Windows环境 下载地址
链接:https://pan.baidu.com/s/1YczOo5novINV_MimJ9Xpqg
版本
名称
版本
Hadoop
2.7.7
Scala
2.12.15
Spark
3.1.3
Hadoop https://archive.apache.org/dist/hadoop/common/hadoop-2.7.7/
配置HADOOP_HOME&Path
键
值
HADOOP_HOME
D:\Tools\bigdata\hadoop-2.7.7
Path
%HADOOP_HOME%\bin
配置文件 首选创建三个文件夹
D:\Tools\bigdata\zdata\hadoop\data
D:\Tools\bigdata\zdata\hadoop\name
D:\Tools\bigdata\zdata\hadoop\tmp
D:\Tools\bigdata\hadoop-2.7.7\etc\hadoop,修改hadoop以下的几个文件
hadoop-env.cmd
1 set JAVA_HOME="D:\Tools\Java\jdk1.8.0_102"
修改core-site.xml
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 <?xml version="1.0" encoding="UTF-8" ?> <?xml-stylesheet type="text/xsl" href="configuration.xsl" ?> <configuration > <property > <name > hadoop.tmp.dir</name > <value > /D:/Tools/bigdata/zdata/hadoop/tmp</value > <description > </description > </property > <property > <name > fs.defaultFS</name > <value > hdfs://localhost:9000</value > <description > </description > </property > </configuration >
修改hdfs-site.xml
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 <?xml version="1.0" encoding="UTF-8" ?> <?xml-stylesheet type="text/xsl" href="configuration.xsl" ?> <configuration > <property > <name > dfs.replication</name > <value > 1</value > <description > </description > </property > <property > <name > dfs.data.dir</name > <value > /D:/Tools/bigdata/zdata/hadoop/data</value > <description > </description > </property > <property > <name > dfs.name.dir</name > <value > /D:/Tools/bigdata/zdata/hadoop/name</value > <description > </description > </property > </configuration >
修改mapred-site.xml(如果不存在就先copy mapred-site.xml.template,再修改文件名为mapred-site.xml)
1 2 3 4 5 6 7 8 9 10 11 12 13 <?xml version="1.0" ?> <?xml-stylesheet type="text/xsl" href="configuration.xsl" ?> <configuration > <property > <name > mapreduce.framework.name</name > <value > yarn</value > </property > <property > <name > mapred.job.tracker</name > <value > hdfs://localhost:9001</value > </property > </configuration >
修改yarn-site.xml
1 2 3 4 5 6 7 8 9 10 11 12 <?xml version="1.0" ?> <configuration > <property > <name > yarn.nodemanager.aux-services</name > <value > mapreduce_shuffle</value > </property > <property > <name > yarn.nodemanager.aux-services.mapreduce.shuffle.class</name > <value > org.apache.hadoop.mapred.ShuffleHandler</value > </property > </configuration >
winutils https://gitee.com/nkuhyx/winutils
找到对应的版本把bin里的文件覆盖到hadoop的bin目录下
D:\Tools\bigdata\hadoop-2.7.7\bin
启动 环境变量中Path添加
1 2 3 D:\Tools\Java\jdk1.8.0_102\bin D:\Tools\bigdata\hadoop-2.7.7\bin D:\Tools\bigdata\hadoop-2.7.7\sbin
注意
建议Java安装路径中不包含空格或中文,负责可能运行报错。
namenode格式化
出现以下文字则成功了
hdfs namenode -format
全部服务
1 2 start-all.cmd stop-all.cmd
只启动HDFS
1 2 start-dfs.cmd stop-dfs.cmd
地址
Scala 下载
https://www.scala-lang.org/download/2.12.15.html
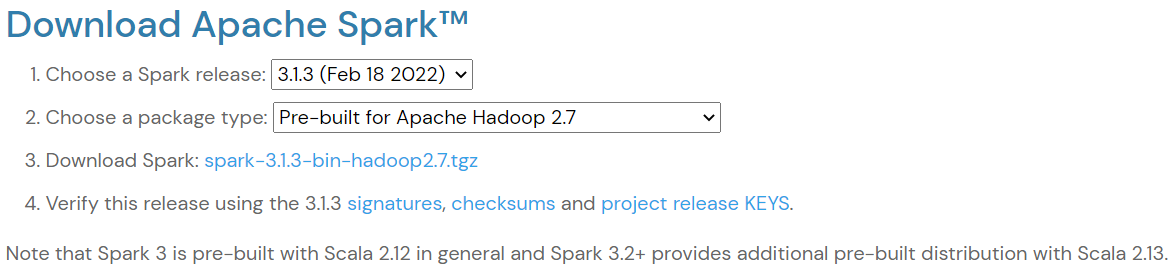
Spark https://spark.apache.org/downloads.html
下载地址
https://dlcdn.apache.org/spark/spark-3.1.3/spark-3.1.3-bin-hadoop2.7.tgz
设置环境变量
Path中添加
键
值
Path
D:\Tools\bigdata\spark-3.1.3-bin-hadoop2.7\bin
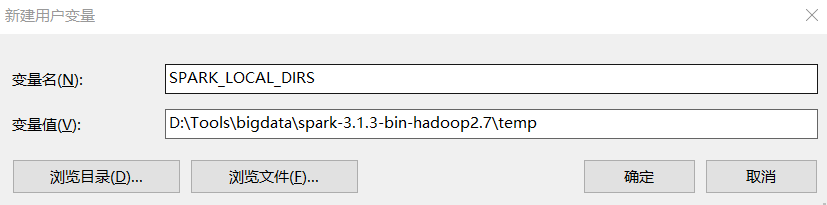
SPARK_LOCAL_DIRS
D:\Tools\bigdata\spark-3.1.3-bin-hadoop2.7\temp
如图
其中
SPARK_LOCAL_DIRS 是设置临时文件的存储位置,比如运行一个jar文件,就会先把文件放到这个临时目录中,使用完成后再删除。
运行
运行报错
java.io.IOException: Failed to delete
当我们提交打包好的spark程序时提示如上报错。
在windows环境下本身就存在这样的问题,和我们的程序没有关系。
若是想消除该报错,可以在%SPARK_HOME%/conf下的文件log4j.properties(没有的话可以复制log4j.properties.template文件)
最后面添加如下信息:
1 2 log4j.logger.org.apache.spark.util.ShutdownHookManager=OFF log4j.logger.org.apache.spark.SparkEnv=ERROR
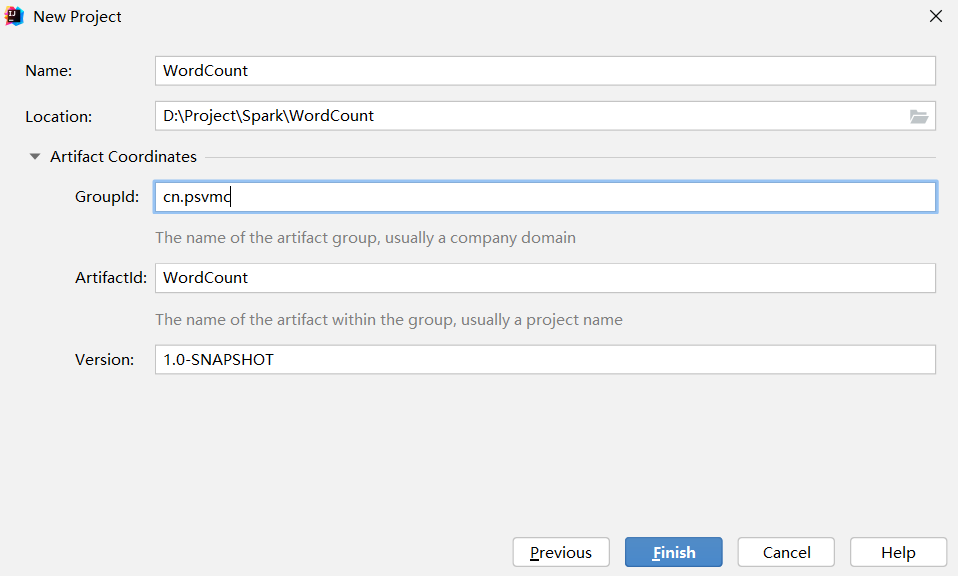
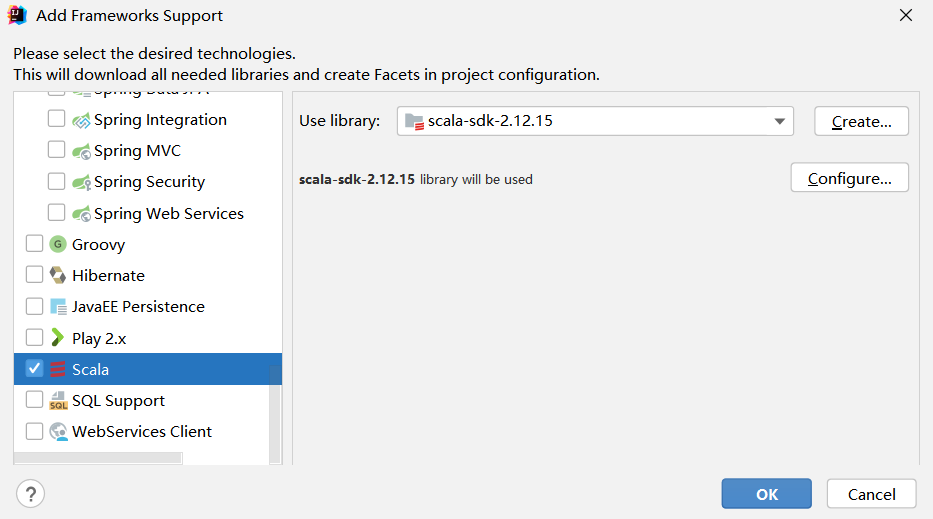
创建项目 创建项目
项目名WordCount
在项目名称WordCount上单击鼠标右键,在弹出的菜单中点击Add Framework Support
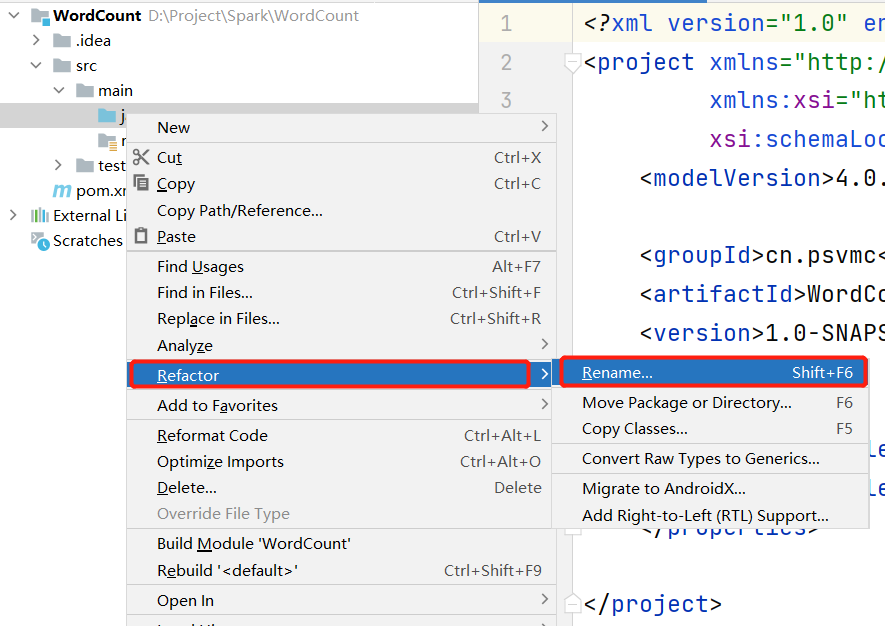
在java目录上单击鼠标右键,在弹出的菜单中选择Refactor,再在弹出的菜单中选择Rename,
然后,在出现的界面中把java目录名称修改为scala。
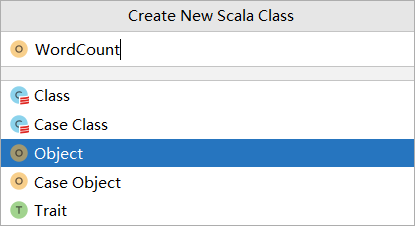
添加类WordCount
在IDEA开发界面中,打开pom.xml,清空里面的内容,输入如下内容:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 <?xml version="1.0" encoding="UTF-8" ?> <project xmlns ="http://maven.apache.org/POM/4.0.0" xmlns:xsi ="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation ="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd" > <modelVersion > 4.0.0</modelVersion > <groupId > cn.psvmc</groupId > <artifactId > WordCount</artifactId > <version > 1.0</version > <properties > <maven.compiler.source > 8</maven.compiler.source > <maven.compiler.target > 8</maven.compiler.target > <spark.version > 3.1.3</spark.version > <scala.version > 2.12</scala.version > </properties > <repositories > <repository > <id > alimaven</id > <name > aliyun maven</name > <url > http://maven.aliyun.com/nexus/content/groups/public/</url > </repository > </repositories > <dependencies > <dependency > <groupId > org.apache.spark</groupId > <artifactId > spark-core_${scala.version}</artifactId > <version > ${spark.version}</version > </dependency > </dependencies > <build > <plugins > <plugin > <groupId > net.alchim31.maven</groupId > <artifactId > scala-maven-plugin</artifactId > <version > 3.4.6</version > <executions > <execution > <goals > <goal > compile</goal > </goals > </execution > </executions > </plugin > <plugin > <groupId > org.apache.maven.plugins</groupId > <artifactId > maven-assembly-plugin</artifactId > <version > 3.0.0</version > <configuration > <descriptorRefs > <descriptorRef > jar-with-dependencies</descriptorRef > </descriptorRefs > </configuration > <executions > <execution > <id > make-assembly</id > <phase > package</phase > <goals > <goal > single</goal > </goals > </execution > </executions > </plugin > </plugins > </build > </project >
测试 创建测试文件wordcount.txt
D:\spark_study\wordcount.txt
1 2 good good study day day up
然后,再打开WordCount.scala代码文件,清空里面的内容,输入如下内容:
1 2 3 4 5 6 7 8 9 10 11 12 import org.apache.spark.{SparkConf , SparkContext }object WordCount def main Array [String ]): Unit = { val inputFile = "file:///D:\\spark_study\\wordcount.txt" val conf = new SparkConf ().setAppName("WordCount" ).setMaster("local" ) val sc = new SparkContext (conf) val textFile = sc.textFile(inputFile) val wordCount = textFile.flatMap(line => line.split(" " )).map(word => (word, 1 )).reduceByKey((a, b) => a + b) wordCount.foreach(println) } }
运行就可以看到结果为
(up,1)
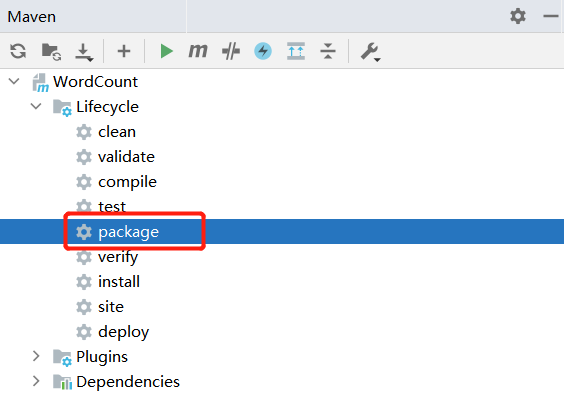
打包运行 在IDEA开发界面的右侧,点击Maven图标,会弹出Maven调试界面
在Maven调试界面中点击package,就可以对应用程序进行打包,打包成JAR包。
这时,到IDEA开发界面左侧的项目目录树中,在“target”目录下,就可以看到生成了两个JAR文件,
分别是:WordCount-1.0.jar和WordCount-1.0-jar-with-dependencies.jar。
然后,打开一个Linux终端,执行如下命令运行JAR包:
1 spark-submit --class WordCount D:\Project\Spark\WordCount\target\WordCount-1.0-jar-with-dependencies.jar