Scala语言入门
前言
学习Scala之前我们先看一个简单的例子
Java
1 | List<Product> products = new ArrayList<Product>(); |
Scala 的:
1 | def products = orders.flatMap(o => o.products) |
甚至可以更简洁:
1 | def products = orders.flatMap(_.products) |
这样我们就可以看出Scala可以写更少的代码来实现同样的功能。
下载
下载
https://www.scala-lang.org/download/2.12.15.html
或者
下载地址
链接:https://pan.baidu.com/s/1YczOo5novINV_MimJ9Xpqg
提取码:psvm

注意安装路径不能有空格否则报错
此时不应有 \scala\bin..\lib\jline-3.21.0.jar。
测试是否可用
1 | scala -version |
IDEA安装插件
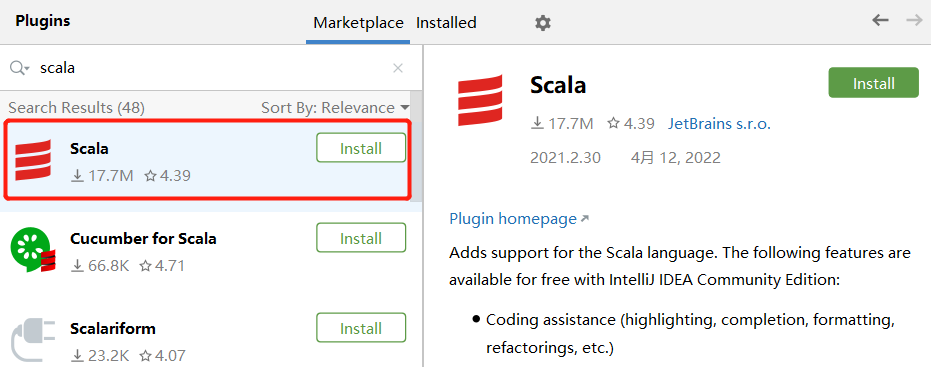
安装后重启IDEA
创建项目
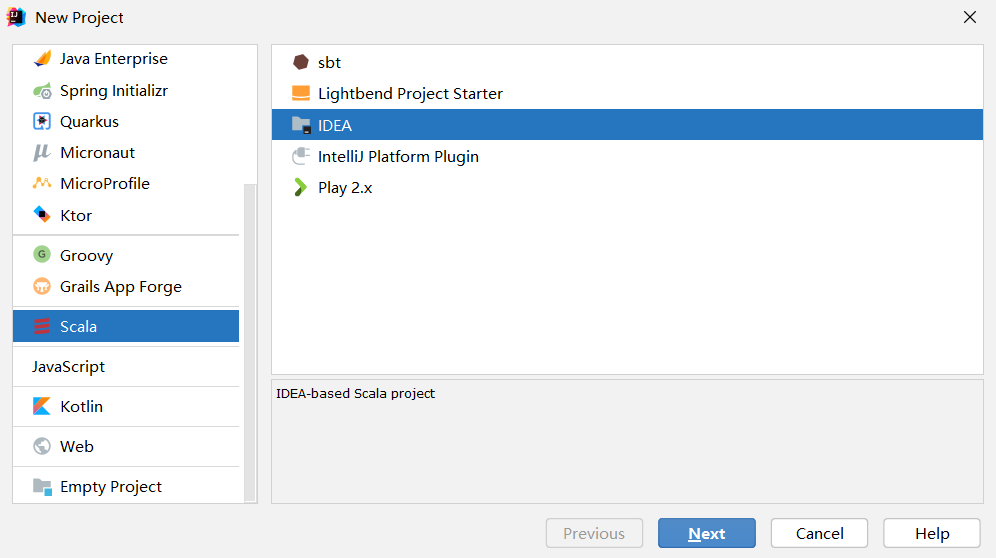
项目上右键
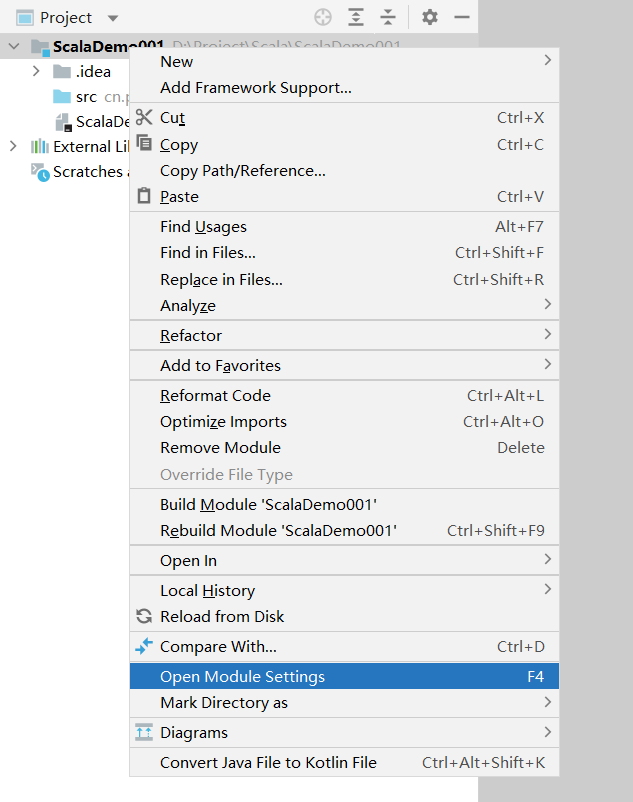
添加Scala SDK
添加我们的测试类
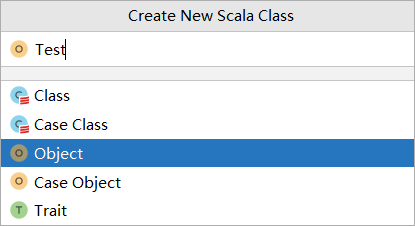
代码如下
1 | package cn.psvmc |
语法
Array
数组是编程中经常用到的数据结构,一般包括定长数组和变长数组。本教程旨在快速掌握最基础和常用的知识,因此,只介绍定长数组。
定长数组,就是长度不变的数组,在Scala中使用Array进行声明,如下:
1 | val intValueArr = new Array[Int](3) //声明一个长度为3的整型数组,每个数组元素初始化为0 |
需要注意的是,在Scala中,对数组元素的应用,是使用圆括号,而不是方括号,也就是使用intValueArr(0),而不是intValueArr[0],这个和Java是不同的。
下面我们再声明一个字符串数组,如下:
1 | val myStrArr = new Array[String](3) //声明一个长度为3的字符串数组,每个数组元素初始化为null |
实际上,Scala提供了更加简洁的数组声明和初始化方法,如下:
1 | val intValueArr = Array(12,45,33) |
从上面代码可以看出,都不需要给出数组类型,Scala会自动根据提供的初始化数据来推断出数组的类型。
List
1 | val intList = List(1,2,3) |
列表有头部和尾部的概念,可以使用intList.head来获取上面定义的列表的头部,值是1,使用intList.tail来获取上面定义的列表的尾部,值是List(2,3),可以看出,头部是一个元素,而尾部则仍然是一个列表。
由于列表的头部是一个元素,所以,我们可以使用::操作,在列表的头部增加新的元素,得到一个新的列表,如下:
1 | val intList = List(1,2,3) |
注意,上面操作执行后,intList不会发生变化,依然是List(1,2,3),intListOther是一个新的列表List(0,1,2,3)
::操作符是右结合的,因此,如果要构建一个列表List(1,2,3),实际上也可以采用下面的方式:
1 | val intList = 1::2::3::Nil |
上面代码中,Nil表示空列表。
我们也可以使用:::操作符对不同的列表进行连接得到新的列表,比如:
1 | val intList1 = List(1,2) |
注意,执行上面操作后,intList1和intList2依然存在,intList3是一个全新的列表。
实际上,Scala还为列表提供了一些常用的方法,比如,如果要实现求和,可以直接调用sum方法,如下:
1 | object Scala01 { |
map
1 | val books = List("Hadoop", "Hive", "HDFS") |
结果
1 | List(HADOOP, HIVE, HDFS) |
flatMap
1 | val books = List("Hadoop", "Hive", "HDFS") |
结果
1 | List(H, A, D, O, O, P, H, I, V, E, H, D, F, S) |
flatMap把这些集合中的元素“拍扁”得到一个集合List
filter
1 | val books = List("Hadoop", "Hive", "HDFS") |
结果
1 | List(Hadoop) |
reduce
1 | val list = List(1, 2, 3, 4, 5) |
reduce和reduceLeft计算的方式是一致的
reduceLeft
1 | 1+2 = 3 |
reduceRight
1 | 4+5 = 9 |
flod
1 | val list = List(1, 2, 3, 4, 5) |
结果
1 | 25 |
fold函数实现了对list中所有元素的累计操作。
fold函数需要两个参数,一个参数是初始种子值,这里是10,另一个参数是用于计算结果的累计函数,这里是累加。
执行list.fold(10)(_ + _)时,首先把初始值拿去和list中的第一个值1做加法操作,得到值11,然后再拿这个值11去和list中的第2个值2做加法操作,得到13,依此类推,一直得到最终的结果25。
Tuple
元组是不同类型的值的聚集。元组和列表不同,列表中各个元素必须是相同类型,而元组可以包含不同类型的元素。
下面我们声明一个名称为tuple的元组(为了看到声明后的效果,我们这次在Scala解释器中输入代码并执行):
1 | val tuple = ("BigData",2015,45.0) |
从上述代码在Scala解释器中的执行效果可以看出,我们声明一个元组是很简单的,只需要用圆括号把多个元组的元素包围起来就可以了。
当需要访问元组中的某个元素的值时,可以通过类似tuple._1、tuple._2、tuple._3这种方式就可以实现。
Set
集(set)是不重复元素的集合。
列表中的元素是按照插入的先后顺序来组织的,但是,”集”中的元素并不会记录元素的插入顺序,而是以“哈希”方法对元素的值进行组织,所以,它允许你快速地找到某个元素。
集包括可变集和不可变集,缺省情况下创建的是不可变集,通常我们使用不可变集。
下面我们用默认方式创建一个不可变集,如下:
1 | var mySet = Set("Hadoop", "Spark") |
上面声明时,如果使用val,mySet += "Scala"执行时会报错,所以需要声明为var。
如果要声明一个可变集,则需要引入scala.collection.mutable.Set包,具体如下:
1 | import scala.collection.mutable.Set |
上面代码中,我们声明myMutableSet为val变量(不是var变量),由于是可变集,因此,可以正确执行myMutableSet += "Cloud Computing",不会报错。
注意:
虽然可变集和不可变集都有添加或删除元素的操作,但是,二者有很大的区别。
对不可变集进行操作,会产生一个新的集,原来的集并不会发生变化。
而对可变集进行操作,改变的是该集本身,
Map
在Scala中,映射(Map)是一系列键值对的集合,也就是,建立了键和值之间的对应关系。在映射中,所有的值,都可以通过键来获取。
映射包括可变和不可变两种,默认情况下创建的是不可变映射,如果需要创建可变映射,需要引入scala.collection.mutable.Map包。
下面我们创建一个不可变映射:
1 | val university = Map("XMU" -> "Xiamen University", "THU" -> "Tsinghua University","PKU"->"Peking University") |
如果要获取映射中的值,可以通过键来获取,如下:
1 | println(university("XMU")) |
上面代码通过”XMU”这个键,可以获得值Xiamen University。
如果要检查映射中是否包含某个值,可以使用contains方法,如下:
1 | val xmu = if (university.contains("XMU")) university("XMU") else 0 |
循环遍历
1 | for ((k,v) <- university) { |
我们只想把所有键打印出来:
1 | for (k<-university.keys) println(k) |
再比如说,我们只想把所有值打印出来:
1 | for (v<-university.values) println(v) |
filter
1 | val university = Map( |
结果
1 | Map(XMU -> Xiamen University, XMUT -> Xiamen University of Technology) |
Iterator
在Scala中,迭代器(Iterator)不是一个集合,但是,提供了访问集合的一种方法。
当构建一个集合需要很大的开销时(比如把一个文件的所有行都读取内存),迭代器就可以发挥很好的作用。
迭代器包含两个基本操作:next和hasNext。next可以返回迭代器的下一个元素,hasNext用于检测是否还有下一个元素。
有了这两个基本操作,我们就可以顺利地遍历迭代器中的所有元素了。
通常可以通过while循环或者for循环实现对迭代器的遍历。
while循环如下:
1 | val iter = Iterator("Hadoop","Spark","Scala") |
注意,上述操作执行结束后,迭代器会移动到末尾,就不能再使用了,如果继续执行一次println(iter.next)就会报错。另外,上面代码中,使用iter.next和iter.next()都是可以的,但是hasNext后面不能加括号。
for循环如下:
1 | val iter = Iterator("Hadoop","Spark","Scala") |
遍历
1 | object Test { |
模式匹配
Java中有switch-case语句,但是,只能按顺序匹配简单的数据类型和表达式。相对而言,Scala中的模式匹配的功能则要强大得多,可以应用到switch语句、类型检查、“解构”等多种场合。
简单匹配
Scala的模式匹配最常用于match语句中。下面是一个简单的整型值的匹配实例。
1 | val colorNum = 1 |
为了测试上面代码,可以直接把上面代码放入到“/usr/local/scala/mycode/test.scala”文件中,然后,在Linux系统的Shell命令提示符状态下执行下面命令:
1 | scala test.scala |
Shell 命令
另外,在模式匹配的case语句中,还可以使用变量。
1 | val colorNum = 4 |
按照前面给出的方法,在test.scala文件中测试执行上述代码后会在屏幕上输出:
1 | 4 is Not Allowed |
也就是说,当colorNum=4时,值4会被传递给unexpected变量。
类型模式
Scala可以对表达式的类型进行匹配。
1 | for (elem <- List(9,12.3,"Spark","Hadoop",'Hello)){ |
在test.scala文件中测试执行上述代码后会在屏幕上输出:
1 | 9 is an int value. |
守卫语句
可以在模式匹配中添加一些必要的处理逻辑。
1 | for (elem <- List(1, 2, 3, 4)) { |
上面代码中if后面条件表达式的圆括号可以不要。执行上述代码后可以得到以下输出结果:
1 | 1 is odd. |
for表达式中的模式
我们之前在介绍“映射”的时候,实际上就已经接触过了for表达式中的模式。
还是以我们之前举过的映射为例子,我们创建的映射如下:
1 | val university = Map("XMU" -> "Xiamen University", "THU" -> "Tsinghua University","PKU"->"Peking University") |
循环遍历映射的基本格式是:
1 | for ((k,v) <- 映射) 语句块 |
对于遍历过程得到的每个值,都会被绑定到k和v两个变量上,也就是说,映射中的“键”被绑定到变量k上,映射中的“值”被绑定到变量v上。
下面给出此前已经介绍过的实例:
1 | for ((k,v) <- university) printf("Code is : %s and name is: %s\n",k,v) |
上面代码执行结果如下:
1 | Code is : XMU and name is: Xiamen University |
case类的匹配
case类是一种特殊的类,它们经过优化以被用于模式匹配。
1 | case class Car(brand: String, price: Int) |
把上述代码放入test.scala文件中,运行“scala test.scala”命令执行后可以得到如下结果:
1 | Hello, BYD! |
Option类型
标准类库中的Option类型用case类来表示那种可能存在、也可能不存在的值。
一般而言,对于每种语言来说,都会有一个关键字来表示一个对象引用的是“无”,在Java中使用的是null。
Scala融合了函数式编程风格,因此,当预计到变量或者函数返回值可能不会引用任何值的时候,建议你使用Option类型。
Option类包含一个子类Some,当存在可以被引用的值的时候,就可以使用Some来包含这个值,例如Some(“Hadoop”)。
而None则被声明为一个对象,而不是一个类,表示没有值。
下面我们给出一个实例。
1 | val books = Map("hadoop" -> 5, "spark" -> 10, "hbase" -> 7) |
结果
1 | (Some,5) |
Option类型还提供了getOrElse方法,这个方法在这个Option是Some的实例时返回对应的值,而在是None的实例时返回传入的参数。例如:
1 | val books = Map("hadoop" -> 5, "spark" -> 10, "hbase" -> 7) |
结果
1 | 5 |
可以看出,当我们采用getOrElse方法时,如果我们取的hive没有对应的值,我们就可以显示我们指定的No Such Book,而不是显示None。
在Scala中,使用Option的情形是非常频繁的。
在Scala里,经常会用到Option[T]类型,其中的T可以是Sting或Int或其他各种数据类型。
Option[T]实际上就是一个容器,我们可以把它看做是一个集合,只不过这个集合中要么只包含一个元素(被包装在Some中返回),要么就不存在元素(返回None)。
既然是一个集合,我们当然可以对它使用map、foreach或者filter等方法。比如:
1 | scala> books.get("hive").foreach(println) |
可以发现,上述代码执行后,屏幕上什么都没有显示,因为,foreach遍历遇到None的时候,什么也不做,自然不会执行println操作。
类与对象
get/set
1 | class User { |
测试
1 | object Test { |
构造器
1 | class User { |
测试
1 | object Test { |
单例
1 | object IDGenerator { |
测试
1 | object Test { |