大数据环境搭建-Hadoop与Spark
前言
本文环境软件版本
| 名称 | 版本 |
|---|---|
| JDK | 1.8.0_221 |
| Scala | 2.12.15 |
| Spark | 3.1.3 |
| Hadoop | 2.7.7 |
注意
一定要保证开发环境和部署的环境保持一致!否则运行时会报各种错误。
基础环境配置
https://www.psvmc.cn/article/2022-03-31-bigdata-environment.html
Hadoop
官网:https://hadoop.apache.org/releases.html
下载
https://archive.apache.org/dist/hadoop/common/hadoop-2.7.7/
服务器中运行
1 | wget https://archive.apache.org/dist/hadoop/common/hadoop-2.7.7/hadoop-2.7.7.tar.gz |
或者使用百度云下载
链接:https://pan.baidu.com/s/1OPzD9V_mBnBz06JQ3X5DSA
提取码:psvm
解压
1 | tar -zxvf hadoop-2.7.7.tar.gz |
配置环境变量
1 | cd /etc/profile.d/ |
创建配置文件
1 | vi /etc/profile.d/my_env.sh |
内容设置为
1 | #HADOOP_HOME |
配置生效
1 | source /etc/profile |
查看是否生效
1 | echo $HADOOP_HOME |
修改配置文件
注意
本文是伪分布式部署
进入配置文件目录
1 | cd /data/tools/bigdata/hadoop-2.7.7/etc/hadoop |
hadoop-env.sh
将原本的JAVA_HOME 替换为绝对路径就可以了
1 | #export JAVA_HOME=${JAVA_HOME} |
注意
虽然系统已经设置
JAVA_HOME,但是运行时依旧无法找到,所以配置的绝对路径
core-site.xml
1 |
|
hdfs-site.xml
1 |
|
mapred-site.xml
1 |
|
yarn-site.xml
1 |
|
剔除警告(可选):
log4j.properties
添加
1 | log4j.logger.org.apache.hadoop.util.NativeCodeLoader=ERROR |
启动/停止
1 | sudo chmod -R 755 $HADOOP_HOME |
这个操作主要是创建fsimage和edits文件。
只要看到信息中有一句关键:
INFO common.Storage: Storage directory /data/tools/bigdata/hadoop-2.7.7/tmp/dfs/name has been successfully formatted.
则格式化成功.
运行
1 | sh $HADOOP_HOME/sbin/start-all.sh |
输入
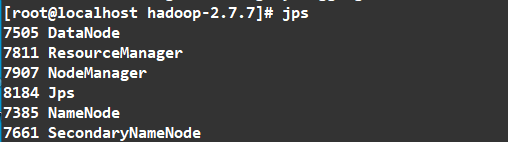
1 | jps |
如图
访问
我的服务器的IP为 192.168.7.101
HDFS监控页面查询:
查看文件可以访问这个地址
http://192.168.7.101:50070/explorer.html#/
Yarn监控页面查询:
http://192.168.7.101:8088/cluster
停止
1 | sh $HADOOP_HOME/sbin/stop-all.sh |
端口说明:
| 端口 | 作用 |
|---|---|
| 8088 | cluster and all applications |
| 50070 | Hadoop NameNode |
| 50090 | Secondary NameNode |
| 50075 | DataNode |
停止所有服务
1 | sh $HADOOP_HOME/sbin/stop-all.sh |
测试
1 | mkdir -p /data/hadooptest/input |
随便添加一些文本
1 | 1111 |
复制文件到hadoop中
1 | hadoop fs -mkdir /data/ |
测试
1 | cd /data/tools/bigdata/hadoop-2.7.7 |
结果
它就把统计给生成了

注册为服务
添加服务
1 | cd /etc/init.d |
内容如下:
1 |
|
注意
路径要使用完整路径,不能使用类似于
$HADOOP_HOME/sbin/stop-all.sh的路径。
赋予权限
1 | sudo chmod +x hadoop |
设置开机启动
1 | sudo chkconfig --add hadoop |
启动服务
1 | service hadoop start |
查看hadoop服务
1 | chkconfig --list hadoop |
安装Scala
https://www.scala-lang.org/download/2.12.15.html
链接:https://pan.baidu.com/s/16pVpTWrgg-NAfFXUw1nUQg
提取码:psvm
tgz(推荐)
1 | tar zxvf scala-2.12.15.tgz |
环境变量
创建配置文件
1 | vi /etc/profile.d/my_env.sh |
内容设置为
1 | # Scala |
配置生效
1 | source /etc/profile |
查看是否生效
1 | echo $SCALA_HOME |
查看安装结果
1 | scala -version |
rpm
安装
1 | chmod 755 scala-2.12.15.rpm |
查看安装结果
1 | scala -version |
查看安装位置
1 | rpm -ql scala | more |
卸载
1 | rpm -e scala |
Spark
http://archive.apache.org/dist/spark/spark-3.1.3/
下载这个
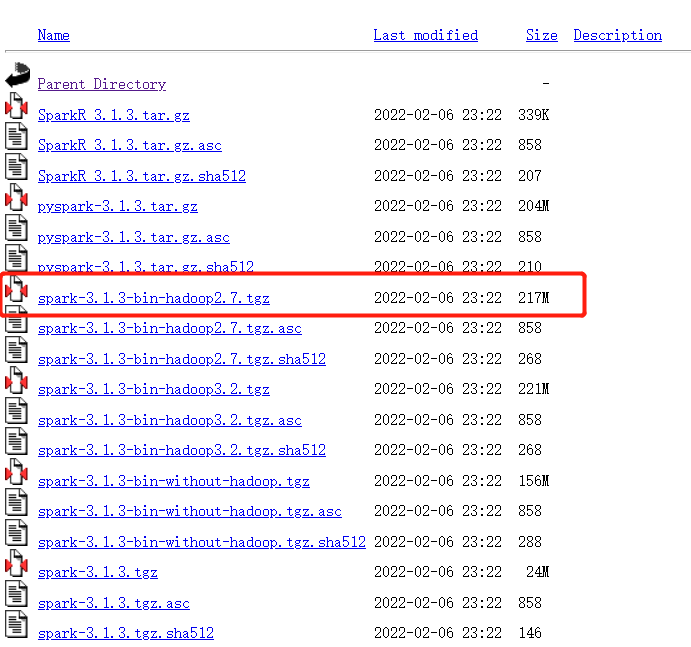
或者
链接:https://pan.baidu.com/s/1MdyzVWEhef6HheUVcymhcQ
提取码:psvm
解压
解压
1 | tar zxvf spark-3.1.3-bin-hadoop2.7.tgz |
进入conf目录,复制并重命名spark-env.sh.template、log4j.properties.template
1 | cd conf/ |
配置环境变量
修改环境变量
1 | cd /etc/profile.d/ |
创建配置文件
1 | vi /etc/profile.d/my_env.sh |
内容设置为
1 | # JAVA |
配置生效
1 | source /etc/profile |
查看是否生效
1 | echo $SPARK_HOME |
启动
启动spark
1 | cd /data/tools/bigdata/spark-3.1.3-bin-hadoop2.7 |
查看
1 | jps |
结果
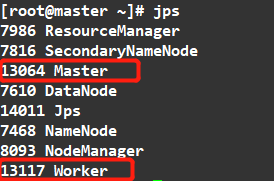
访问
相关端口
- Spark Master Web端口号:8080(类比于Hadoop的NameNode Web端口号:9870(50070))
- Spark Master内部通信服务端口号:7077 (类比于Hadoop(高版本)的8020(9000)端口)
- Spark历史服务器端口号:18080 (类比于Hadoop历史服务器端口号:19888)
- Spark查看当前Spark-shell运行任务情况端口号:4040
- Hadoop YARN任务运行情况查看端口号:8088
测试
1 | ./bin/spark-submit --class org.apache.spark.examples.SparkPi --master local[*] ./examples/jars/spark-examples_2.11-2.1.1.jar 100 |
结果
22/04/18 18:43:22 INFO DAGScheduler: Job 0 finished: reduce at SparkPi.scala:38, took 2.324649 s
Pi is roughly 3.141697114169711
注册为服务
添加服务
1 | cd /etc/init.d |
内容如下:
1 |
|
注意
路径要使用完整路径,不能使用类似于
$HADOOP_HOME/sbin/stop-all.sh的路径。
赋予权限
1 | sudo chmod +x spark |
设置开机启动
1 | sudo chkconfig --add spark |
启动服务
1 | service spark start |
查看hadoop服务
1 | chkconfig --list spark |