大数据-相关组件的版本、启动、端口号和访问地址
组件版本
部署的各个服务及版本
| 服务 | 版本 | 说明 |
|---|---|---|
| JDK | 8u221 | JDK8是其他服务启动的基础 |
| Zookeeper | 3.7.1 | 状态保存 |
| Hadoop | 2.7.7 | 较新的版本不太好找找其他服务的兼容版本 |
| Flink | 1.12.7 | 做大数据计算 |
| Hive | 2.1.0 | 数仓使用 |
| Hbase | 2.1.10 | 查询高效的数据库 |
| Phonenix | 5.1.2 | SQL方式操作Hbase |
各服务名
查看
1 | jps |
如图
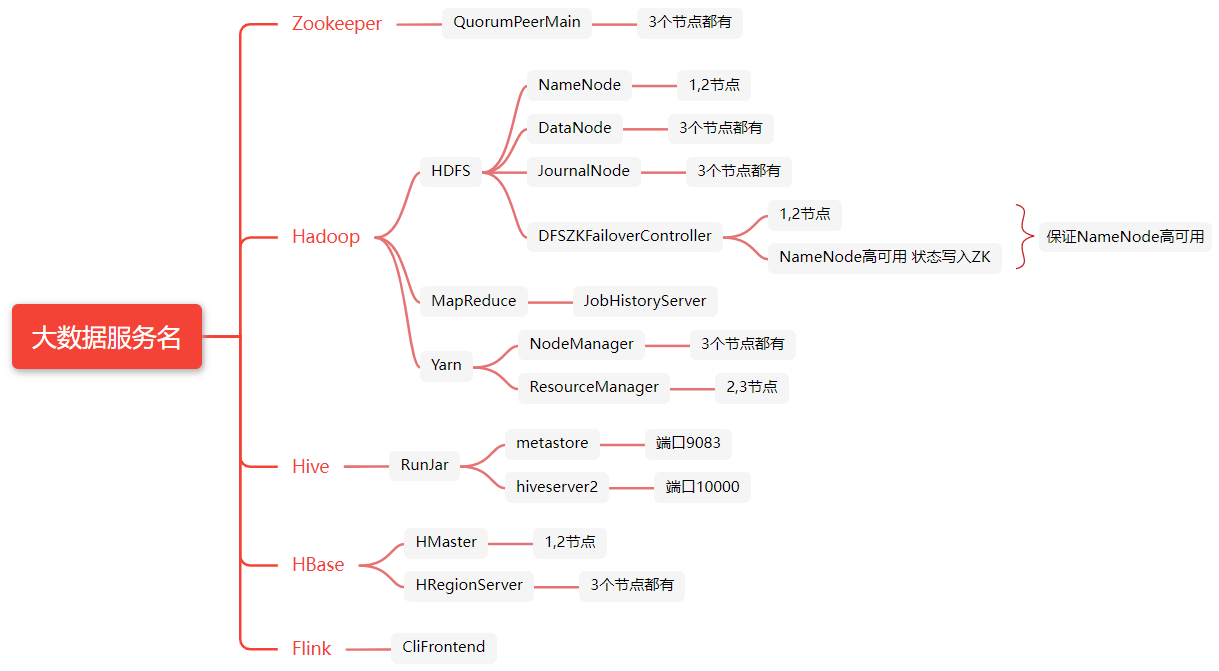
Master可能的进程
| 进程名 | 是否必须 | 所属 | 说明 |
|---|---|---|---|
| QuorumPeerMain | 是 | Zookeeper | 单独配置的Zookeeper集群,如果是内置的则为HQuorumPeer |
| NameNode | 是 | Hadoop-HDFS | Hadoop NameNode |
| DataNode | 是 | Hadoop-HDFS | 提供文件数据的存储服务 |
| JournalNode | 是 | Hadoop-HDFS | 为了使Standby节点保持其状态与Active 节点同步,两个节点都与一组称为”JournalNodes”的单独守护进程进行通信。 |
| DFSZKFailoverController | 是 | Hadoop-HDFS | 高可用时它负责监控NN的状态,并及时的把状态信息写入ZK。 |
| NodeManager | 是 | Hadoop-Yarn | NodeManager是YARN中单个节点上的代理,它管理Hadoop集群中单个计算节点,功能包括与ResourceManager保持通信,管理Container的生命周期,监控每个Container的资源使用(内存,CPU等)情况,追踪节点健康状况,管理日志和不同应用程序用到的附属服务 |
| JobHistoryServer | 否 | Hadoop-Mapreduce | WEB查看作业的历史运行情况,日志存储的位置是在hdfs文件系统中。 |
| RunJar | 否 | Hadoop | |
| HMaster | 是 | Hbase | 表明该Hbase是Master |
| HRegionServer | 否 | Hbase | 因为我们也将该Master设置为Region |
| QueryServer | 否 | Phonenix |
HRegion可能的进程
| 进程名 | 是否必须 | 所属 | 说明 |
|---|---|---|---|
| QuorumPeerMain | 是 | Zookeeper | 单独配置的Zookeeper集群,如果是内置的则为HQuorumPeer |
| DataNode | 是 | Hadoop-HDFS | 数据存储 |
| ResourceManager | 否 | Hadoop-Yarn | |
| NodeManager | 是 | Hadoop-Yarn | |
| HRegionServer | 是 | Hbase | 表明是Hbase存储节点 |
进程名
1 | ha-call.sh "jps -l" |
如下
| 归属 | 进程 |
|---|---|
| Zookeeper | org.apache.zookeeper.server.quorum.QuorumPeerMain |
| Hadoop | org.apache.hadoop.hdfs.tools.DFSZKFailoverController org.apache.hadoop.mapreduce.v2.hs.JobHistoryServer org.apache.hadoop.yarn.server.nodemanager.NodeManager org.apache.hadoop.yarn.server.resourcemanager.ResourceManager org.apache.hadoop.hdfs.server.namenode.NameNode org.apache.hadoop.hdfs.server.datanode.DataNode org.apache.hadoop.hdfs.qjournal.server.JournalNode |
| Hbase | org.apache.hadoop.hbase.master.HMaster org.apache.hadoop.hbase.regionserver.HRegionServer |
查看版本
JDK
1 | java -version |
Zookeeper
1 | zkCli.sh |
Hadoop
1 | hadoop version |
Flink
1 | flink -v |
Hive
1 | hive |
Hbase
1 | hbase version |
配置Host
Windows下host文件配置
C:\Windows\System32\drivers\etc
添加如下
1 | 192.168.7.101 hadoop01 |
Rsync
启动
1 | rsync --daemon --config=/etc/rsyncd.conf |
查看873端口是否起来
1 | netstat -an | grep 873 |
全部启动
Zookeeper
1 | ha-zk.sh start |
查看状态
1 | netstat -an | grep 2181 |
Hadoop
1 | ha-hadoop.sh start |
查看文件可以访问这个地址
http://hadoop01:50070/explorer.html#/
http://hadoop02:50070/explorer.html#/
Yarn监控页面查询:
Hive
启动Hive Metastore
1 | nohup hive --service metastore >/dev/null 2>&1 & |
查看服务是否启动
1 | lsof -i:9083 |
这时候已经可以在服务器上连接了
1 | $HIVE_HOME/bin/hive |
启动hiveserver2
1 | nohup hive --service hiveserver2 >/dev/null 2>&1 & |
或者
1 | nohup $HIVE_HOME/bin/hiveserver2 >/dev/null 2>&1 & |
查看服务是否启动
1 | lsof -i:10000 |
这时可以远程连接了
1 | beeline -n hive -u jdbc:hive2://hadoop01:10000/default |
Hbase
删除之前的日志
1 | ha-call.sh "rm -rf $HBASE_HOME/logs/*" |
Hbase启动
1 | $HBASE_HOME/bin/start-hbase.sh |
查看状态
1 | ha-call.sh "jps" |
访问地址
HMaster 的 Web 接口
HRegionServer 的 Web 接口
Phoenix
使用瘦客户端的时候才需要启动。
胖客户端不需要启动。
1 | queryserver.py start |
Flink
Yarn Session模式
1 | $FLINK_HOME/bin/yarn-session.sh -d -nm zflink |
查看运行状态
http://hadoop01:8088/cluster/apps/RUNNING
一键启动
ha-all-start.sh
1 |
|
全部停止
Flink
Yarn Session模式
查看
http://hadoop01:8088/cluster/apps
结束服务
1 | yarn application -kill appid |
Phoenix
胖客户端模式不用启动也不用停止。
1 | queryserver.py stop |
Hbase
1 | $HBASE_HOME/bin/stop-hbase.sh |
Hive
结束之前的服务
1 | jobs |
结束任务
1 | # 通过jobs命令查看job号(假设为num,num从1开始) |
或者
1 | lsof -i:10000 -t | xargs -I {} kill -9 {} && lsof -i:10000 |
Hadoop
1 | ha-hadoop.sh stop |
Zookeeper
1 | ha-zk.sh stop |
一键停止
ha-all-stop.sh
1 |
|
查看
1 | ha-call.sh "jps -l" |
开启关闭Yarn-Session
查看启动的ApplicationID
1 | yarn application -list | grep -o "application_[0-9]*_[0-9]*" |
结束
1 | yarn application -list | grep -o "application_[0-9]*_[0-9]*" | xargs -I {} yarn application -kill {} |
这条命令首先执行 yarn application -list 来列出所有正在运行的应用程序信息,
然后通过管道将输出传递给 grep 命令,使用正则表达式 "application_[0-9]*_[0-9]*" 来提取应用程序的 ID。
然后,管道将提取的应用程序 ID 传递给 xargs 命令,并使用 -I {} 选项指定占位符 {} 来表示每个应用程序 ID。
最后,xargs 命令将每个应用程序 ID 替换到 yarn application -kill {} 命令中,以停止相应的应用程序。
请注意,这个命令会停止匹配的所有应用程序,并且没有进一步的确认提示。
在使用此命令之前,请确保你要停止的应用程序是正确的,并且理解可能产生的影响。
查看
1 | yarn application -list |
启动
1 | $FLINK_HOME/bin/yarn-session.sh -d -nm zflink |
JPS操作
查看
1 | jps |
查看包及类
1 | jps -l |
查看启动参数(依赖Jar和内存)
1 | jps -v |
终止所有JPS进程
终止所有的hadoop进程
1 | ha-call.sh "jps -l|grep 'org.apache.hadoop'|awk '{print $1}' |xargs kill -9" |
终止所有的Hbase进程
1 | ha-call.sh "jps -l|grep 'org.apache.hadoop.hbase'|awk '{print $1}' |xargs kill -9" |
各环境基本操作
Zookeeper
启动ZK
1 | ha-zk.sh start |
端口2181
连接
1 | zkCli.sh |
输入命令
1 | #查看zk的根目录kafka相关节点 |
Hadoop
启动前要先启动ZK。
HDFS监控页面查询:
查看文件可以访问这个地址
http://hadoop01:50070/explorer.html#/
http://hadoop02:50070/explorer.html#/
Yarn监控页面查询:
连接具体的NameNode需要用9000端口
1 | hdfs://hdfsns/hbase |
Flink
Flink有个UI界面,可以用于监控Flilnk的job运行状态
http://hadoop01:8081/
Hive
结束之前的服务
1 | jobs |
结束任务
1 | # 通过jobs命令查看job号(假设为num) |
数据库初始化
这个只执行一次
Hive的数据库MySQL在安装的时候没有初始化
在MySQL中
1 | # 删除mysql中的元数据库 |
命令行中执行
1 | # 在命令行中,重新初始化 |
启动Hive Metastore
1 | nohup hive --service metastore >/dev/null 2>&1 & |
启动Hive
1 | $HIVE_HOME/bin/hive |
查询表
1 | show tables; |
启动Hive远程服务
远程连接要启动下面的服务
1 | jdbc:hive2://hadoop01:10000 |
启动远程服务
1 | nohup $HIVE_HOME/bin/hiveserver2& |
查看服务是否启动
1 | lsof -i:10000 |
HBase
HMaster 的 Web 接口
HRegionServer 的 Web 接口
两个重要配置
在HDFS中的Path和ZK中的Path
1 | <property> |
注意
hbase.zookeeper.quorum中不能添加端口号
连接
1 | hbase shell |
创建表
1 | create 'student','s_name','s_sex','s_age','s_dept','s_course' |
查看表详情
1 | describe 'student' |
显示所有的表
1 | list |
插入数据
1 | put 'student','95001','s_name','LiYing' |
查看表数据
1 | scan 'student', {FORMATTER => 'toString'} |
重启
1 | $HBASE_HOME/bin/stop-hbase.sh |
查看服务
1 | ha-call.sh "jps" |
Phoenix
注意
在Phoenix中无论表还是字段只要没有双引号引起来的字段都会变成大写。
这里不建议用双引号,在后期拼接SQL的时候比较麻烦。
启动query server
1 | queryserver.py start |
连接
1 | sqlline-thin.py http://hadoop01:8765 |
创建schema
1 | create schema mdb; |
使用这个新建的 schema:
1 | use mdb; |
创建表
1 | CREATE TABLE IF NOT EXISTS tuser( |
插入数据
1 | upsert into tuser values('1001','zhangsan'); |
查询记录
1 | select * from tuser; |
分页查询
1 | select * from tuser order by id desc limit 1 offset 0; |
其中
limit取多少条offset从多少条开始