前言 官网:https://hadoop.apache.org/releases.html
本文环境软件版本
名称
版本
JDK
1.8.0_221
Hadoop
2.7.7
注意
一定要保证开发环境和部署的环境保持一致!否则运行时会报各种错误。
基础环境配置 https://www.psvmc.cn/article/2022-03-31-bigdata-environment.html
下载解压 https://archive.apache.org/dist/hadoop/common/hadoop-2.7.7/
服务器中运行
1 wget https://archive.apache.org/dist/hadoop/common/hadoop-2.7.7/hadoop-2.7.7.tar.gz
或者使用百度云下载
链接:https://pan.baidu.com/s/1OPzD9V_mBnBz06JQ3X5DSA
解压
1 2 3 4 tar -zxvf hadoop-2.7.7.tar.gz mkdir -p /data/tools/bigdata/mv hadoop-2.7.7 /data/tools/bigdata/cd /data/tools/bigdata/hadoop-2.7.7
配置环境变量 创建配置文件
1 vi /etc/profile.d/hadoop.sh
内容设置为
1 2 3 4 export HADOOP_HOME=/data/tools/bigdata/hadoop-2.7.7export PATH=$PATH :$HADOOP_HOME /binexport PATH=$PATH :$HADOOP_HOME /sbin
配置生效
查看是否生效
伪分布式部署 添加文件夹 1 2 3 4 5 ssh hadoop01 "mkdir -p /data/tools/bigdata/zdata/hadoop/tmp" ssh hadoop01 "mkdir -p /data/tools/bigdata/zdata/hadoop/dfs/namenode_data" ssh hadoop01 "mkdir -p /data/tools/bigdata/zdata/hadoop/dfs/datanode_data" ssh hadoop01 "mkdir -p /data/tools/bigdata/zdata/hadoop/dfs/journalnode_data" ssh hadoop01 "mkdir -p /data/tools/bigdata/zdata/hadoop/dfs/edits"
其他服务器上创建文件夹
1 2 3 4 5 6 7 8 9 10 11 ssh hadoop02 "mkdir -p /data/tools/bigdata/zdata/hadoop/tmp" ssh hadoop02 "mkdir -p /data/tools/bigdata/zdata/hadoop/dfs/namenode_data" ssh hadoop02 "mkdir -p /data/tools/bigdata/zdata/hadoop/dfs/datanode_data" ssh hadoop02 "mkdir -p /data/tools/bigdata/zdata/hadoop/dfs/journalnode_data" ssh hadoop02 "mkdir -p /data/tools/bigdata/zdata/hadoop/dfs/edits" ssh hadoop03 "mkdir -p /data/tools/bigdata/zdata/hadoop/tmp" ssh hadoop03 "mkdir -p /data/tools/bigdata/zdata/hadoop/dfs/namenode_data" ssh hadoop03 "mkdir -p /data/tools/bigdata/zdata/hadoop/dfs/datanode_data" ssh hadoop03 "mkdir -p /data/tools/bigdata/zdata/hadoop/dfs/journalnode_data" ssh hadoop03 "mkdir -p /data/tools/bigdata/zdata/hadoop/dfs/edits"
修改配置文件 注意
本文是伪分布式部署
进入配置文件目录
1 cd /data/tools/bigdata/hadoop-2.7.7/etc/hadoop
hadoop-env.sh 将原本的JAVA_HOME 替换为绝对路径就可以了
1 2 3 export JAVA_HOME=/usr/java/jdk1.8.0_221-amd64
注意
虽然系统已经设置JAVA_HOME,但是运行时依旧无法找到,所以配置的绝对路径
一定要配置,否则会产生运行正常,但是远程连接服务器的时候报Error:JAVA_HOME is not set and could not be found
core-site.xml 1 2 3 4 5 6 7 8 9 10 11 12 13 14 <?xml version="1.0" encoding="UTF-8" ?> <?xml-stylesheet type="text/xsl" href="configuration.xsl" ?> <configuration > <property > <name > hadoop.tmp.dir</name > <value > file:///data/tools/bigdata/zdata/hadoop/tmp</value > <description > </description > </property > <property > <name > fs.defaultFS</name > <value > hdfs://hadoop01:9000</value > </property > </configuration >
hdfs-site.xml 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 <?xml version="1.0" encoding="UTF-8" ?> <?xml-stylesheet type="text/xsl" href="configuration.xsl" ?> <configuration > <property > <name > dfs.replication</name > <value > 1</value > </property > <property > <name > dfs.namenode.name.dir</name > <value > file:/data/tools/bigdata/zdata/hadoop/dfs/namenode_data</value > </property > <property > <name > dfs.datanode.data.dir</name > <value > file:/data/tools/bigdata/zdata/hadoop/dfs/datanode_data</value > </property > </configuration >
mapred-site.xml 1 2 3 4 5 6 7 8 9 <?xml version="1.0" ?> <?xml-stylesheet type="text/xsl" href="configuration.xsl" ?> <configuration > <property > <name > mapreduce.framework.name</name > <value > yarn</value > </property > </configuration >
yarn-site.xml 1 2 3 4 5 6 7 8 9 10 11 <?xml version="1.0" ?> <configuration > <property > <name > yarn.resourcemanager.hostname</name > <value > hadoop01</value > </property > <property > <name > yarn.nodemanager.aux-services</name > <value > mapreduce_shuffle</value > </property > </configuration >
log4j.properties 剔除警告(可选)
添加
1 log4j.logger.org.apache.hadoop.util.NativeCodeLoader=ERROR
启动/停止 1 2 3 4 sudo chmod -R 755 $HADOOP_HOME rm -rf /data/tools/bigdata/zdata/hadoop/tmphdfs namenode -format
这个操作主要是创建fsimage和edits文件。
只要看到信息中有一句关键:
INFO common.Storage: Storage directory /data/tools/bigdata/hadoop-2.7.7/tmp/dfs/name has been successfully formatted.
运行
1 sh $HADOOP_HOME /sbin/start-all.sh
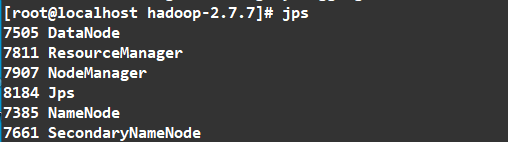
输入
如图
访问
我的服务器的IP为 192.168.7.101
HDFS监控页面查询:
http://192.168.7.101:50070/
查看文件可以访问这个地址
http://192.168.7.101:50070/explorer.html#/
Yarn监控页面查询:
http://192.168.7.101:8088/cluster
停止
1 sh $HADOOP_HOME /sbin/stop-all.sh
端口说明:
端口
作用
8088
cluster and all applications
50070
Hadoop NameNode
50090
Secondary NameNode
50075
DataNode
停止所有服务
1 sh $HADOOP_HOME /sbin/stop-all.sh
测试 1 2 3 mkdir -p /data/hadooptest/inputcd /data/hadooptest/inputvi 1.txt
随便添加一些文本
1 2 3 4 5 6 7 8 1111 2222 333 333 444 55 55 55
复制文件到hadoop中
1 2 3 4 5 hadoop fs -mkdir /data/ hadoop fs -mkdir /data/input hadoop fs -rm -r /data/input/1.txt hadoop fs -rm -r /data/output hadoop fs -put /data/hadooptest/input/1.txt /data/input/
测试
1 2 3 cd /data/tools/bigdata/hadoop-2.7.7hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.7.jar wordcount /data/input/ /data/output hadoop fs -text /data/output/*
结果
它就把统计给生成了
注册为服务 添加服务
1 2 cd /etc/init.dvi hadoop
内容如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 #!/bin/bash su - root <<! case $1 in start) sh /data/tools/bigdata/hadoop-2.7.7/sbin/start-all.sh ;; stop) sh /data/tools/bigdata/hadoop-2.7.7/sbin/stop-all.sh ;; *) echo "Usage:$0 (start|stop)" ;; esac exit !
注意
路径要使用完整路径,不能使用类似于$HADOOP_HOME/sbin/stop-all.sh的路径。
赋予权限
设置开机启动
1 2 sudo chkconfig --add hadoopchkconfig hadoop on
启动服务
查看hadoop服务
HA部署 添加文件夹 1 2 3 4 5 ha-call.sh "mkdir -p /data/tools/bigdata/zdata/hadoop/tmp" ha-call.sh "mkdir -p /data/tools/bigdata/zdata/hadoop/dfs/namenode_data" ha-call.sh "mkdir -p /data/tools/bigdata/zdata/hadoop/dfs/datanode_data" ha-call.sh "mkdir -p /data/tools/bigdata/zdata/hadoop/dfs/journalnode_data" ha-call.sh "mkdir -p /data/tools/bigdata/zdata/hadoop/dfs/edits"
修改配置文件 进入配置文件目录
1 cd $HADOOP_HOME /etc/hadoop
core-site.xml 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 <?xml version="1.0" encoding="UTF-8" ?> <?xml-stylesheet type="text/xsl" href="configuration.xsl" ?> <configuration > <property > <name > fs.defaultFS</name > <value > hdfs://hdfsns</value > </property > <property > <name > hadoop.tmp.dir</name > <value > file:///data/tools/bigdata/zdata/hadoop/tmp</value > </property > <property > <name > io.file.buffer.size</name > <value > 4096</value > </property > <property > <name > ha.zookeeper.quorum</name > <value > hadoop01:2181,hadoop02:2181,hadoop03:2181</value > </property > </configuration >
hdfs-site.xml 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 <?xml version="1.0" encoding="UTF-8" ?> <?xml-stylesheet type="text/xsl" href="configuration.xsl" ?> <configuration > <property > <name > dfs.block.size</name > <value > 134217728</value > </property > <property > <name > dfs.replication</name > <value > 3</value > </property > <property > <name > dfs.name.dir</name > <value > file:///data/tools/bigdata/zdata/hadoop/dfs/namenode_data</value > </property > <property > <name > dfs.data.dir</name > <value > file:///data/tools/bigdata/zdata/hadoop/dfs/datanode_data</value > </property > <property > <name > dfs.webhdfs.enabled</name > <value > true</value > </property > <property > <name > dfs.datanode.max.transfer.threads</name > <value > 4096</value > </property > <property > <name > dfs.nameservices</name > <value > hdfsns</value > </property > <property > <name > dfs.ha.namenodes.hdfsns</name > <value > nn1,nn2</value > </property > <property > <name > dfs.namenode.rpc-address.hdfsns.nn1</name > <value > hadoop01:9000</value > </property > <property > <name > dfs.namenode.servicepc-address.hdfsns.nn1</name > <value > hadoop01:53310</value > </property > <property > <name > dfs.namenode.http-address.hdfsns.nn1</name > <value > hadoop01:50070</value > </property > <property > <name > dfs.namenode.rpc-address.hdfsns.nn2</name > <value > hadoop02:9000</value > </property > <property > <name > dfs.namenode.servicepc-address.hdfsns.nn2</name > <value > hadoop02:53310</value > </property > <property > <name > dfs.namenode.http-address.hdfsns.nn2</name > <value > hadoop02:50070</value > </property > <property > <name > dfs.namenode.shared.edits.dir</name > <value > qjournal://hadoop01:8485;hadoop02:8485;hadoop03:8485/hdfsns</value > </property > <property > <name > dfs.journalnode.edits.dir</name > <value > /data/tools/bigdata/zdata/hadoop/dfs/journalnode_data</value > </property > <property > <name > dfs.namenode.edits.dir</name > <value > /data/tools/bigdata/zdata/hadoop/dfs/edits</value > </property > <property > <name > dfs.ha.automatic-failover.enabled</name > <value > true</value > </property > <property > <name > dfs.client.failover.proxy.provider.hdfsns</name > <value > org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value > </property > <property > <name > dfs.ha.fencing.methods</name > <value > sshfence</value > </property > <property > <name > dfs.ha.fencing.ssh.private-key-files</name > <value > /root/.ssh/id_rsa</value > </property > <property > <name > dfs.permissions</name > <value > false</value > </property > </configuration >
注意
2.7.7版本最多支持2个NameNode
mapred-site.xml mapred-site.xml.template 重命名为 mapred-site.xml
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 <?xml version="1.0" ?> <?xml-stylesheet type="text/xsl" href="configuration.xsl" ?> <configuration > <property > <name > mapreduce.framework.name</name > <value > yarn</value > </property > <property > <name > mapreduce.jobhistory.address</name > <value > hadoop01:10020</value > </property > <property > <name > mapreduce.jobhistory.webapp.address</name > <value > hadoop01:19888</value > </property > <property > <name > mapreduce.job.ubertask.enable</name > <value > true</value > </property > </configuration >
yarn-site.xml 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 <?xml version="1.0" ?> <configuration > <property > <name > yarn.resourcemanager.ha.enabled</name > <value > true</value > </property > <property > <name > yarn.resourcemanager.cluster-id</name > <value > hayarn</value > </property > <property > <name > yarn.resourcemanager.ha.rm-ids</name > <value > rm1,rm2</value > </property > <property > <name > yarn.resourcemanager.hostname.rm1</name > <value > hadoop02</value > </property > <property > <name > yarn.resourcemanager.hostname.rm2</name > <value > hadoop03</value > </property > <property > <name > yarn.resourcemanager.zk-address</name > <value > hadoop01:2181,hadoop02:2181,hadoop03:2181</value > </property > <property > <name > yarn.resourcemanager.recovery.enabled</name > <value > true</value > </property > <property > <name > yarn.resourcemanager.store.class</name > <value > org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value > </property > <property > <name > yarn.resourcemanager.hostname</name > <value > hadoop03</value > </property > <property > <name > yarn.nodemanager.aux-services</name > <value > mapreduce_shuffle</value > </property > <property > <name > yarn.log-aggregation-enable</name > <value > true</value > </property > <property > <name > yarn.log-aggregation.retain-seconds</name > <value > 604800</value > </property > <property > <name > yarn.nodemanager.vmem-pmem-ratio</name > <value > 4</value > </property > <property > <name > yarn.nodemanager.resource.memory-mb</name > <value > 4096</value > </property > <property > <name > yarn.scheduler.minimum-allocation-mb</name > <value > 1024</value > </property > <property > <name > yarn.scheduler.maximum-allocation-mb</name > <value > 2048</value > </property > <property > <name > yarn.nodemanager.pmem-check-enabled</name > <value > false</value > </property > <property > <name > yarn.nodemanager.vmem-check-enabled</name > <value > false</value > </property > </configuration >
capacity-scheduler.xml 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 <configuration > <property > <name > yarn.scheduler.capacity.maximum-applications</name > <value > 10000</value > <description > Maximum number of applications that can be pending and running. </description > </property > <property > <name > yarn.scheduler.capacity.maximum-am-resource-percent</name > <value > 0.3</value > <description > Maximum percent of resources in the cluster which can be used to run application masters i.e. controls number of concurrent running applications. </description > </property > <property > <name > yarn.scheduler.capacity.resource-calculator</name > <value > org.apache.hadoop.yarn.util.resource.DefaultResourceCalculator</value > <description > The ResourceCalculator implementation to be used to compare Resources in the scheduler. The default i.e. DefaultResourceCalculator only uses Memory while DominantResourceCalculator uses dominant-resource to compare multi-dimensional resources such as Memory, CPU etc. </description > </property > <property > <name > yarn.scheduler.capacity.root.queues</name > <value > default</value > <description > The queues at the this level (root is the root queue). </description > </property > <property > <name > yarn.scheduler.capacity.root.default.capacity</name > <value > 100</value > <description > Default queue target capacity.</description > </property > <property > <name > yarn.scheduler.capacity.root.default.user-limit-factor</name > <value > 1</value > <description > Default queue user limit a percentage from 0.0 to 1.0. </description > </property > <property > <name > yarn.scheduler.capacity.root.default.maximum-capacity</name > <value > 100</value > <description > The maximum capacity of the default queue. </description > </property > <property > <name > yarn.scheduler.capacity.root.default.state</name > <value > RUNNING</value > <description > The state of the default queue. State can be one of RUNNING or STOPPED. </description > </property > <property > <name > yarn.scheduler.capacity.root.default.acl_submit_applications</name > <value > *</value > <description > The ACL of who can submit jobs to the default queue. </description > </property > <property > <name > yarn.scheduler.capacity.root.default.acl_administer_queue</name > <value > *</value > <description > The ACL of who can administer jobs on the default queue. </description > </property > <property > <name > yarn.scheduler.capacity.node-locality-delay</name > <value > 40</value > <description > </description > </property > <property > <name > yarn.scheduler.capacity.queue-mappings</name > <value > </value > <description > </description > </property > <property > <name > yarn.scheduler.capacity.queue-mappings-override.enable</name > <value > false</value > <description > </description > </property > </configuration >
slaves 1 2 3 hadoop01 hadoop02 hadoop03
log4j.properties 剔除警告(可选):
添加
1 log4j.logger.org.apache.hadoop.util.NativeCodeLoader=ERROR
删除日志 刚开始部署时每次启动前我们可以删除之前的日志文件,方便排查问题。
1 ha-call.sh "rm -rf $HADOOP_HOME /logs/*"
配置分发 1 ha-fenfa.sh $HADOOP_HOME
初始前删除之前的文件
只有初始化集群的时候执行一次,以后不再执行。
创建脚本
1 vi /data/tools/bigdata/mysh/ha-hadoop-init.sh
内容如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 #!/bin/bash NODES=("hadoop01" "hadoop02" "hadoop03" ) for NODE in ${NODES[*]} ;do echo "$NODE :初始化完毕" ssh $NODE "rm -rf /data/tools/bigdata/zdata/hadoop/tmp/*" ssh $NODE "rm -rf /data/tools/bigdata/zdata/hadoop/dfs/journalnode_data/*" ssh $NODE "rm -rf /data/tools/bigdata/zdata/hadoop/dfs/edits/*" ssh $NODE "rm -rf /data/tools/bigdata/zdata/hadoop/dfs/datanode_data/*" ssh $NODE "rm -rf /data/tools/bigdata/zdata/hadoop/dfs/namenode_data/*" done echo "---------------------------------------" echo "--------Hadoop初始化脚本执行完成!--------" echo "---------------------------------------"
赋权限
1 chmod +x /data/tools/bigdata/mysh/ha-hadoop-init.sh
执行
1 bash /data/tools/bigdata/mysh/ha-hadoop-init.sh
如果运行报错
未预期的符号 `$’{\r’’ 附近有语法错误
考虑到代码是从windows下复制过来的,脚本可能在格式上存在问题
解决方案:
方法1:
文本编辑器打开设置换行编码为Unix。
方法2:
1 2 sudo yum install dos2unixdos2unix /data/tools/bigdata/mysh/ha-hadoop-init.sh
初始化集群
只用执行一次,以后启动不用再执行。
(1). 启动3个Zookeeper
要保证ZK为启动状态
1 ha-call.sh "zkServer.sh start"
(2). 启动3个JournalNode
JournalNode的作用:NameNode之间共享数据
1 ha-call.sh "hadoop-daemon.sh start journalnode"
(3). 格式化NameNode
格式化前删除之前的文件
仅hadoop01
1 2 3 sudo chmod -R 755 /data/tools/bigdata/zdata/hadoophdfs namenode -format
这个操作主要是创建fsimage和edits文件。
只要看到信息中有一句关键:
INFO common.Storage: Storage directory /data/tools/bigdata/zdata/dfs/name has been successfully formatted.
则格式化成功.
(4). 复制hadoop01上的NameNode的元数据到hadoop02
1 scp -r /data/tools/bigdata/zdata/hadoop/dfs/namenode_data/current/ root@hadoop02:/data/tools/bigdata/zdata/hadoop/dfs/namenode_data/
(5). 在NameNode节点(hadoop01或hadoop02)格式化zkfc
1 ssh hadoop01 "hdfs zkfc -formatZK"
(6). 停止3个JournalNode
JournalNode的作用:NameNode之间共享数据
1 ha-call.sh "hadoop-daemon.sh stop journalnode"
启动集群 (1). 在hadoop01上启动HDFS相关服务
1 ssh hadoop01 "start-dfs.sh"
对应日志
1 2 3 4 5 6 7 8 9 10 11 Starting namenodes on [hadoop01 hadoop02] hadoop01: starting namenode, logging to /data/tools/bigdata/hadoop-2.7.7/logs/hadoop-root-namenode-hadoop01.out hadoop02: starting namenode, logging to /data/tools/bigdata/hadoop-2.7.7/logs/hadoop-root-namenode-hadoop02.out localhost: starting datanode, logging to /data/tools/bigdata/hadoop-2.7.7/logs/hadoop-root-datanode-hadoop01.out Starting journal nodes [hadoop01 hadoop02 hadoop03] hadoop03: starting journalnode, logging to /data/tools/bigdata/hadoop-2.7.7/logs/hadoop-root-journalnode-hadoop03.out hadoop02: starting journalnode, logging to /data/tools/bigdata/hadoop-2.7.7/logs/hadoop-root-journalnode-hadoop02.out hadoop01: starting journalnode, logging to /data/tools/bigdata/hadoop-2.7.7/logs/hadoop-root-journalnode-hadoop01.out Starting ZK Failover Controllers on NN hosts [hadoop01 hadoop02] hadoop02: starting zkfc, logging to /data/tools/bigdata/hadoop-2.7.7/logs/hadoop-root-zkfc-hadoop02.out hadoop01: starting zkfc, logging to /data/tools/bigdata/hadoop-2.7.7/logs/hadoop-root-zkfc-hadoop01.out
(2). 在hadoop01上启动YARN相关服务
1 ssh hadoop01 "start-yarn.sh"
在启动YARN时,通常可以直接使用start-yarn.sh脚本来启动资源管理器(ResourceManager)和节点管理器(NodeManager),而不再需要单独调用yarn-daemon.sh来启动ResourceManager。
start-yarn.sh脚本会自动启动ResourceManager和NodeManager进程,以及其他与YARN相关的组件。
它会在后台运行这些进程,并根据配置文件中的设置来分配资源和管理任务。
(3). 最后单独启动hadoop01的历史任务服务器
1 ssh hadoop01 "mr-jobhistory-daemon.sh start historyserver"
这个历史任务服务器,可以查看已执行的MapReduce任务。
执行MapReduce任务本身不会受到影响,它们仍然可以在YARN集群上正常运行和完成,可以不启动。
或者
用自定义脚本
1 2 3 ha-hadoop.sh start ha-hadoop.sh status ha-hadoop.sh stop
我们可以在ZK中看到 我们定义的键都在第二级,第一级是框架定义的。
查看集群 查看
结果
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 --------hadoop01-------- 10785 NameNode 7139 CliFrontend 11619 JobHistoryServer 11509 DFSZKFailoverController 10952 DataNode 11224 JournalNode 11736 NodeManager 12939 Jps --------hadoop02-------- 3041 NameNode 3333 DFSZKFailoverController 3894 Jps 3113 DataNode 3513 NodeManager 3210 JournalNode 3436 ResourceManager 1711 QuorumPeerMain --------hadoop03-------- 2903 DataNode 3223 NodeManager 3000 JournalNode 3435 Jps 1679 QuorumPeerMain 3119 ResourceManager
【查看NameNode的状态】
1 2 hdfs haadmin -getServiceState nn1 hdfs haadmin -getServiceState nn2
可以看到一个是active一个是standby
【查看ResourceManager的状态】
1 2 yarn rmadmin -getServiceState rm1 yarn rmadmin -getServiceState rm2
可以看到一个是active一个是standby
访问 我的服务器的IP为 192.168.7.101
HDFS监控页面查询:
http://192.168.7.101:50070/
查看文件可以访问这个地址
http://192.168.7.101:50070/explorer.html#/
http://192.168.7.102:50070/explorer.html#/
Yarn监控页面查询:
http://192.168.7.102:8088/cluster
http://192.168.7.103:8088/cluster
任务历史
http://192.168.7.101:19888
服务无法停止 原因是记录Hadoop启动的PID被修改
我们只能手动停止
为了避免这个问题,可以把PID存放在其他地方
在配置文件中$HADOOP_HOME/conf/hadoop-env.sh中添加如下
1 export HADOOP_PID_DIR=/data/tools/bigdata/zdata/hadoop/pids