大数据环境搭建-Zookeeper安装与运行
安装Zookeeper
kafka依赖zookeeper,安装包内已内置 使用内置的可以跳过该步骤
也可自己单独下载
https://zookeeper.apache.org/releases.html#download
我这里下载的是apache-zookeeper-3.7.1-bin.tar.gz
解压
1 | tar -zxvf apache-zookeeper-3.7.1-bin.tar.gz -C /data/tools/bigdata/ |
环境变量
Windows环境
注意要设置JAVA_HOME
| 名称 | 路径 |
|---|---|
| JAVA_HOME | D:\Program Files\Java\jdk1.8.0_102 |
| ZK_HOME | D:\Tools\BigData\apache-zookeeper-3.7.1-bin |
| Path | %ZK_HOME%\bin |
conf配置目录下的zoo_sample.cfg修改为zoo.cfg
配置环境变量
添加环境变量
1 | cd /etc/profile.d/ |
创建配置文件
1 | vi /etc/profile.d/zk.sh |
加入:
1 | export ZK_HOME=/data/tools/bigdata/apache-zookeeper-3.7.1-bin |
配置立即生效
1 | source /etc/profile |
查看ZK_HOME
1 | echo $ZK_HOME |
单机启动ZK
以下在Windows下测试的。
启动ZK
1 | %ZK_HOME%/bin/zkServer.cmd |
进入
1 | %ZK_HOME%/bin/zkCli.cmd |
输入命令
1 | #查看zk的根目录kafka相关节点 |
常用命令
- 显示根目录下文件:
ls /使用 ls 命令来查看当前 ZooKeeper 中所包含的内容 - 显示根目录下文件:
ls2 /查看当前节点数据并能看到更新次数等数据 - 创建文件,并设置初始内容:
create /zk "test"创建一个新的 znode节点“ zk ”以及与它关联的字符串 - 获取文件内容:
get /zk确认 znode 是否包含我们所创建的字符串 - 修改文件内容:
set /zk "zkbak"对 zk 所关联的字符串进行设置 - 删除文件:
delete /zk将刚才创建的 znode 删除 - 退出客户端:
quit - 帮助命令:
help
集群
集群最少为3个。
配置修改
conf配置目录下的zoo_sample.cfg修改为zoo.cfg
修改
1 | dataDir=/data/tools/bigdata/zdata/zk_data |
添加
1 | # server.1 这个1是服务器的标识,可以是任意有效数字,标识这是第几个服务器节点,这个标识要写到dataDir目录下面myid文件里 |
创建目录
1 | ha-call.sh "mkdir -p /data/tools/bigdata/zdata/zk_data" |
如果要重置清空数据
1 | ha-call.sh "rm -rf /data/tools/bigdata/zdata/zk_data/*" |
分别在三台主机的 dataDir 目录下新建 myid 文件,并写入对应的节点标识。
Zookeeper 集群通过 myid 文件识别集群节点,并通过上文配置的节点通信端口和选举端口来进行节点通信,选举出 Leader 节点。
创建并写入节点标识到 myid 文件:
1 | ssh hadoop01 "echo 1 > /data/tools/bigdata/zdata/zk_data/myid" |
配置分发
1 | ha-fenfa.sh $ZK_HOME |
启动ZK
所有服务器上运行
启动ZK
1 | bash $ZK_HOME/bin/zkServer.sh start |
查看状态
1 | zkServer.sh status |
或者
用自定义脚本
1 | ha-zk.sh start |
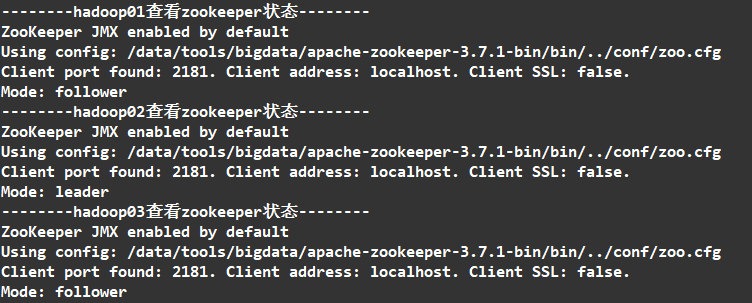
全部启动成功后我们可以看到
1个leader,2个follower,就说明集群配置成功了。
访问
进入
1 | bash $ZK_HOME/bin/zkCli.sh |
输入命令
1 | #查看zk的根目录kafka相关节点 |
使用到的端口
搭建集群时配置文件zoo.cfg中会出现这样的配置
1 | clientPort=2181 |
其中
2181:Client使用
2888:集群内部通讯使用(Leader监听此端口)
3888:选举Leader使用
Zookeeper客户端
https://github.com/vran-dev/PrettyZoo/releases/
百度云下载