置
配置hbase-env.sh
1 | export JAVA_HOME=$JAVA_HOME |
其中HBASE_MANAGES_ZK=false,表示不使用hbase自带的zookeeper,而使用独立部署的zookeeper。
配置hbase-site.xml
1 |
|
说明:
- base.rootdir 用于指定HBase数据的存储位置;
- hbase.cluster.distributed 设置集群处于分布式模式;
- hbase.master 指定hbase的hmaster的主机名和端口 ;
- hbase.zookeeper.quorum 指定使用zookeeper的主机地址,必须是奇数个;
- hbase.zookeeper.property 指定zookeeper数据存储目录,默认路径是/tmp,如果不配置,重启之后数据将被清空。
注意
hbase.zookeeper.quorum中不要添加端口号,否则与Phoenix Query Server集成后Phoenix Query Server无法连接。
配置regionservers 在regionservers文件中添加HBase的slave节点,类似hadoop中的slaves,一行一个。
1 | hadoop01 |
backup-masters
这个可以不配置
1 | hadoop02 |
backup-masters 这个文件是不存在的,需要新建,主要用来指明备用的 master 节点,可以是多个,这里我们以 1 个为例。
分发
1 | ha-call.sh "rm -rf $HBASE_HOME/logs/*" |
启动和停止
先启动Zookeeper和Hadoop
启动Hbase
1 | $HBASE_HOME/bin/start-hbase.sh |
停止Hbase
1 | $HBASE_HOME/bin/stop-hbase.sh |
HBase启动成功之后:
master节点上的进程有:HMaster、QuorumPeerMain
slave节点上的进程有:HRegionServer、QuorumPeerMain
说明:hbase的master节点和slave节点中都出现了QuorumPeerMain(就是zookeeper进程)而不是QuorumPeer进程,表示此时hbase使用的是独立的zookeeper。
查看状态
1 | ha-call.sh "jps" |
访问
HMaster 的 Web 接口
HRegionServer 的 Web 接口
管理工具虽然比较简单,但是可以查看集群的一些状态信息
- HBase 的版本信息
- HBase 的基本配置信息
- HBase 在 HDFS 中的存储路径
- Zookeeper 的节点
- 集群的负载信息
- 表、region 和 region server 的信息
- 可以进行 compat 和 split 操作
报错
Exception in thread “main” java.lang.NoClassDefFoundError: org/apache/htrace/core/HTraceConfiguration
更换为2.1.10解决了,高版本缺少jar
ERROR [main] zookeeper.RecoverableZooKeeper: ZooKeeper exists failed after 4 attempts
解决方法
Centos上
1 | netstat -aon|grep "2181" |
Win上
1 | netstat -aon|findstr "2181" |
HBase的操作
下面的操作主要是在hbase的shell中操作的,进入hbase shell
1 | hbase shell |
创建表
1 | create 'student','s_name','s_sex','s_age','s_dept','s_course' |
查看表详情
1 | describe 'student' |
显示所有的表
1 | list |
插入数据
1 | put 'student','95001','s_name','LiYing' |
注意:一次只能为一个表的一行数据的一个列,也就是一个单元格添加一个数据,所以直接用shell命令插入数据效率很低,在实际应用中,一般都是利用编程操作数据。
当运行命令:
put ‘student’,’95001’,’s_name’,’LiYing’时,即为student表添加了学号为95001,名字为LiYing的一行数据,其行键为95001。
查询数据 HBase中有两个用于查看数据的命令:
- get命令,用于查看表的某一行数据;
- scan命令用于查看某个表的全部数据
示例
1 | get 'student','95001' |
删除数据 在HBase中用delete以及deleteall命令进行删除数据操作,它们的区别是: ① delete用于删除一个数据,是put的反向操作; ② deleteall操作用于删除一行数据。
1 | delete 'student','95001','s_sex' |
修改数据 在添加数据时,HBase会自动为添加的数据添加一个时间戳,故在需要修改数据时,只需直接添加数据,HBase即会生成一个新的版本,从而完成“改”操作,旧的版本依旧保留,系统会定时回收垃圾数据,只留下最新的几个版本,保存的版本数可以在创建表的时候指定。下面是一个操作的例子:
1 | hbase(main):034:0> get 'student','95001' |
删除表 删除表有两步,第一步先让该表不可用,第二步删除表。直接drop未disable的表会失败。
1 | disable 'student' |
查询历史的表
1 | create 'teacher',{NAME=>'username',VERSIONS=>5} |
退出hbase
1 | exit |
兼容性
兼容性
JDK兼容性
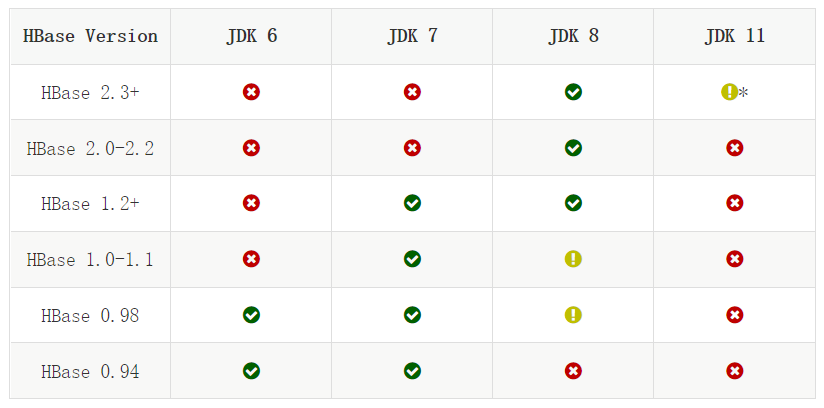
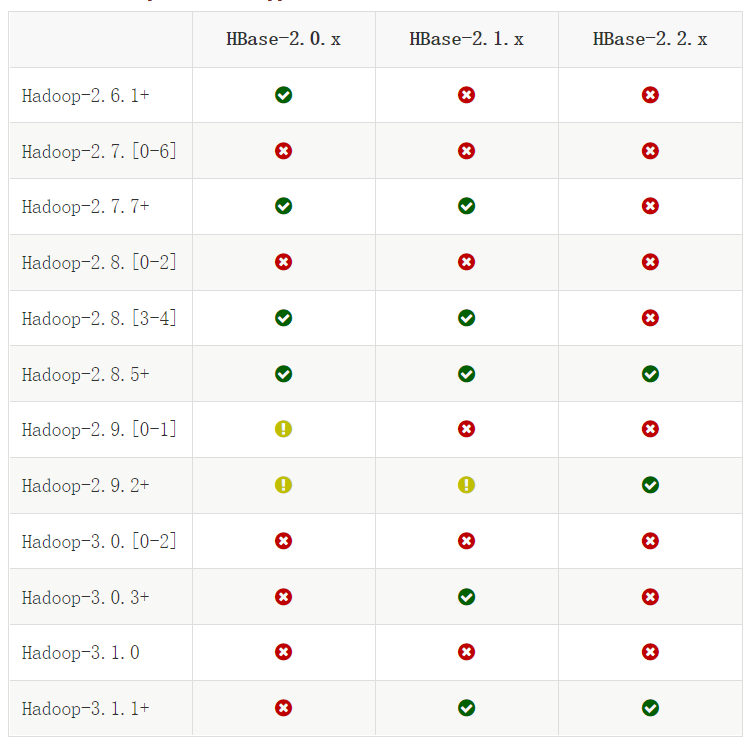
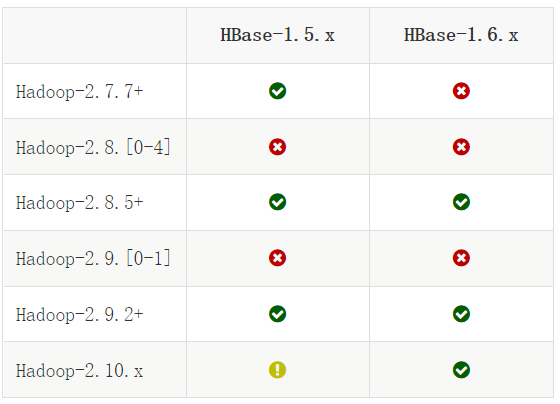
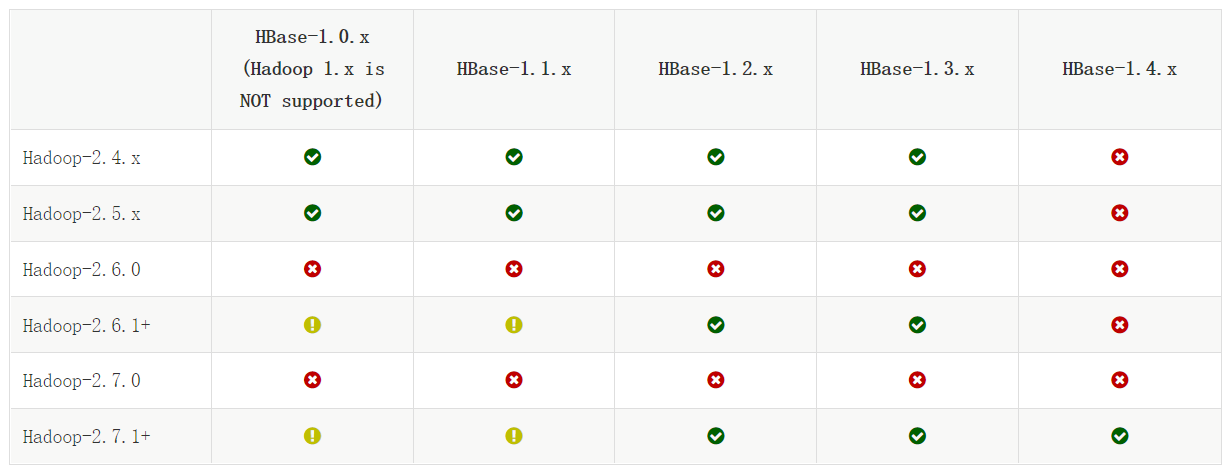
Hadoop兼容性
https://hbase.apache.org/book.html#hadoop
Hbase与 Zookeeper 的关系
HBase 主要用ZooKeeper来实现 HA 选举与主备集群主节点的切换、系统容错、meta-region 管理、Region 状态管理和分布式 SplitWAL 任务管理等。
Windows上安装注意点
Could not initialize class org.fusesource.jansi.internal.Kernel32
Hbase在Windows上安装是非常不顺利的
问题1 无法运行
版本上
1.x 安装配置后能够直接运行 但是开发时SBT无法下载依赖
2.x 安装后默认缺少依赖,需要把缺少的jar放到lib目录中