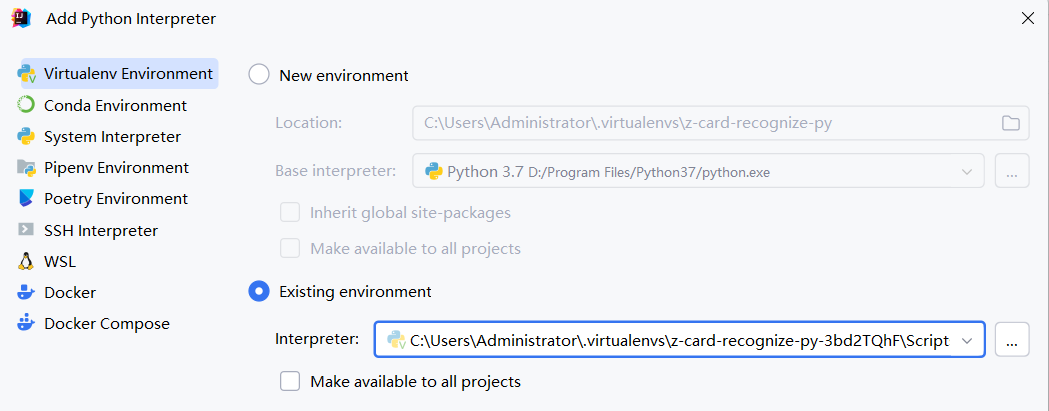
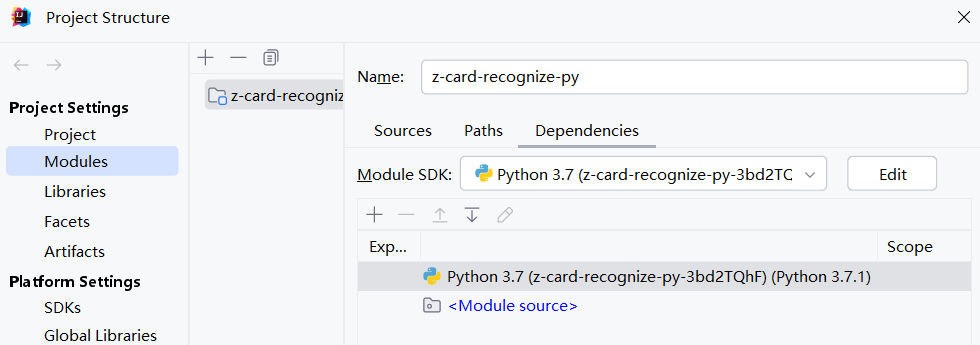
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
| import csv
import json
import os
import cv2
import numpy as np
from pathlib import Path
from utils.cv_common_utils import CvCommonUtils
script_path = Path(__file__).resolve()
project_path = str(script_path.parent.parent)
model_filepath = os.path.join(project_path, "ml-resource", "knn_model.xml")
json_filepath = os.path.join(project_path, "ml-resource", 'knn_label_map.json')
class KnnUtils:
@staticmethod
def model_train(tsv_path):
path_list = []
word_list = []
with open(tsv_path, 'r', newline='', encoding='utf-8') as file:
reader = csv.reader(file, delimiter='\t')
for row in reader:
if len(row) >= 2:
path_list.append(row[0])
word_list.append(row[1])
word_set = set(word_list)
label_map = {}
for index, word in enumerate(word_set):
label_map[word] = index
label_list = []
for word in word_list:
label_list.append(label_map[word])
inverse_label_map = {v: k for k, v in label_map.items()}
with open(json_filepath, 'w', encoding='utf-8') as file:
json.dump(inverse_label_map, file, ensure_ascii=False, indent=4)
img_list = []
for path in path_list:
img = CvCommonUtils.read_img(path, cv2.THRESH_BINARY)
img2 = CvCommonUtils.get_mat32(img)
img_list.append(img2.flatten())
features = np.array(img_list, dtype=np.float32)
labels = np.array(label_list, dtype=np.int32)
knn = cv2.ml.KNearest_create()
knn.train(features, cv2.ml.ROW_SAMPLE, labels)
knn.save(model_filepath)
print("KNN训练完成")
loaded_knn = None
inverse_label_map = None
@staticmethod
def model_load():
if KnnUtils.loaded_knn is None:
KnnUtils.loaded_knn = cv2.ml.KNearest_load(model_filepath)
with open(json_filepath, 'r', encoding='utf-8') as file:
KnnUtils.inverse_label_map = json.load(file)
@staticmethod
def recognition_img(img):
KnnUtils.model_load()
if KnnUtils.loaded_knn is None:
print("模型加载失败")
return
if not CvCommonUtils.is_binary_image(img):
img = CvCommonUtils.binary(img)
print("非二值化图片")
img2 = CvCommonUtils.get_mat32(img)
img_data = img2.flatten()
img_data2 = list(map(float, img_data))
img_list = []
img_list.append(img_data2)
test_data = np.array(img_list, dtype=np.float32)
ret, results, neighbors, dist = KnnUtils.loaded_knn.findNearest(test_data, k=3)
predicted_labels = results.flatten()
if len(predicted_labels) > 0:
predicted_label = predicted_labels[0]
key = str(int(predicted_label))
return KnnUtils.inverse_label_map[key]
return ""
|