前言 CentOS下载地址
http://mirrors.aliyun.com/centos/7/isos/x86_64/
本地安装了Docker和VMware后,无法同时启动。
因为Docker和VMware都相当于Hypervisor,并且基于虚拟机属性需要获取对CPU等硬件的掌控权,因为在同一台机器上无法同时运行。
使用”添加或删除Windows组件“图形界面程序,在里面取消勾选Hyper-V。
取消之后要重启电脑,否则不生效。
注意
其他环境的高可用集群前提是Zookeeper的集群
本文所有的大数据软件都放在了下面的文件夹中
/data/tools/bigdata
服务器准备至少3台
1 2 3 192.168.7.101(hadoop01) 192.168.7.102(hadoop02) 192.168.7.103(hadoop03)
查看主机名
Taier
文档:https://dtstack.github.io/Taier/docs/guides/introduction/
视频:https://www.bilibili.com/video/BV13L4y1L71w/
源码:https://github.com/DTStack/Taier
本文软件环境
JDK 8u221
zookeeper 3.7.1
Hadoop 2.7.7
Flink 1.12.7
安装JDK 官方下载JDK 网址
或者 链接:https://pan.baidu.com/s/1JdPCMMEq178hXV5V4Ild3Q 密码:03l1
比如下载的文件为jdk-8u221-linux-x64.rpm
更改文件权限
1 chmod 755 jdk-8u221-linux-x64.rpm
安装
1 rpm -ivh jdk-8u221-linux-x64.rpm
安装后的路径为/usr/java/jdk1.8.0_221-amd64
删除文件
1 rm -rf jdk-8u221-linux-x64.rpm
查询Java版本
查看JAVA_HOME
添加环境变量
创建配置文件
1 vi /etc/profile.d/jdk.sh
加入:
1 2 3 export JAVA_HOME=/usr/java/jdk1.8.0_221-amd64 export PATH=$JAVA_HOME /bin:$PATH export CLASSPATH=.:$JAVA_HOME /lib/dt.jar:$JAVA_HOME /lib/tools.jar
配置立即生效
查询java版本
查看java-home
创建目录 1 2 3 ssh hadoop01 "mkdir -p /data/tools/bigdata" ssh hadoop02 "mkdir -p /data/tools/bigdata" ssh hadoop03 "mkdir -p /data/tools/bigdata"
Zookeeper集群 集群最少为3个。
安装Zookeeper kafka依赖zookeeper,安装包内已内置 使用内置的可以跳过该步骤
也可自己单独下载
https://zookeeper.apache.org/releases.html#download
我这里下载的是apache-zookeeper-3.7.1-bin.tar.gz
解压
1 2 tar -zxvf apache-zookeeper-3.7.1-bin.tar.gz -C /data/tools/bigdata/ cd /data/tools/bigdata/apache-zookeeper-3.7.1-bin
配置环境变量 添加环境变量
创建配置文件
加入:
1 2 export ZK_HOME=/data/tools/bigdata/apache-zookeeper-3.7.1-bin export PATH=$ZK_HOME /bin:$PATH
配置立即生效
查看ZK_HOME
创建目录 1 2 mkdir -p /data/tools/bigdata/zdata/zk_datamkdir -p /data/tools/bigdata/zdata/zk_logs
另两台创建目录
1 2 3 4 ssh hadoop02 "mkdir -p /data/tools/bigdata/zdata/zk_data" ssh hadoop02 "mkdir -p /data/tools/bigdata/zdata/zk_logs" ssh hadoop03 "mkdir -p /data/tools/bigdata/zdata/zk_data" ssh hadoop03 "mkdir -p /data/tools/bigdata/zdata/zk_logs"
配置修改 conf配置目录下的zoo_sample.cfg修改为zoo.cfg
修改
1 2 dataDir=/data/tools/bigdata/zdata/zk_data dataLogDir=/data/tools/bigdata/zdata/zk_logs
添加
1 2 3 4 5 server.1=hadoop01:2888:3888 server.2=hadoop02:2888:3888 server.3=hadoop03:2888:3888
分别在三台主机的 dataDir 目录下新建 myid 文件,并写入对应的节点标识。Zookeeper 集群通过 myid 文件识别集群节点,并通过上文配置的节点通信端口和选举端口来进行节点通信,选举出 Leader 节点。
创建并写入节点标识到 myid 文件:
1 2 3 ssh hadoop01 "echo 1 > /data/tools/bigdata/zdata/zk_data/myid" ssh hadoop02 "echo 2 > /data/tools/bigdata/zdata/zk_data/myid" ssh hadoop03 "echo 3 > /data/tools/bigdata/zdata/zk_data/myid"
配置分发 启动ZK 启动ZK
1 bash $ZK_HOME /bin/zkServer.sh start
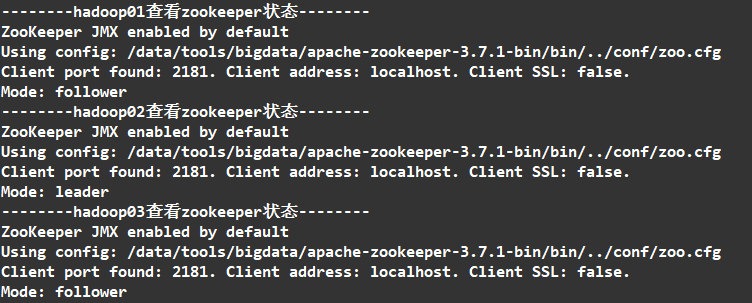
查看状态
或者
用自定义脚本
1 2 ha-zk.sh start ha-zk.sh status
全部启动成功后我们可以看到
1个leader,2个follower,就说明集群配置成功了。
访问 进入
1 bash $ZK_HOME /bin/zkCli.sh
输入命令
1 2 3 4 5 6 7 8 9 ls / ls /brokersls /brokers/topics create /zk "test" set /zk "zkbak" get /zk
使用到的端口 搭建集群时配置文件zoo.cfg中会出现这样的配置
1 2 3 4 clientPort=2181 server.1 =hadoop01:2888 :3888 server.2 =hadoop02:2888 :3888 server.3 =hadoop03:2888 :3888
其中
Hadoop集群 下载 https://archive.apache.org/dist/hadoop/common/hadoop-2.7.7/
解压
1 2 tar -zxvf hadoop-2.7.7.tar.gz -C /data/tools/bigdata/ cd /data/tools/bigdata/hadoop-2.7.7
配置环境变量 创建配置文件
1 vi /etc/profile.d/hadoop.sh
内容设置为
1 2 3 4 5 6 7 export HADOOP_HOME=/data/tools/bigdata/hadoop-2.7.7export YARN_CONF_DIR=$HADOOP_HOME /etc/hadoopexport HADOOP_CONF_DIR=$HADOOP_HOME /etc/hadoopexport PATH=$PATH :$HADOOP_HOME /binexport PATH=$PATH :$HADOOP_HOME /sbinexport HADOOP_CLASSPATH=`hadoop classpath`
配置生效
查看是否生效
1 2 3 echo $HADOOP_HOME echo $YARN_CONF_DIR echo $HADOOP_CONF_DIR
环境变量分发
1 2 3 4 ha-fenfa.sh /etc/profile.d ssh hadoop02 "source /etc/profile" ssh hadoop03 "source /etc/profile"
修改配置文件 进入配置文件目录
1 cd $HADOOP_HOME /etc/hadoop
hadoop-env.sh 将原本的JAVA_HOME 替换为绝对路径就可以了
1 2 3 export JAVA_HOME=/usr/java/jdk1.8.0_221-amd64
注意
虽然系统已经设置JAVA_HOME,但是运行时依旧无法找到,所以配置的绝对路径
一定要配置,否则会产生运行正常,但是远程连接服务器的时候报Error:JAVA_HOME is not set and could not be found
core-site.xml 注意文件的编码要是utf8
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 <?xml version="1.0" encoding="UTF-8" ?> <?xml-stylesheet type="text/xsl" href="configuration.xsl" ?> <configuration > <property > <name > fs.defaultFS</name > <value > hdfs://hdfsns</value > </property > <property > <name > hadoop.tmp.dir</name > <value > file:///data/tools/bigdata/zdata/hadoop/tmp</value > </property > <property > <name > io.file.buffer.size</name > <value > 4096</value > </property > <property > <name > ha.zookeeper.quorum</name > <value > hadoop01:2181,hadoop02:2181,hadoop03:2181</value > </property > </configuration >
hdfs-site.xml 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 <?xml version="1.0" encoding="UTF-8" ?> <?xml-stylesheet type="text/xsl" href="configuration.xsl" ?> <configuration > <property > <name > dfs.block.size</name > <value > 134217728</value > </property > <property > <name > dfs.replication</name > <value > 3</value > </property > <property > <name > dfs.name.dir</name > <value > file:///data/tools/bigdata/zdata/hadoop/dfs/namenode_data</value > </property > <property > <name > dfs.data.dir</name > <value > file:///data/tools/bigdata/zdata/hadoop/dfs/datanode_data</value > </property > <property > <name > dfs.webhdfs.enabled</name > <value > true</value > </property > <property > <name > dfs.datanode.max.transfer.threads</name > <value > 4096</value > </property > <property > <name > dfs.nameservices</name > <value > hdfsns</value > </property > <property > <name > dfs.ha.namenodes.hdfsns</name > <value > nn1,nn2</value > </property > <property > <name > dfs.namenode.rpc-address.hdfsns.nn1</name > <value > hadoop01:9000</value > </property > <property > <name > dfs.namenode.servicepc-address.hdfsns.nn1</name > <value > hadoop01:53310</value > </property > <property > <name > dfs.namenode.http-address.hdfsns.nn1</name > <value > hadoop01:50070</value > </property > <property > <name > dfs.namenode.rpc-address.hdfsns.nn2</name > <value > hadoop02:9000</value > </property > <property > <name > dfs.namenode.servicepc-address.hdfsns.nn2</name > <value > hadoop02:53310</value > </property > <property > <name > dfs.namenode.http-address.hdfsns.nn2</name > <value > hadoop02:50070</value > </property > <property > <name > dfs.namenode.shared.edits.dir</name > <value > qjournal://hadoop01:8485;hadoop02:8485;hadoop03:8485/hdfsns</value > </property > <property > <name > dfs.journalnode.edits.dir</name > <value > /data/tools/bigdata/zdata/hadoop/dfs/journalnode_data</value > </property > <property > <name > dfs.namenode.edits.dir</name > <value > /data/tools/bigdata/zdata/hadoop/dfs/edits</value > </property > <property > <name > dfs.ha.automatic-failover.enabled</name > <value > true</value > </property > <property > <name > dfs.client.failover.proxy.provider.hdfsns</name > <value > org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value > </property > <property > <name > dfs.ha.fencing.methods</name > <value > sshfence</value > </property > <property > <name > dfs.ha.fencing.ssh.private-key-files</name > <value > /root/.ssh/id_rsa</value > </property > <property > <name > dfs.permissions</name > <value > false</value > </property > </configuration >
mapred-site.xml mapred-site.xml.template 重命名为 mapred-site.xml
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 <?xml version="1.0" ?> <?xml-stylesheet type="text/xsl" href="configuration.xsl" ?> <configuration > <property > <name > mapreduce.framework.name</name > <value > yarn</value > </property > <property > <name > mapreduce.jobhistory.address</name > <value > hadoop01:10020</value > </property > <property > <name > mapreduce.jobhistory.webapp.address</name > <value > hadoop01:19888</value > </property > <property > <name > mapreduce.job.ubertask.enable</name > <value > true</value > </property > </configuration >
yarn-site.xml 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 <?xml version="1.0" ?> <configuration > <property > <name > yarn.nodemanager.vmem-check-enabled</name > <value > false</value > </property > <property > <name > yarn.resourcemanager.ha.enabled</name > <value > true</value > </property > <property > <name > yarn.resourcemanager.cluster-id</name > <value > hayarn</value > </property > <property > <name > yarn.resourcemanager.ha.rm-ids</name > <value > rm1,rm2</value > </property > <property > <name > yarn.resourcemanager.hostname.rm1</name > <value > hadoop02</value > </property > <property > <name > yarn.resourcemanager.hostname.rm2</name > <value > hadoop03</value > </property > <property > <name > yarn.resourcemanager.zk-address</name > <value > hadoop01:2181,hadoop02:2181,hadoop03:2181</value > </property > <property > <name > yarn.resourcemanager.recovery.enabled</name > <value > true</value > </property > <property > <name > yarn.resourcemanager.store.class</name > <value > org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value > </property > <property > <name > yarn.resourcemanager.hostname</name > <value > hadoop03</value > </property > <property > <name > yarn.nodemanager.aux-services</name > <value > mapreduce_shuffle</value > </property > <property > <name > yarn.log-aggregation-enable</name > <value > true</value > </property > <property > <name > yarn.log-aggregation.retain-seconds</name > <value > 604800</value > </property > <property > <name > yarn.resourcemanager.am.max-attempts</name > <value > 4</value > </property > <property > <name > yarn.scheduler.maximum-allocation-mb</name > <value > 2048</value > </property > <property > <name > yarn.nodemanager.resource.memory-mb</name > <value > 2048</value > </property > </configuration >
注意其中下面的配置项可以不用配置
1 2 3 4 <property > <name > yarn.nodemanager.vmem-check-enabled</name > <value > false</value > </property >
配置说明
是否启动一个线程检查每个任务正使用的虚拟内存量,如果任务超出分配值,则直接将其杀掉,默认是true。
slaves 1 2 3 hadoop01 hadoop02 hadoop03
log4j.properties 剔除警告(可选):
添加
1 log4j.logger.org.apache.hadoop.util.NativeCodeLoader=ERROR
问题
Could not deploy Yarn job cluster
解决:修改内存大小设置
yarn.scheduler.maximum-allocation-mb
yarn.nodemanager.resource.memory-mb
yarn-site.xml
默认的值
1 2 3 4 5 6 7 8 9 <property > <name > yarn.scheduler.maximum-allocation-mb</name > <value > 8192</value > </property > <property > <name > yarn.nodemanager.resource.memory-mb</name > <value > 8192</value > </property >
可以修改为
1 2 3 4 5 6 7 8 9 <property > <name > yarn.scheduler.maximum-allocation-mb</name > <value > 2048</value > </property > <property > <name > yarn.nodemanager.resource.memory-mb</name > <value > 2048</value > </property >
删除日志 刚开始部署时每次启动前我们可以删除之前的日志文件,方便排查问题。
1 ha-call.sh "rm -rf $HADOOP_HOME /logs/*"
配置分发 1 ha-fenfa.sh $HADOOP_HOME
初始化集群
只用执行一次
(1). 启动3个Zookeeper
已启动则跳过
1 ha-call.sh "zkServer.sh start"
(2). 启动3个JournalNode
JournalNode的作用:NameNode之间共享数据
1 ha-call.sh "hadoop-daemon.sh start journalnode"
(3). 格式化NameNode
格式化前删除之前的文件
1 ha-call.sh "rm -rf /data/tools/bigdata/zdata/hadoop/*"
添加文件夹
1 2 3 4 5 ha-call.sh "mkdir -p /data/tools/bigdata/zdata/hadoop/tmp" ha-call.sh "mkdir -p /data/tools/bigdata/zdata/hadoop/dfs/journalnode_data" ha-call.sh "mkdir -p /data/tools/bigdata/zdata/hadoop/dfs/edits" ha-call.sh "mkdir -p /data/tools/bigdata/zdata/hadoop/dfs/datanode_data" ha-call.sh "mkdir -p /data/tools/bigdata/zdata/hadoop/dfs/namenode_data"
仅hadoop01
1 2 3 sudo chmod -R 755 /data/tools/bigdata/zdata/hadoophdfs namenode -format
这个操作主要是创建fsimage和edits文件。
只要看到信息中有一句关键:
22/11/08 08:53:30 INFO common.Storage: Storage directory /data/tools/bigdata/zdata/hadoop/dfs/namenode_data has been successfully formatted.
则格式化成功.
(4). 复制hadoop01上的NameNode的元数据到hadoop02
1 scp -r /data/tools/bigdata/zdata/hadoop/dfs/namenode_data/current/ root@hadoop02:/data/tools/bigdata/zdata/hadoop/dfs/namenode_data/
(5). 在NameNode节点(hadoop01或hadoop02)格式化zkfc
1 ssh hadoop01 "hdfs zkfc -formatZK"
(6). 停止3个JournalNode
JournalNode的作用:NameNode之间共享数据
1 ha-call.sh "hadoop-daemon.sh stop journalnode"
启动集群 可以删除之前的日志文件,方便排查问题。
1 ha-call.sh "rm -rf $HADOOP_HOME /logs/*"
(1). 在hadoop01上启动HDFS相关服务
1 ssh hadoop01 "start-dfs.sh"
对应日志
1 2 3 4 5 6 7 8 9 10 11 Starting namenodes on [hadoop01 hadoop02] hadoop01: starting namenode, logging to /data/tools/bigdata/hadoop-2.7.7/logs/hadoop-root-namenode-hadoop01.out hadoop02: starting namenode, logging to /data/tools/bigdata/hadoop-2.7.7/logs/hadoop-root-namenode-hadoop02.out localhost: starting datanode, logging to /data/tools/bigdata/hadoop-2.7.7/logs/hadoop-root-datanode-hadoop01.out Starting journal nodes [hadoop01 hadoop02 hadoop03] hadoop03: starting journalnode, logging to /data/tools/bigdata/hadoop-2.7.7/logs/hadoop-root-journalnode-hadoop03.out hadoop02: starting journalnode, logging to /data/tools/bigdata/hadoop-2.7.7/logs/hadoop-root-journalnode-hadoop02.out hadoop01: starting journalnode, logging to /data/tools/bigdata/hadoop-2.7.7/logs/hadoop-root-journalnode-hadoop01.out Starting ZK Failover Controllers on NN hosts [hadoop01 hadoop02] hadoop02: starting zkfc, logging to /data/tools/bigdata/hadoop-2.7.7/logs/hadoop-root-zkfc-hadoop02.out hadoop01: starting zkfc, logging to /data/tools/bigdata/hadoop-2.7.7/logs/hadoop-root-zkfc-hadoop01.out
(2). 在hadoop03上启动YARN相关服务
1 ssh hadoop03 "start-yarn.sh"
(3). 最后单独启动hadoop01的历史任务服务器和hadoop02的ResourceManager
1 2 ssh hadoop01 "mr-jobhistory-daemon.sh start historyserver" ssh hadoop02 "yarn-daemon.sh start resourcemanager"
或者
用自定义脚本
1 2 3 ha-hadoop.sh start ha-hadoop.sh status ha-hadoop.sh stop
查看集群 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 --------hadoop01查看ha-hadoop集群进程-------- 15921 Jps 15366 NodeManager 14807 DataNode 15002 JournalNode 15195 DFSZKFailoverController 1806 QuorumPeerMain 15294 JobHistoryServer 14703 NameNode --------hadoop02查看ha-hadoop集群进程-------- 14432 ResourceManager 1271 QuorumPeerMain 14055 NameNode 15289 Jps 14220 JournalNode 14348 DFSZKFailoverController 14125 DataNode 14509 NodeManager --------hadoop03查看ha-hadoop集群进程-------- 14163 ResourceManager 14039 JournalNode 13944 DataNode 14635 Jps 1260 QuorumPeerMain
【查看NameNode的状态】
1 2 hdfs haadmin -getServiceState nn1 hdfs haadmin -getServiceState nn2
可以看到一个是active一个是standby
【查看ResourceManager的状态】
1 2 yarn rmadmin -getServiceState rm1 yarn rmadmin -getServiceState rm2
可以看到一个是active一个是standby
访问 我的服务器的IP为 192.168.7.101
HDFS监控页面查询:
http://192.168.7.101:50070/
http://192.168.7.102:50070/
查看文件可以访问这个地址
http://192.168.7.101:50070/explorer.html#/
http://192.168.7.102:50070/explorer.html#/
Yarn监控页面查询:
http://192.168.7.102:8088/cluster
http://192.168.7.103:8088/cluster
Flink on Yarn 默认情况下,每个 Flink 集群只有一个 JobManager,这将导致单点故障(SPOF),如果这个 JobManager 挂了,则不能提交新的任务,并且运行中的程序也会失败。使用JobManager HA,集群可以从 JobManager 故障中恢复,从而避免单点故障。
用户可以在Standalone 或 Flink on Yarn 集群模式下配置 Flink 集群 HA(高可用性)。
下载 下载地址
https://archive.apache.org/dist/flink/
这里下载1.12.7版本
https://archive.apache.org/dist/flink/flink-1.12.7/
https://archive.apache.org/dist/flink/flink-1.12.7/flink-1.12.7-bin-scala_2.12.tgz
解压
1 tar zxvf flink-1.12.7-bin-scala_2.12.gz -C /data/tools/bigdata/
配置环境变量 创建配置文件
1 vi /etc/profile.d/flink.sh
内容设置为
1 2 3 export FLINK_HOME=/data/tools/bigdata/flink-1.12.7export PATH=$PATH :$FLINK_HOME /bin
配置生效
查看是否生效
创建目录 1 mkdir -p /data/tools/bigdata/zdata/flink
其他服务器上创建文件夹
1 2 3 ssh hadoop02 "mkdir -p /data/tools/bigdata/zdata/flink" ssh hadoop03 "mkdir -p /data/tools/bigdata/zdata/flink"
Hadoop中创建目录 1 2 3 4 5 hdfs dfs -mkdir /flink112 hdfs dfs -mkdir /flink112/ha/ hdfs dfs -mkdir /flink112/completed-jobs hdfs dfs -mkdir /flink112/flink-checkpoints hdfs dfs -mkdir /flink112/flink-savepoints
修改配置 Hadoop中
yarn-site.xml添加
1 2 3 4 <property > <name > yarn.resourcemanager.am.max-attempts</name > <value > 4</value > </property >
hadoop配置分发
1 ha-fenfa.sh $HADOOP_HOME
修改flink/conf/
flink-conf.yaml
masters
workers
flink-conf.yaml
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 jobmanager.rpc.address: hadoop01 jobmanager.rpc.port: 6123 taskmanager.memory.process.size: 1728m jobmanager.memory.process.size: 1600m jobmanager.archive.fs.dir: hdfs://hdfsns/flink112/completed-jobs taskmanager.numberOfTaskSlots: 4 parallelism.default: 4 state.backend: filesystem state.backend.fs.checkpointdir: hdfs://hdfsns/flink112/flink-checkpoints state.savepoints.dir: hdfs://hdfsns/flink112/flink-savepoints high-availability: zookeeper high-availability.zookeeper.quorum: hadoop01:2181,hadoop02:2181,hadoop03:2181 high-availability.zookeeper.path.root: /flink112 high-availability.storageDir: hdfs://hdfsns/flink112/ha/ high-availability.zookeeper.client.acl: open
如果使用Yarn
添加
1 yarn.application-attempts: 10
masters
1 2 hadoop01:8081 hadoop02:8081
workers
1 2 3 hadoop01 hadoop02 hadoop03
zoo.cfg
将内容修改为:
1 2 3 4 dataDir=/data/tools/bigdata/zdata/flink server.1=hadoop01:2888:3888 server.2=hadoop02:2888:3888 server.3=hadoop03:2888:3888
作业归档需要记录在hdfs上,但是当前版本的flink把hadoop的一些依赖删除了,需要手动将jar包放到lib目录下 ,这里我用的是
https://repo.maven.apache.org/maven2/org/apache/flink/flink-shaded-hadoop-2-uber/
下载地址
https://repo.maven.apache.org/maven2/org/apache/flink/flink-shaded-hadoop-2-uber/2.7.5-10.0/flink-shaded-hadoop-2-uber-2.7.5-10.0.jar
删除日志 刚开始部署时每次启动前我们可以删除之前的日志文件,方便排查问题。
1 ha-call.sh "rm -rf $FLINK_HOME /logs/*"
配置分发 启动/停止 创建一个YARN模式的flink集群:
1 bash $FLINK_HOME /bin/yarn-session.sh -n 4 -jm 1024m -tm 4096m --detached
申请资源
1 bash $FLINK_HOME /bin/yarn-session.sh -nm mytest -n 2
查看申请的资源
启动
1 bash $FLINK_HOME /bin/start-cluster.sh
停止
1 bash $FLINK_HOME /bin/stop-cluster.sh
或者
用自定义脚本
1 2 3 ha-flink.sh start ha-flink.sh status ha-flink.sh stop
Master应该有StandaloneSessionClusterEntrypoint
Slave应该有TaskManagerRunner
访问 Flink有个UI界面,可以用于监控Flilnk的job运行状态http://192.168.7.101:8081/
运行Jar 1 2 3 hdfs://hdfsns/bigdata_study/stu_list.txt hdfs://192.168.7.102:9000/bigdata_study/stu_list.txt
1 flink run -m yarn-cluster -ynm mytest ./WordCount.jar "hdfs://hdfsns/bigdata_study/stu_list.txt"
Docker 安装 搜索
安装
启动
查看版本
开机自启
修改默认路径
停止服务
修改配置
指定镜像和容器存放路径的参数是--graph=/var/lib/docker
位置 /etc/sysconfig/docker 添加下面这行
1 vi /etc/sysconfig/docker
修改
1 OPTIONS='--selinux-enabled --log-driver=journald --signature-verification=false'
修改为
1 OPTIONS='--graph=/data/tools/docker --selinux-enabled --log-driver=journald --signature-verification=false'
修改完成后重载配置文件
1 sudo systemctl daemon-reload
重启docker服务
1 sudo systemctl restart docker.service
查看信息
1 sudo docker info | grep "Docker Root Dir"
出现以下则证明成功了
1 Docker Root Dir: /data/tools/docker
设置镜像源 针对Docker客户端版本大于 1.10.0 的用户
创建或修改 /etc/docker/daemon.json 文件
1 vi /etc/docker/daemon.json
添加或修改
1 2 3 4 5 6 7 { "registry-mirrors" : [ "https://docker.mirrors.ustc.edu.cn/" , "https://hub-mirror.c.163.com" , "https://registry.docker-cn.com" ] }
重启Docker
1 2 systemctl daemon-reload systemctl restart docker.service
docker-compose 下载docker-compose:
1 curl -L https://get.daocloud.io/docker/compose/releases/download/1.25.4/docker-compose-`uname -s`-`uname -m` > /usr/local/bin/docker-compose
然后赋权限:
1 chmod +x /usr/local/bin/docker-compose
最后查看版本:
Taier部署 解压依赖 1 2 3 4 5 6 yum install unzip -y unzip DatasourceX.zip -d /data/tools/bigdata/taier/ cd /data/tools/bigdata/taier/pluginLibsmkdir -p /data/tools/bigdata/taier/chunjuntar -zxvf chunjun-dist.tar.gz -C /data/tools/bigdata/taier/chunjun
运行 通过docker-compose启动
docker-compose.yml
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 version: '3' services: taier-db: image: dtopensource/taier-mysql:1.2 environment: MYSQL_DATABASE: taier MYSQL_ROOT_PASSWORD: 123456 taier-zk: image: zookeeper:3.4.9 taier-ui: image: dtopensource/taier-ui:1.2 ports: - 80 :80 environment: TAIER_IP: taier TAIER_PORT: 8090 taier: image: dtopensource/taier:1.2 environment: ZK_HOST: taier-zk ZK_PORT: 2181 DB_HOST: taier-db DB_PORT: 3306 DB_ROOT: root DB_PASSWORD: 123456 DATASOURCEX_PATH: /usr/taier/datasourcex volumes: - /data/tools/bigdata/taier/pluginLibs:/usr/taier/datasourcex - /data/tools/bigdata/flink-1.12.7/lib:/data/insight_plugin1.12/flink_lib - /data/tools/bigdata/taier/chunjun/chunjun-dist:/data/insight_plugin1.12/chunjunplugin
进入docker-compose目录,执行
查看服务
查看配置的插件是否生效
1 2 3 4 5 6 docker exec -t -i taier_taier_1 /bin/bash cd /usr/taier/datasourcexls exit
查看日志
停止服务
访问 当命令执行完成后,在浏览器上直接访问
http://192.168.7.101/
用户名密码:
修改host 1 docker exec -it taier_taier_1 /bin/bash
修改hosts
添加
1 2 3 192.168.7.101 hadoop01 192.168.7.102 hadoop02 192.168.7.103 hadoop03
配置 SFTP 配置后要创建/data/sftp文件夹才能连通。
Flink
键
值
high-availability
zookeeper
high-availability.zookeeper.quorum
hadoop01:2181,hadoop02:2181,hadoop03:2181
high-availability.zookeeper.path.root
/flink112
high-availability.storageDir
hdfs://hdfsns/flink112/ha/
状态存储
键
值
state.backend
filesystem
state.backend.fs.checkpointdir
hdfs://hdfsns/flink112/flink-checkpoints
state.savepoints.dir
hdfs://hdfsns/flink112/flink-savepoints
任务管理
键
值
jobmanager.archive.fs.dir
hdfs://hdfsns/flink112/completed-jobs
Jar目录
键
值
本地路径
flinkLibDir
/data/insight_plugin1.12/flink_lib
/data/tools/bigdata/flink-1.12.7/lib
chunjunDistDir
/data/insight_plugin1.12/chunjunplugin
/data/tools/bigdata/taier/chunjun/chunjun-dist
remoteFlinkLibDir
/data/insight_plugin1.12/flink_lib
/data/tools/bigdata/flink-1.12.7/lib
remoteChunjunDistDir
/data/insight_plugin1.12/chunjunplugin
/data/tools/bigdata/taier/chunjun/chunjun-dist
prometheus:不用配置 Prometheus是一个开源的系统监控和报警系统
metrics:不用配置 用于检测 jvm 上后端服务的运行状况
访问地址汇总 Hadoop HDFS监控页面查询:
http://192.168.7.101:50070/
查看文件可以访问这个地址
http://192.168.7.101:50070/explorer.html#/
Yarn监控页面查询:
http://192.168.7.102:8088/cluster
Flink 监控Flilnk的job运行状态http://192.168.7.101:8081/
Taier http://192.168.7.101/
用户名密码:
数据同步 Mysql 1 jdbc:mysql://192.168.7.102:3306/ztest?characterEncoding=utf8&zeroDateTimeBehavior=convertToNull&rewriteBatchedStatements=true &allowMultiQueries=true
允许远程登录 1 2 3 GRANT ALL PRIVILEGES ON *.* TO 'root' @'%' IDENTIFIED BY 'psvmc123' WITH GRANT OPTION; FLUSH PRIVILEGES; quit
设置密码永不过期 1 2 ALTER USER 'root' @'%' PASSWORD EXPIRE NEVER; flush privileges;