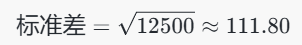前言 上文中我们已经实现了字符的切割,字符识别的时候识别效果不是太好,所以我们采用机器学习来识别字符。
机器学习确实在训练后要比之前的识别效果好得多。
阿里针对教育的OCR识别
https://ai.aliyun.com/ocr/edu?spm=5176.21213303.J_qCOwPWspKEuWcmp8qiZNQ.30.25ed2f3dcX4P0c&scm=20140722.S_product@@%E4%BA%91%E4%BA%A7%E5%93%81@@82233._.ID_product@@%E4%BA%91%E4%BA%A7%E5%93%81@@82233-RL_%E7%AD%94%E9%A2%98%E5%8D%A1%E8%AF%86%E5%88%AB-LOC_llm-OR_ser-V_3-RE_new3@@cardOld-P0_0
试卷切题识别
安装 1 Install-Package Microsoft.ML -Version 3.0.1
注意
这里发现不能使用.Net Framework项目,不兼容,创建.Net 6项目就没问题
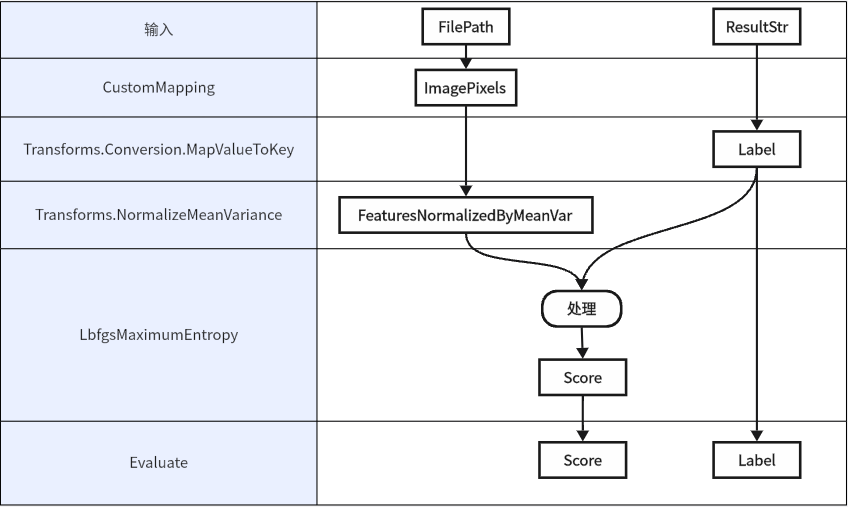
整体流程
模型训练 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 namespace z_exam_card_recognize.utils { using System; using Microsoft.ML.Data; using Microsoft.ML.Trainers; using Microsoft.ML; using Microsoft.ML.Transforms; using Newtonsoft.Json; public class ZmlUtils { private static readonly string AssetsFolder = @"D:\Project\csharp\z-exam-card-recognize\ml-resource\ml" ; private static readonly string TrainTagsPath = Path.Combine(AssetsFolder, "Word.tsv" ); private static readonly string ModelPath = Path.Combine(AssetsFolder, "Word-Model.zip" ); private static readonly string TestFolder = Path.Combine(AssetsFolder, "test" ); private static readonly string LabelListPath = Path.Combine(AssetsFolder, "Word-Label.json" ); private static readonly MLContext MlContext = new MLContext(seed: 1 ); public static void Test () { TrainAndSaveModel(); TestSomePredictions(); } public static void TrainAndSaveModel () { IDataView? fulldata = MlContext.Data.LoadFromTextFile<ZInputData>( path: TrainTagsPath, separatorChar: '\t' , hasHeader: false ); DataOperationsCatalog.TrainTestData trainTestData = MlContext.Data.TrainTestSplit(fulldata, testFraction: 0.1 ); IDataView? trainData = trainTestData.TrainSet; IDataView? testData = trainTestData.TestSet; EstimatorChain<NormalizingTransformer>? dataProcessPipeline = MlContext.Transforms .CustomMapping( new LoadImageConversion().GetMapping(), contractName: "LoadImageConversionAction" ) .Append( MlContext.Transforms.Conversion.MapValueToKey( "Label" , "ResultStr" , keyOrdinality: ValueToKeyMappingEstimator.KeyOrdinality.ByValue ) ) .Append( MlContext.Transforms.NormalizeMeanVariance( outputColumnName: "FeaturesNormalizedByMeanVar" , inputColumnName: "ImagePixels" ) ); LbfgsMaximumEntropyMulticlassTrainer? trainer = MlContext.MulticlassClassification.Trainers.LbfgsMaximumEntropy( labelColumnName: "Label" , featureColumnName: "FeaturesNormalizedByMeanVar" ); EstimatorChain<KeyToValueMappingTransformer>? pipeline = dataProcessPipeline .Append(trainer) .Append(MlContext.Transforms.Conversion.MapKeyToValue("PredictNumber" , "Label" )); ITransformer trainedModel = pipeline.Fit(trainData); IDataView? predictions = trainedModel.Transform(testData); MulticlassClassificationMetrics? metrics = MlContext.MulticlassClassification.Evaluate( data: predictions, labelColumnName: "Label" , scoreColumnName: "Score" ); PrintMultiClassClassificationMetrics(trainer.ToString(), metrics); MlContext.Model.Save( trainedModel, trainData.Schema, ModelPath ); List<string > templabelList = MlContext.Data .CreateEnumerable<ZInputData>(fulldata, reuseRowObject: false ) .Select(x => x.ResultStr) .Distinct() .ToList(); File.WriteAllText(LabelListPath, JsonConvert.SerializeObject(templabelList)); } public static void PrintMultiClassClassificationMetrics (string ? trainerName, MulticlassClassificationMetrics metrics { Console.WriteLine($"*****************************************************" ); Console.WriteLine($"* Metrics for {trainerName} multi-class classifier" ); Console.WriteLine($"*-----------------------------------------------------" ); Console.WriteLine($"* Log-Loss: {metrics.LogLoss:#.##} " ); Console.WriteLine($"* Log-Loss Reduction: {metrics.LogLossReduction:#.##} " ); Console.WriteLine($"*****************************************************" ); } private static PredictionEngine<ZInputData, ZOutPutData>? _predEngine; private static List<string >? _labels; private static void LoadModel () { if (_predEngine == null ) { _labels = ZJsonHelper.JsonToList<string >(File.ReadAllText(LabelListPath)); ITransformer trainedModel = MlContext.Model.Load(ModelPath, out DataViewSchema? _); _predEngine = MlContext.Model.CreatePredictionEngine<ZInputData, ZOutPutData>(trainedModel); } } public static string RecognitionImg (string imgPath { LoadModel(); ZInputData img = new ZInputData() { FilePath = imgPath }; ZOutPutData? result = _predEngine?.Predict(img); if (result != null && _labels != null ) { return _labels[result.GetPredictResult()]; } return "" ; } private static void TestSomePredictions () { DirectoryInfo testFolder = new DirectoryInfo(TestFolder); foreach (FileInfo image in testFolder.GetFiles()) { string predictedLabel = RecognitionImg(image.FullName); Console.WriteLine($"Current Source={image.Name} ,PredictResult={predictedLabel} " ); } } } public class ZInputData { [LoadColumn(0) ] public string FilePath = "" ; [LoadColumn(1) ] public string ResultStr = "" ; } internal class ZOutPutData { public float []? Score; public int GetPredictResult () { if (Score != null ) { return Array.IndexOf(Score, Score.Max()); } return 0 ; } } }
使用ML.NET框架来构建一个数据预处理管道(dataProcessPipeline),该管道旨在处理图像数据并将其转换为机器学习模型可以使用的格式。
下面是对这段代码的详细解释:
(1) 初始化EstimatorChain
EstimatorChain<NormalizingTransformer>? dataProcessPipeline:这里声明了一个名为dataProcessPipeline的可空变量,它是一个EstimatorChain<NormalizingTransformer>类型的实例。
EstimatorChain是ML.NET中用于串联多个数据转换(estimators)的类,而NormalizingTransformer是特定于归一化转换的转换器类型。
这里使用可空类型(?)是因为在构建管道的过程中,如果发生错误,这个变量可能不会被正确初始化。
(2) 添加自定义映射
.CustomMapping(new LoadImageConversion().GetMapping(), contractName: "LoadImageConversionAction"):这一步骤通过.CustomMapping方法添加了一个自定义的数据转换。
这里,LoadImageConversion().GetMapping()调用了某个自定义类(假设是LoadImageConversion)的GetMapping方法,该方法返回一个描述如何将输入数据映射到输出数据的Action或Func。
这个自定义映射可能是用于加载图像文件,并将其转换为像素值数组(或其他形式),以便后续处理。
contractName参数用于标识这个自定义映射,以便于调试和日志记录。
(3) 添加标签映射
.Append(...)方法用于将新的转换器添加到管道中。在这个例子中,首先添加了一个MapValueToKey转换器,它将文本标签(假设存储在”NumberStr”列中)映射到一个键(整数)上。
这对于分类任务尤其重要,因为机器学习算法通常期望标签是数值型的。
keyOrdinality参数设置为ByValue,表示键的顺序将基于值的出现顺序。
(4) 添加归一化
接着,管道通过另一个.Append(...)方法添加了一个归一化转换器NormalizeMeanVariance。
这个转换器将输入特征(在这个例子中是”ImagePixels”列中的像素值)通过计算均值和方差进行归一化处理,并将结果存储在”FeaturesNormalizedByMeanVar”列中。
归一化是预处理中常见的步骤,有助于改善许多机器学习算法的性能。
注意:
ValueToKeyMappingEstimator.KeyOrdinality 参数
ByValue
这意味着,如果你的数据中值的出现顺序是B, A, C,那么这些值将被映射为整数键 0, 1, 2,按照它们在数据中首次出现的顺序。
ByOccurrence
出现频率高的值将被分配较低的整数键,出现频率低的值将被分配较高的整数键。
图片转换器 注意自定义的转换器中要被使用的输入的字段要和模型输入数据的字段名称相同,否则无法注入。
当然我们直接使用模型输入的类型ZInputData也是可以的。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 namespace z_exam_card_recognize.utils { using System; using System.Drawing; using Microsoft.ML.Data; using Microsoft.ML.Transforms; public class LoadImageConversionInput { public string FilePath { get ; set ; } } public class LoadImageConversionOutput { [VectorType(400) ] public float [] ImagePixels { get ; set ; } } [CustomMappingFactoryAttribute("LoadImageConversionAction" ) ] public class LoadImageConversion : CustomMappingFactory <LoadImageConversionInput , LoadImageConversionOutput > { public void CustomAction (LoadImageConversionInput input, LoadImageConversionOutput output ) { output.ImagePixels = new float [400 ]; Bitmap bmp = new Bitmap(input.FilePath); for (int x = 0 ; x < 20 ; x++) for (int y = 0 ; y < 20 ; y++) { Color pixel = bmp.GetPixel(x, y); int gray = (pixel.R + pixel.G + pixel.B) / 3 / 16 ; output.ImagePixels[x + y * 20 ] = gray; } bmp.Dispose(); } public override Action<LoadImageConversionInput, LoadImageConversionOutput> GetMapping () CustomAction; } }
加载训练数据的方式 在 Microsoft.ML 中,加载训练数据有多种方式,这取决于数据的存储格式和来源。
以下是一些常见的方法:
从文件加载数据 CSV 文件 :使用 MLContext.Data.LoadFromTextFile 方法可以加载 CSV 文件中的数据。可以指定列名、数据类型等参数。
1 2 3 4 5 var data = mlContext.Data.LoadFromTextFile<ModelInput>( path: "data.csv" , separatorChar: ',' , hasHeader: false );
TSV 文件 :与 CSV 文件类似,只需更改 separatorChar 参数为 '\t'。
从内存加载数据 可以通过 MLContext.Data.LoadFromEnumerable 方法直接从内存中的集合(如 List<T>)加载数据。
1 2 3 List<ZInputData> dataList = new List<ZInputData>(); dataList.Add(new ZInputData { FilePath = "D:\\1.png" , ResultStr = "A" }); IDataView? fulldata = MlContext.Data.LoadFromEnumerable(dataList);
从数据库加载数据 可以使用 SqlConnection 和 SqlCommand 从 SQL 数据库中查询数据,然后将其转化为 IDataView。
1 2 3 4 5 var sqlQuery = "SELECT * FROM MyTable" ;var sqlConnection = new SqlConnection("YourConnectionString" );var sqlCommand = new SqlCommand(sqlQuery, sqlConnection);var reader = sqlCommand.ExecuteReader();var data = mlContext.Data.LoadFromEnumerable(reader);
增量训练 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 public static void TrainAndSaveModel (MLContext mlContext, string newTrainDataPath ){ IDataView fulldata = mlContext.Data.LoadFromTextFile<ZInputData>( path: newTrainDataPath, separatorChar: '\t' , hasHeader: false ); DataOperationsCatalog.TrainTestData trainTestData = mlContext.Data.TrainTestSplit(fulldata, testFraction: 0.1 ); IDataView trainData = trainTestData.TrainSet; IDataView testData = trainTestData.TestSet; EstimatorChain<NormalizingTransformer> dataProcessPipeline = mlContext.Transforms .CustomMapping( new LoadImageConversion().GetMapping(), contractName: "LoadImageConversionAction" ) .Append( mlContext.Transforms.Conversion.MapValueToKey( "Label" , "ResultStr" , keyOrdinality: ValueToKeyMappingEstimator.KeyOrdinality.ByValue ) ) .Append( mlContext.Transforms.NormalizeMeanVariance( outputColumnName: "FeaturesNormalizedByMeanVar" , inputColumnName: "ImagePixels" ) ); LbfgsMaximumEntropyMulticlassTrainer trainer = mlContext.MulticlassClassification.Trainers.LbfgsMaximumEntropy( labelColumnName: "Label" , featureColumnName: "FeaturesNormalizedByMeanVar" ); EstimatorChain<KeyToValueMappingTransformer> trainingPipeline = dataProcessPipeline .Append(trainer) .Append(mlContext.Transforms.Conversion.MapKeyToValue("PredictNumber" , "Label" )); ITransformer trainedModel; string modelPath = ModelPath; if (File.Exists(modelPath)) { trainedModel = mlContext.Model.Load(modelPath, out var modelInputSchema); var newTrainingPipeline = trainingPipeline.Append(trainer); trainedModel = newTrainingPipeline.Fit(trainData); } else { trainedModel = trainingPipeline.Fit(trainData); } IDataView predictions = trainedModel.Transform(testData); MulticlassClassificationMetrics metrics = mlContext.MulticlassClassification.Evaluate( data: predictions, labelColumnName: "Label" , scoreColumnName: "Score" ); PrintMultiClassClassificationMetrics(trainer.ToString(), metrics); mlContext.Model.Save(trainedModel, trainData.Schema, modelPath); List<string > labels = mlContext.Data .CreateEnumerable<ZInputData>(fulldata, reuseRowObject: false ) .Select(x => x.ResultStr) .Distinct() .OrderBy(x => x) .ToList(); Dictionary<int , string > labelMap = labels .Select((label, index) => new { Label = label, Index = index }) .ToDictionary(x => x.Index, x => x.Label); File.WriteAllText(LabelMapPath, JsonConvert.SerializeObject(labelMap)); }
Label数据格式要求 在 Microsoft.ML 中,MulticlassClassification 任务用于处理多类别分类问题。
对于 MulticlassClassification 任务,Label 数据的格式要求如下:
标签通常是从 0 开始的连续非负整数,表示类别的索引。索引从 0 开始。例如,如果有三个类别,标签可以是 0、1 或 2。
并且每个样本的标签必须是一个有效的整数索引。
标签转换
1 2 3 4 5 mlContext.Transforms.Conversion.MapValueToKey( "Label" , "ResultStr" , keyOrdinality: ValueToKeyMappingEstimator.KeyOrdinality.ByValue )
上面的数据转换就是把我们的标签转为Label需要的整数格式。
生成规则ValueToKeyMappingEstimator.KeyOrdinality.ByValue指的是:
按照输入标签出现的顺序进行从0递增生成机器计算的Label。
模型内部并不维护对应关系,需要我们自己维护
1 2 3 4 5 6 List<string > templabelList = MlContext.Data .CreateEnumerable<ZInputData>(fulldata, reuseRowObject: false ) .Select(x => x.ResultStr) .Distinct() .ToList(); File.WriteAllText(LabelListPath, JsonConvert.SerializeObject(templabelList));
特征标准化 下面我将通过一个具体的例子来演示 Transforms.NormalizeMeanVariance 是如何将特征标准化的。
一个包含 Label 和 Feature 列的简单数据集进行标准化处理。
假设原始数据如下:
原始数据
Label
Feature
0
100
1
200
0
300
1
400
标准化的流程
计算 Feature 列的均值(Mean)和方差(Variance)
计算标准差(Standard Deviation)
标准化值
标准化后的数据
Label
Feature (标准化后)
0
-1.34
1
-0.45
0
0.45
1
1.34
总结
通过这个标准化过程,我们将 Feature 列的数据转换为均值为 0,标准差为 1 的分布。
这种标准化使得数据在训练模型时具有相似的尺度,有助于提高模型的训练效果。
训练结果 在多分类(Multiclass Classification)问题中,LogLoss 和 LogLossReduction 是用于评估模型性能的重要指标。
它们主要用于衡量模型在分类任务中的准确性和改进程度。
Log-Loss Log-Loss(对数损失)
定义 :
LogLoss 是一种用于评估分类模型预测准确性的指标。它衡量的是模型预测概率与实际标签之间的差异。
解释 :
LogLoss 越小,表示模型的预测结果越接近真实标签。它反映了模型在预测过程中产生的不确定性。取值范围在理论上是从 0 到正无穷大。
Log-Loss Reduction Log-Loss Reduction(对数损失减少量)
定义 :
LogLossReduction 是一个相对指标,用于衡量模型在改进后的 LogLoss 相比于基线模型(通常是最简单的模型或随机预测)的减少量。
解释 :
LogLossReduction 表示当前模型相比于基线模型在 LogLoss 上的改进百分比。它可以帮助评估模型的改进效果。该指标的值范围通常是 0 到 1,其中 1 表示完全改进(即 LogLoss 从基线减少到 0),0 表示没有改进。
总结
Log-Loss 衡量模型的预测准确性,数值越低表示模型性能越好。Log-Loss Reduction 衡量模型相较于基线模型的改进程度,是一个相对改进的度量,值越大表示模型性能越好。