大数据集群基础环境搭建(Linux)
整体环境
服务器准备至少3台
1 | 192.168.7.101(hadoop01) |
服务器设置
系统中虚拟网卡设置

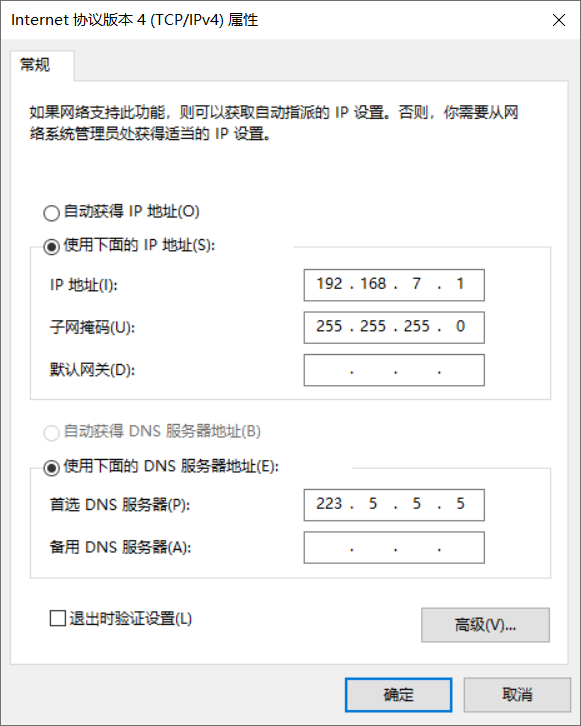
VMware中网络配置
注意网关要和上面的虚拟网卡一个段
编辑=>虚拟网络编辑器

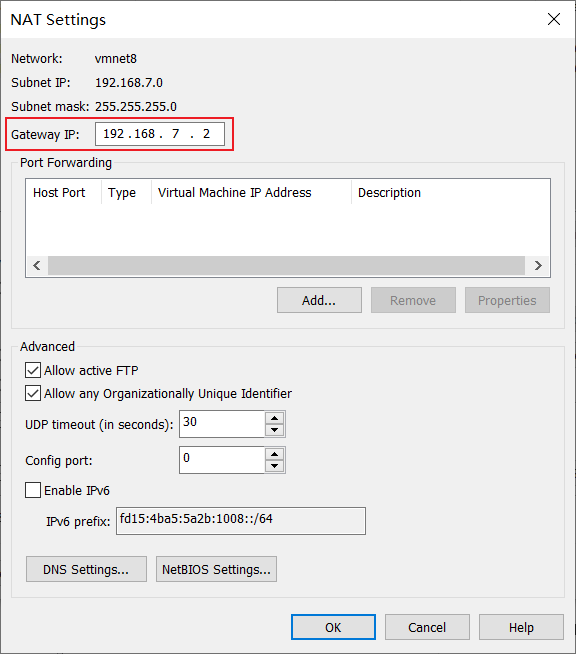
固定服务器IP
虚拟机中的IP要和VMware的下虚拟网络一个段,且网关为上面配置的网关
为了方便配置先设置为自动获取IP,使用SSH工具链接
进入到系统的IP地址保存文件所在目录
1 | cd /etc/sysconfig/network-scripts |
修改保存IP信息的文件
你机器上的名字有可能不是这个,但是是以ifcfg-e开头的文件
1 | vi ifcfg-ens33 |
修改
1 | ONBOOT=yes |
重启
1 | service network restart |
安装
1 | yum install -y net-tools |
查看IP 使用SSH工具连接
1 | ifconfig |
连接后修改网络配置
修改
1 | BOOTPROTO=dhcp |
为
1 | BOOTPROTO=static |
添加IP配置
1 | IPADDR=192.168.7.101 |
保存:wq
重启网络
1 | service network restart |
查看网络状态
1 | systemctl status network |
查看IP地址
1 | ip addr |
禁用NetworkManager
1 | systemctl stop NetworkManager |
注意:
这时候我们就可以使用SSH工具 如WinSCP进行登录了。
设置DNS服务器
1 | vi /etc/resolv.conf |
设置
1 | search localdomain |
注意
这里DNS服务器可以设置为网关的地址,也可以是公网的DNS服务器IP
关闭防火墙
查看防火墙状态
1 | systemctl status firewalld |
查看开机是否启动防火墙服务
1 | systemctl status firewalld |
关闭防火墙
1 | systemctl stop firewalld |
再次查看防火墙状态和开机防火墙是否启动
1 | systemctl status firewalld |
关闭selinux
临时关闭selinux(立即生效,重启服务器失效)
1 | setenforce 0 #临时关闭 |
永久生效
1 | vi /etc/selinux/config |
把
1 | SELINUX=enforcing |
改为
1 | SELINUX=disabled |
查看selinux状态
1 | getenforce |
状态
disabled为永久关闭,permissive为临时关闭,enforcing为开启
关闭THP服务
临时禁用THP服务
1 | echo never > /sys/kernel/mm/transparent_hugepage/enabled |
永久生效
关闭每台服务器的THP服务
1 | vi /etc/rc.local |
添加
1 | if test -f /sys/kernel/mm/transparent_hugepage/defrag; then |
查看
1 | cat /sys/kernel/mm/transparent_hugepage/enabled |
同步时间
注意
分布式部署必须设置。
配置
1 | yum install ntp -y |
添加任务
1 | crontab -e |
内容
1 | 0 * * * * /usr/sbin/ntpdate cn.pool.ntp.org |
在 hadoop02和 hadoop03上分别添加(ip为主节点的IP)
1 | vi /etc/ntp.conf |
配置为
1 | server 192.168.7.101 |
修改主机名
修改主机名(注意主机的hostname修改为不包含着. / _等非法字符。)
1 | hostnamectl set-hostname hadoop01 |
另两台
1 | hostnamectl set-hostname hadoop02 |
和
1 | hostnamectl set-hostname hadoop03 |
可以通过以下命令查看
1 | cat /etc/hostname |
修改Host文件
Linux
修改hosts文件
1 | vi /etc/hosts |
配置为
1 | 192.168.7.101 hadoop01 |
测试
1 | ping hadoop01 |
Windows
Windows下host文件配置
C:\Windows\System32\drivers\etc
添加如下
1 | 192.168.7.101 hadoop01 |
网络配置
修改/etc/sysconfig/network
1 | vi /etc/sysconfig/network |
内容
1 | NETWORKING=yes |
设置最大打开文件数
1 | ulimit -n 10000 |
(也可以弄个永久设置)
重新生效网络
1 | service network restart |
免密登陆
生成密钥对
1 | mkdir ~/.ssh |
在 hadoop01上修改文件权限
1 | chmod 700 ~/.ssh |
如果登录还是需要密码,可能是权限过大
Permissions 0644 for ‘/root/.ssh/id_rsa’ are too open.
设置文件权限
1 | chmod 0600 /root/.ssh/id_rsa |
登录 hadoop02,将公钥拷贝到 hadoop01的authorized_keys中
1 | ssh-copy-id -i hadoop01 |
登录 hadoop03,将公钥拷贝到 hadoop01的authorized_keys中
1 | ssh-copy-id -i hadoop01 |
重新进入hadoop01 在 hadoop01上将authorized_keys文件复制到其他机器
1 | scp /root/.ssh/authorized_keys root@hadoop02:/root/.ssh/authorized_keys |
在 hadoop01上验证免密登陆,可以看到时间信息
1 | ssh hadoop01 date |
如果不配置的话,后来启动Hadoop的每个服务的时候会让输入密码。
如果Connection refused,可以执行
1 | sudo systemsetup -f -setremotelogin on |
安装JDK
官方下载JDK 网址
或者 链接:https://pan.baidu.com/s/1JdPCMMEq178hXV5V4Ild3Q 密码:03l1
比如下载的文件为jdk-8u221-linux-x64.rpm
更改文件权限
1 | chmod 755 jdk-8u221-linux-x64.rpm |
安装
1 | rpm -ivh jdk-8u221-linux-x64.rpm |
安装后的路径为/usr/java/jdk1.8.0_221-amd64
删除文件
1 | rm -rf jdk-8u221-linux-x64.rpm |
查询Java版本
1 | java -version |
查看JAVA_HOME
1 | echo $JAVA_HOME |
添加环境变量
1 | cd /etc/profile.d/ |
创建配置文件
1 | vi /etc/profile.d/jdk.sh |
加入:
1 | export JAVA_HOME=/usr/java/jdk1.8.0_221-amd64 |
配置立即生效
1 | source /etc/profile |
查询java版本
1 | java -version |
查看java-home
1 | echo $JAVA_HOME |
复制到另两台服务器
1 | scp -r /usr/java/jdk1.8.0_221-amd64 root@ hadoop02:/usr/java |
小知识
在/etc/profile.d 目录中存放的是一些应用程序所需的启动脚本。
这些脚本文件之所以能够 被自动执行,是因为在/etc/profile 中使用一个for循环语句来调用这些脚本。
而这些脚本文件是用来设置一些变量和运行一些初始化过程的。
Linux 环境下/etc/profile和/etc/profile.d 的区别
两个文件都是设置环境变量文件的,两者都是永久性的环境变量,是全局变量,对所有用户生效
/etc/profile.d/比/etc/profile好维护,不想要什么变量直接删除/etc/profile.d/下对应的shell脚本即可,不用像
/etc/profile需要改动此文件