前言 一个典型的机器学习过程从数据收集开始,要经历多个步骤,才能得到需要的输出。这非常类似于流水线式工作,即通常会包含源数据ETL(抽取、转化、加载),数据预处理,指标提取,模型训练与交叉验证,新数据预测等步骤。
在介绍工作流之前,我们先来了解几个重要概念:
DataFrame:使用Spark SQL中的DataFrame作为数据集,它可以容纳各种数据类型。
较之 RDD,包含了 schema 信息,更类似传统数据库中的二维表格。
它被 ML Pipeline 用来存储源数据。例如,DataFrame中的列可以是存储的文本,特征向量,真实标签和预测的标签等。
Transformer:翻译成转换器,是一种可以将一个DataFrame转换为另一个DataFrame的算法。
比如一个模型就是一个 Transformer。它可以把 一个不包含预测标签的测试数据集 DataFrame 打上标签,转化成另一个包含预测标签的 DataFrame。
技术上,Transformer实现了一个方法transform(),它通过附加一个或多个列将一个DataFrame转换为另一个DataFrame。
Estimator:翻译成估计器或评估器,它是学习算法或在训练数据上的训练方法的概念抽象。
在 Pipeline 里通常是被用来操作 DataFrame 数据并生产一个 Transformer。从技术上讲,Estimator实现了一个方法fit(),它接受一个DataFrame并产生一个转换器。如一个随机森林算法就是一个 Estimator,它可以调用fit(),通过训练特征数据而得到一个随机森林模型。
Parameter:Parameter 被用来设置 Transformer 或者 Estimator 的参数。现在,所有转换器和估计器可共享用于指定参数的公共API。
ParamMap是一组(参数,值)对。
PipeLine:翻译为工作流或者管道。工作流将多个工作流阶段(转换器和估计器)连接在一起,形成机器学习的工作流,并获得结果输出。
工作流如何工作
要构建一个 Pipeline工作流,首先需要定义 Pipeline 中的各个工作流阶段PipelineStage,(包括转换器和评估器),比如指标提取和转换模型训练等。有了这些处理特定问题的转换器和 评估器,就可以按照具体的处理逻辑有序的组织PipelineStages 并创建一个Pipeline。
引用 build.sbt
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 name := "SparkDemo01" version := "1.0-SNAPSHOT" scalaVersion := "2.12.15" idePackagePrefix := Some("org.example" ) val sparkVersion = "3.1.3" // 将阿里云仓库做为默认仓库 externalResolvers := List("my repositories" at "https://maven.aliyun.com/nexus/content/groups/public/" ) libraryDependencies ++= Seq( "org.apache.spark" %% "spark-core" % sparkVersion, "org.apache.spark" %% "spark-mllib" % sparkVersion, )
DataFrame 创建 使用class 1 2 3 4 5 6 7 8 9 10 11 12 13 14 case class Rating (userId: Int , movieId: Int , rating: Float )def parseRating String ): Rating = { val fields = str.split("::" ) assert(fields.size == 3 ) Rating (fields(0 ).toInt, fields(1 ).toInt, fields(2 ).toFloat) } val rdds = spark.sparkContext .textFile("file:///D:\\spark_study\\movie.txt" ) .map(parseRating) val ratings = spark.createDataFrame(rdds)
使用StructType 1 2 3 4 5 6 7 8 val fields = Array (StructField ("name" , StringType , nullable = true ), StructField ("age" , StringType , nullable = true ))val schema = StructType (fields)val list = Array ("xiaoming,10" , "xiaohong,12" , "xiaogang,18" )val rdd = spark.sparkContext.parallelize(list)val rowRDD = rdd.map(_.split("," )).map(attributes => Row (attributes(0 ), attributes(1 ).trim))val peopleDF = spark.createDataFrame(rowRDD, schema)peopleDF.show(false )
其中
1 2 val list = Array ("xiaoming,10" , "xiaohong,12" , "xiaogang,18" )val rdd = spark.sparkContext.parallelize(list)
也可以从文件中读取
1 val rdd = spark.sparkContext.textFile("file:///D:\\spark_study\\movie.txt" )
toDF 1 2 3 4 5 val testData = spark.createDataFrame(Seq ( ("xiaoming" , 16 ), ("xiaohong" , 18 ) )).toDF("name" , "age" ) testData.show(false )
保存文件 1 2 3 ratings.select("userId" , "movieId" , "rating" ) .write.format("csv" ) .save("file:///D:\\spark_study\\movie2" )
注意
保存的路径传的是文件夹路径,不是文件的具体路径
日志配置 1 Logger .getLogger("org" ).setLevel(Level .ERROR )
简单机器计算示例-单词分析 分析句中是否包含spark
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 package org.exampleimport org.apache.spark.ml.Pipeline import org.apache.spark.ml.classification.LogisticRegression import org.apache.spark.ml.feature.{HashingTF , Tokenizer }import org.apache.spark.sql.{Row , SparkSession }object ML01 def main Array [String ]): Unit = { val spark = SparkSession .builder(). master("local" ). appName("ML01" ). getOrCreate() val training = spark.createDataFrame(Seq ( (0 L, "a b spark c" , 1.0 ), (1 L, "b d" , 0.0 ), (2 L, "spark f g h" , 1.0 ), (3 L, "hadoop mapreduce" , 0.0 ) )).toDF("id" , "text" , "label" ) val tokenizer = new Tokenizer (). setInputCol("text" ). setOutputCol("words" ) val hashingTF = new HashingTF (). setNumFeatures(1000 ). setInputCol(tokenizer.getOutputCol). setOutputCol("features" ) val lr = new LogisticRegression (). setMaxIter(10 ). setRegParam(0.01 ) val pipeline = new Pipeline (). setStages(Array (tokenizer, hashingTF, lr)) val model = pipeline.fit(training) val testData = spark.createDataFrame(Seq ( (4 L, "i j k spark" ), (5 L, "l m n" ), (6 L, "spark a" ), (7 L, "apache hadoop" ) )).toDF("id" , "text" ) model.transform(testData). select("id" , "text" , "probability" , "prediction" ). collect(). foreach { case Row (id: Long , text: String , probability, prediction: Double ) => println(s"($id , $text ) --> probability=$probability , prediction=$prediction " ) } } }
运行结果
(4, i j k spark) –> probability=[0.3966631509161168,0.6033368490838832], prediction=1.0
特征抽取 TF-IDF (HashingTF and IDF) “词频-逆向文件频率”(TF-IDF)是一种在文本挖掘中广泛使用的特征向量化方法,它可以体现一个文档中词语在语料库中的重要程度。
在Spark ML库中,TF-IDF被分成两部分:TF (+hashing) 和 IDF。
TF : HashingTF 是一个Transformer,在文本处理中,接收词条的集合然后把这些集合转化成固定长度的特征向量。这个算法在哈希的同时会统计各个词条的词频。
IDF : IDF是一个Estimator,在一个数据集上应用它的fit()方法,产生一个IDFModel。 该IDFModel 接收特征向量(由HashingTF产生),然后计算每一个词在文档中出现的频次。IDF会减少那些在语料库中出现频率较高的词的权重。
查看词频
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 package org.exampleimport org.apache.spark.ml.Pipeline import org.apache.spark.ml.classification.LogisticRegression import org.apache.spark.ml.feature.{HashingTF , IDF , Tokenizer }import org.apache.spark.sql.{Row , SparkSession }object ML02 def main Array [String ]): Unit = { val spark = SparkSession .builder(). master("local" ). appName("ML02" ). getOrCreate() val sentenceData = spark.createDataFrame(Seq ( ("i love you you love me" , 0 ), ("mi xue bing cheng tian mi mi" , 0 ), ("i love you you like me" , 1 ) )).toDF("text" , "label" ) val tokenizer = new Tokenizer ().setInputCol("text" ).setOutputCol("words" ) val wordsData = tokenizer.transform(sentenceData) wordsData.show(false ) val hashingTF = new HashingTF (). setInputCol("words" ).setOutputCol("rawFeatures" ).setNumFeatures(2000 ) val featurizedData = hashingTF.transform(wordsData) featurizedData.select("words" , "rawFeatures" ).show(false ) val idf = new IDF ().setInputCol("rawFeatures" ).setOutputCol("features" ) val idfModel = idf.fit(featurizedData) val rescaledData = idfModel.transform(featurizedData) rescaledData.select("features" , "label" ).take(3 ).foreach(println) } }
我们可以看到打印
最终结果
[(2000,[240,338,369,1756],[0.5753641449035617,0.5753641449035617,0.28768207245178085,0.28768207245178085]),0]
Word2Vec 词意向量 单词的词义越接近 值也会越接近
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 package org.exampleimport org.apache.spark.ml.feature.Word2Vec import org.apache.spark.sql.SparkSession object ML03 def main Array [String ]): Unit = { val spark = SparkSession .builder(). master("local" ). appName("ML03" ). getOrCreate() val documentDF = spark.createDataFrame(Seq ( "i love you you love me" .split(" " ), "mi xue bing cheng tian mi mi" .split(" " ), "i love you you like me" .split(" " ) ).map(Tuple1 .apply)).toDF("text" ) documentDF.show(false ) val word2Vec = new Word2Vec (). setInputCol("text" ). setOutputCol("result" ). setVectorSize(3 ). setMinCount(0 ) val model = word2Vec.fit(documentDF) val result = model.transform(documentDF) result.show(false ) result.select("result" ).take(3 ).foreach(println) } }
我们可以看到结果
单词计数 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 package org.exampleimport org.apache.spark.ml.feature.{CountVectorizer , CountVectorizerModel }import org.apache.spark.sql.SparkSession object ML04 def main Array [String ]): Unit = { val spark = SparkSession .builder(). master("local" ). appName("ML04" ). getOrCreate() val df = spark.createDataFrame(Seq ( (0 , "i love you you love me" .split(" " )), (1 , "i love you you like me" .split(" " )) )).toDF("id" , "words" ) val cvModel: CountVectorizerModel = new CountVectorizer (). setInputCol("words" ). setOutputCol("features" ). setVocabSize(3 ). setMinDF(2 ). fit(df) cvModel.transform(df).show(false ) val cvm = new CountVectorizerModel (Array ("i" , "like" , "you" )). setInputCol("words" ). setOutputCol("features" ) cvm.transform(df).select("words" , "features" ).show(false ) } }
结果
最终取”i”, “like”, “you”的单词计数
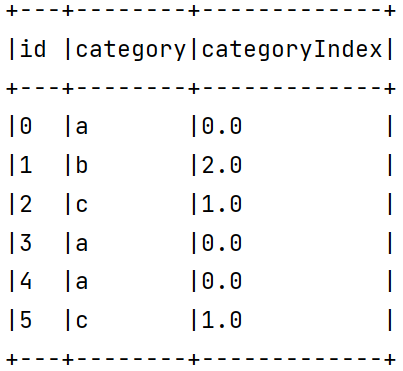
特征变换–标签和索引的转化 StringIndexer 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 package org.exampleimport org.apache.spark.ml.feature.StringIndexer import org.apache.spark.sql.SparkSession object ML05 def main Array [String ]): Unit = { val spark = SparkSession .builder(). master("local" ). appName("ML05" ). getOrCreate() val df1 = spark .createDataFrame( Seq ((0 , "a" ), (1 , "b" ), (2 , "c" ), (3 , "a" ), (4 , "a" ), (5 , "c" )) ) .toDF("id" , "category" ) val indexer = new StringIndexer (). setInputCol("category" ). setOutputCol("categoryIndex" ) val model = indexer.fit(df1) val indexed1 = model.transform(df1) indexed1.show() val df2 = spark .createDataFrame( Seq ((0 , "a" ), (1 , "b" ), (2 , "c" ), (3 , "a" ), (4 , "a" )) ) .toDF("id" , "category" ) val indexed = model.transform(df2) indexed.show() val indexed2 = model.setHandleInvalid("skip" ).transform(df2) indexed2.show() } }
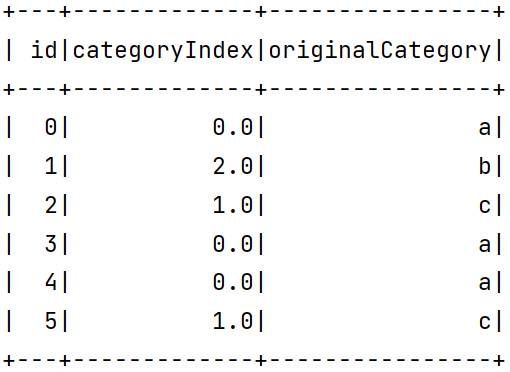
IndexToString 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 package org.exampleimport org.apache.spark.ml.feature.{IndexToString , StringIndexer }import org.apache.spark.sql.SparkSession object ML06 def main Array [String ]): Unit = { val spark = SparkSession .builder(). master("local" ). appName("ML06" ). getOrCreate() val df = spark.createDataFrame(Seq ( (0 , "a" ), (1 , "b" ), (2 , "c" ), (3 , "a" ), (4 , "a" ), (5 , "c" ) )).toDF("id" , "category" ) val model = new StringIndexer (). setInputCol("category" ). setOutputCol("categoryIndex" ). fit(df) val indexed = model.transform(df) indexed.show(false ) val converter = new IndexToString (). setInputCol("categoryIndex" ). setOutputCol("originalCategory" ) val converted = converter.transform(indexed) converted.select("id" , "categoryIndex" , "originalCategory" ).show() } }
VectorIndexer 之前介绍的StringIndexer是针对单个类别型特征进行转换,倘若所有特征都已经被组织在一个向量中,又想对其中某些单个分量进行处理时,Spark ML提供了VectorIndexer类来解决向量数据集中的类别性特征转换。
通过为其提供maxCategories超参数,它可以自动识别哪些特征是类别型的,并且将原始值转换为类别索引。它基于不同特征值的数量来识别哪些特征需要被类别化,那些取值可能性最多不超过maxCategories的特征需要会被认为是类别型的。
在下面的例子中,我们读入一个数据集,然后使用VectorIndexer训练出模型,来决定哪些特征需要被作为类别特征,将类别特征转换为索引,这里设置maxCategories为2,即只有种类小于2的特征才被认为是类别型特征,否则被认为是连续型特征:
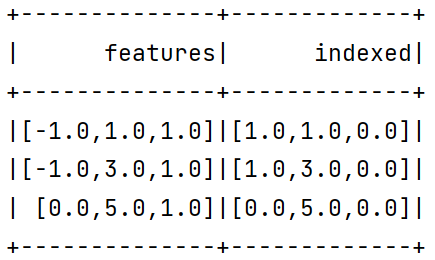
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 package org.exampleimport org.apache.spark.ml.feature.{IndexToString , StringIndexer , VectorIndexer }import org.apache.spark.ml.linalg.Vectors import org.apache.spark.sql.SparkSession object ML07 def main Array [String ]): Unit = { val spark = SparkSession .builder(). master("local" ). appName("ML07" ). getOrCreate() val data = Seq ( Vectors .dense(-1.0 , 1.0 , 1.0 ), Vectors .dense(-1.0 , 3.0 , 1.0 ), Vectors .dense(0.0 , 5.0 , 1.0 )) val df = spark .createDataFrame(data.map(Tuple1 .apply)) .toDF("features" ) val indexer = new VectorIndexer (). setInputCol("features" ). setOutputCol("indexed" ). setMaxCategories(2 ) val indexerModel = indexer.fit(df) val categoricalFeatures: Set [Int ] = indexerModel.categoryMaps.keys.toSet println(s"Chose ${categoricalFeatures.size} categorical features: " + categoricalFeatures.mkString(", " )) val indexed = indexerModel.transform(df) indexed.show() } }
可以看到,0号特征只有-1,0两种取值,分别被映射成0,1,而2号特征只有1种取值,被映射成0。
特征选取–卡方选择器 特征选择(Feature Selection)指的是在特征向量中选择出那些“优秀”的特征,组成新的、更“精简”的特征向量的过程。它在高维数据分析中十分常用,可以剔除掉“冗余”和“无关”的特征,提升学习器的性能。
特征选择方法和分类方法一样,也主要分为有监督(Supervised)和无监督(Unsupervised)两种,卡方选择则是统计学上常用的一种有监督特征选择方法,它通过对特征和真实标签之间进行卡方检验,来判断该特征和真实标签的关联程度,进而确定是否对其进行选择。
和ML库中的大多数学习方法一样,ML中的卡方选择也是以estimator+transformer的形式出现的,其主要由ChiSqSelector和ChiSqSelectorModel两个类来实现。
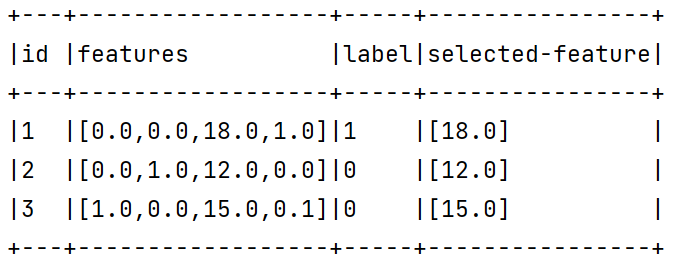
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 package org.exampleimport org.apache.spark.ml.feature.{ChiSqSelector , UnivariateFeatureSelector }import org.apache.spark.ml.linalg.Vectors import org.apache.spark.sql.SparkSession object ML08 def main Array [String ]): Unit = { val spark = SparkSession .builder(). master("local" ). appName("ML08" ). getOrCreate() val df = spark .createDataFrame(Seq ( (1 , Vectors .dense(0.0 , 0.0 , 18.0 , 1.0 ), 1 ), (2 , Vectors .dense(0.0 , 1.0 , 12.0 , 0.0 ), 0 ), (3 , Vectors .dense(1.0 , 0.0 , 15.0 , 0.1 ), 0 ) )) .toDF("id" , "features" , "label" ) val selector = new ChiSqSelector (). setNumTopFeatures(1 ). setFeaturesCol("features" ). setLabelCol("label" ). setOutputCol("selected-feature" ) val selector_model = selector.fit(df) val result = selector_model.transform(df) result.show(false ) } }
现在,用卡方选择进行特征选择器的训练,为了观察地更明显,我们设置只选择和标签关联性最强的一个特征(可以通过setNumTopFeatures(..)方法进行设置)
结果
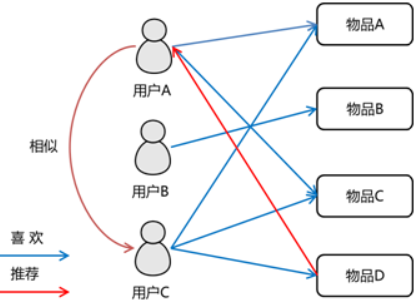
协同过滤算法 概念 协同过滤是一种基于一组兴趣相同的用户或项目进行的推荐,它根据邻居用户(与目标用户兴趣相似的用户)的偏好信息产生对目标用户的推荐列表。
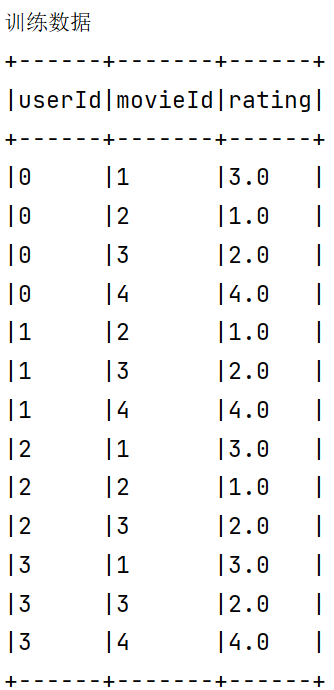
示例 我们有这样的一个数据 分别为用户ID::电影ID::用户对电影的评分
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 0::1::3.0 0::2::1.0 0::3::2.0 0::4::4.0 1::1::3.0 1::2::1.0 1::3::2.0 1::4::4.0 2::1::3.0 2::2::1.0 2::3::2.0 2::4::4.0 3::1::3.0 3::2::1.0 3::3::2.0 3::4::4.0
我们现在要根据原有的数据进行训练来预测其他用户的打分
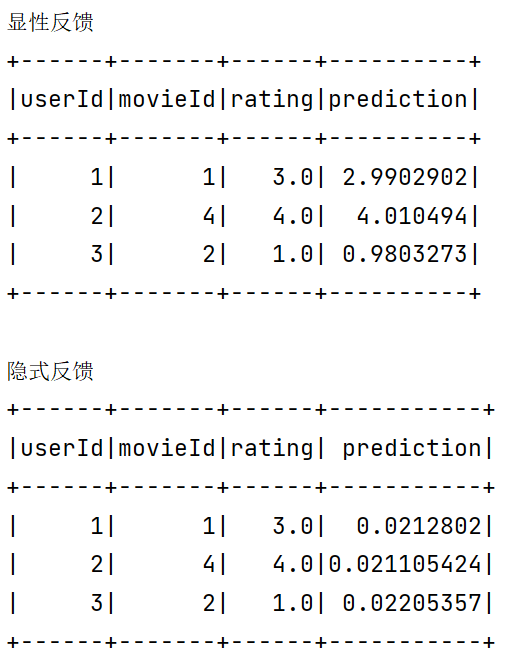
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 package org.exampleimport org.apache.log4j.{Level , Logger }import org.apache.spark.ml.evaluation.RegressionEvaluator import org.apache.spark.ml.recommendation.ALS import org.apache.spark.sql.SparkSession object ML09 case class Rating (userId: Int , movieId: Int , rating: Float ) def parseRating String ): Rating = { val fields = str.split("::" ) assert(fields.size == 3 ) Rating (fields(0 ).toInt, fields(1 ).toInt, fields(2 ).toFloat) } def main Array [String ]): Unit = { Logger .getLogger("org" ).setLevel(Level .ERROR ) val spark = SparkSession .builder(). master("local" ). appName("ML08" ). getOrCreate() val rdds = spark .sparkContext .textFile("file:///D:\\spark_study\\movie.txt" ) .map(parseRating) val ratings = spark.createDataFrame(rdds) println("全部数据" ) ratings.show(false ) val Array (training, test) = ratings.randomSplit(Array (0.8 , 0.2 )) println("训练数据" ) training.show(false ) println("测试数据" ) test.show(false ) val alsExplicit = new ALS () .setMaxIter(5 ) .setRegParam(0.01 ) .setUserCol("userId" ) .setItemCol("movieId" ) .setRatingCol("rating" ) val alsImplicit = new ALS () .setMaxIter(5 ) .setRegParam(0.01 ) .setImplicitPrefs(true ) .setUserCol("userId" ) .setItemCol("movieId" ) .setRatingCol("rating" ) val modelExplicit = alsExplicit.fit(training) val modelImplicit = alsImplicit.fit(training) val predictionsExplicit = modelExplicit.transform(test) val predictionsImplicit = modelImplicit.transform(test) println("显性反馈" ) predictionsExplicit.show() println("隐式反馈" ) predictionsImplicit.show() val evaluator = new RegressionEvaluator () .setMetricName("rmse" ) .setLabelCol("rating" ) .setPredictionCol("prediction" ) val rmseExplicit = evaluator.evaluate(predictionsExplicit) val rmseImplicit = evaluator.evaluate(predictionsImplicit) println(s"显式反馈偏差 = $rmseExplicit " ) println(s"隐性反馈偏差 = $rmseImplicit " ) } }
结果
隐性反馈 vs 显性反馈
在许多的现实生活中的很多场景中,我们常常只能接触到隐性的反馈,例如页面游览,点击,购买,喜欢,分享等等。
基于矩阵分解的协同过滤的标准方法,一般将用户商品矩阵中的元素作为用户对商品的显性偏好。
本质上,这个方法将数据作为二元偏好值和偏好强度的一个结合,而不是对评分矩阵直接进行建模。因此,评价就不是与用户对商品的显性评分,而是与所观察到的用户偏好强度关联起来。然后,这个模型将尝试找到隐语义因子来预估一个用户对一个商品的偏好。
参数说明 在 ML 中的实现有如下的参数:
numBlocks 是用于并行化计算的用户和商品的分块个数 (默认为10)。rank 是模型中隐语义因子的个数(默认为10)。maxIter 是迭代的次数(默认为10)。regParam 是ALS的正则化参数(默认为1.0)。implicitPrefs 决定了是用显性反馈ALS的版本还是用使用隐性反馈数据集的版本(默认是false,即用显性反馈)。alpha 是一个针对于隐性反馈 ALS 版本的参数,这个参数决定了偏好行为强度的基准(默认为1.0)。nonnegative 决定是否对最小二乘法使用非负的限制(默认为false)。
可以调整这些参数,不断优化结果,使均方差变小。比如:imaxIter越大,regParam越 小,均方差会越小,推荐结果较优。
错误 我在提交了一个mllib的als推荐算法,提示:
22/05/25 15:25:21 WARN BLAS: Failed to load implementation from: com.github.fommil.netlib.NativeSystemBLAS
这个问题是因为als是一个分布式算法,在本地执行时失败,在–master yarn模式下执行正常
这个错误不影响执行。