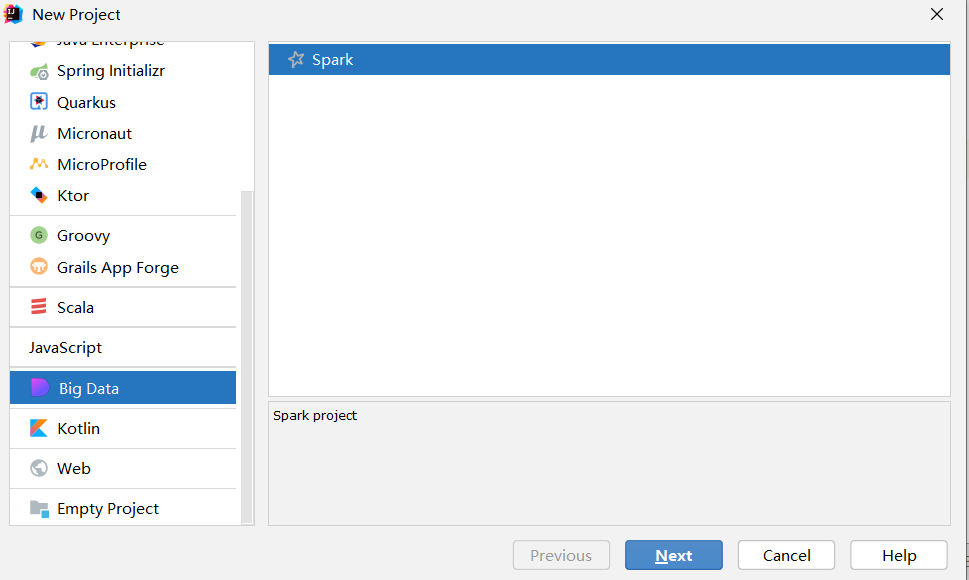
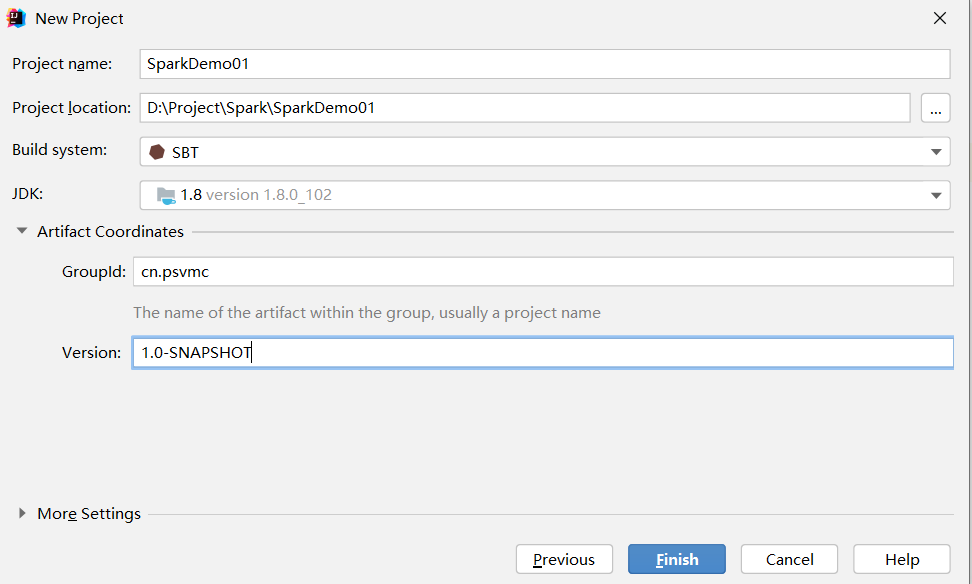
Windows环境 https://www.psvmc.cn/article/2022-04-21-bigdata-spark-idea.html
两种操作 转换操作
filter
map
flatMap
groupByKey
reduceByKey
行动操作
count()
collect()
first()
take(n)
reduce(func)
foreach(func)
saveAsTextFile()
转换操作并不会开始计算,只是记录下要做啥计算,之后在调用行动操作的时候才会开始计算,并且每次都是从开始开始计算。
Spark编程概要 传递给spark的master url可以有如下几种:
local 本地单线程local[K] 本地多线程(指定K个内核)local[*] 本地多线程(指定所有可用内核)spark://HOST:PORT 连接到指定的 Spark standalone cluster master,需要指定端口。mesos://HOST:PORT 连接到指定的 Mesos 集群,需要指定端口。yarn-client客户端模式 连接到 YARN 集群。需要配置 HADOOP_CONF_DIR。yarn-cluster集群模式 连接到 YARN 集群。需要配置 HADOOP_CONF_DIR。
获取sc 1 2 3 4 5 6 object Test def main Array [String ]): Unit = { val conf = new SparkConf ().setAppName("WordCount" ).setMaster("local" ) val sc = new SparkContext (conf) } }
RDD创建 RDD创建的两种方式
方式1 加载文件
1 2 val inputFile = "file:///D:\\spark_study\\wordcount.txt" val rdd = sc.textFile(inputFile)
或者
1 2 val inputFile = "hdfs://localhost:9000/user/hadoop/wordcount.txt" val rdd = sc.textFile(inputFile)
方式2
1 2 val list = Array (1 , 2 , 3 , 4 , 5 , 6 , 7 , 8 )var rdd = sc.parallelize(list)
简单示例 1 2 3 4 5 6 7 8 9 10 11 12 import org.apache.spark.{SparkConf , SparkContext }object WordCount def main Array [String ]): Unit = { val inputFile = "file:///D:\\spark_study\\wordcount.txt" val conf = new SparkConf ().setAppName("WordCount" ).setMaster("local" ) val sc = new SparkContext (conf) val textFile = sc.textFile(inputFile) val wordCount = textFile.flatMap(line => line.split(" " )).map(word => (word, 1 )).reduceByKey((a, b) => a + b) wordCount.foreach(println) } }
持久化 1 2 3 4 5 6 7 val list = Array (1 , 2 , 3 , 4 , 5 , 6 , 7 , 8 )var rdd = sc.parallelize(list, 2 )rdd = rdd.filter(item => item > 1 ) rdd.cache() rdd.foreach(println) rdd.filter(item => item < 7 ).foreach(println)
注意
rdd持久化可以用两个方法
rdd.cache()
rdd.persist(StorageLevel.MEMORY_ONLY)
这两个方法作用是一样的,只不过后者可以设置持久化的位置,cache()则是直接持久化到内存中。
分区 1 2 3 4 val arr = Array (1 , 2 , 3 , 4 , 5 )val rdd = sc.parallelize(arr, 2 )rdd.filter(item => item > 2 ).foreach(println)
Pair 创建 1 2 3 4 val list = List ("Hadoop" , "Spark" , "Hive" , "Spark" )val rdd = sc.parallelize(list)val pairRDD = rdd.map(word => (word, 1 ))pairRDD.foreach(println)
或者
1 2 3 val rdd = sc.textFile("file:///D:\\spark_study\\wordcount.txt" )val pairRDD = rdd.flatMap(line => line.split(" " )).map(word => (word, 1 ))pairRDD.foreach(println)
wordcount.txt
1 2 good good study day day up
reduceByKey 1 2 3 4 val list = List ("good good study" , "day day up" )val rdd = sc.parallelize(list)val pairRDD = rdd.flatMap(line => line.split(" " )).map(word => (word, 1 ))pairRDD.reduceByKey((a, b) => a + b).foreach(println)
结果
(up,1)
groupByKey() 1 2 3 4 val list = List ("good good study" , "day day up" )val rdd = sc.parallelize(list)val pairRDD = rdd.flatMap(line => line.split(" " )).map(word => (word, 1 ))pairRDD.groupByKey().foreach(println)
结果
(up,CompactBuffer(1))
keys/values 1 2 3 4 5 6 val list = List ("good good study" , "day day up" )val rdd = sc.parallelize(list)val pairRDD = rdd.flatMap(line => line.split(" " )).map(word => (word, 1 ))val pairRDD2 = pairRDD.groupByKey()pairRDD2.keys.foreach(println) pairRDD2.values.foreach(println)
结果
up
CompactBuffer(1)
sortByKey() 1 2 3 4 val list = List ("good good study" , "day day up" )val rdd = sc.parallelize(list)val pairRDD = rdd.flatMap(line => line.split(" " )).map(word => (word, 1 ))pairRDD.sortByKey().foreach(println)
结果
(day,1)
mapValues(func) 1 2 3 4 val list = List ("good good study" , "day day up" )val rdd = sc.parallelize(list)val pairRDD = rdd.flatMap(line => line.split(" " )).map(word => (word, 1 ))pairRDD.mapValues((x) => x + 100 ).foreach(println)
结果
(good,101)
join 1 2 3 4 5 6 7 8 9 10 val pairRDD1 = sc.parallelize(Array (("spark" , 1 ), ("spark" , 2 ), ("hadoop" , 3 ), ("hadoop" , 5 )))val pairRDD2 = sc.parallelize(Array (("spark" , 100 )))println("join:" ) pairRDD1.join(pairRDD2).foreach(println) println("fullOuterJoin:" ) pairRDD1.fullOuterJoin(pairRDD2).foreach(println) println("leftOuterJoin:" ) pairRDD1.leftOuterJoin(pairRDD2).foreach(println) println("rightOuterJoin:" ) pairRDD1.rightOuterJoin(pairRDD2).foreach(println)
结果
join:
fullOuterJoin:
leftOuterJoin:
rightOuterJoin:
共享变量 广播变量 广播变量(broadcast variables)允许程序开发人员在每个机器上缓存一个只读的变量,而不是为机器上的每个任务都生成一个副本。通过这种方式,就可以非常高效地给每个节点(机器)提供一个大的输入数据集的副本。Spark的“动作”操作会跨越多个阶段(stage),对于每个阶段内的所有任务所需要的公共数据,Spark都会自动进行广播。通过广播方式进行传播的变量,会经过序列化,然后在被任务使用时再进行反序列化。这就意味着,显式地创建广播变量只有在下面的情形中是有用的:当跨越多个阶段的那些任务需要相同的数据,或者当以反序列化方式对数据进行缓存是非常重要的。
可以通过调用SparkContext.broadcast(v)来从一个普通变量v中创建一个广播变量。这个广播变量就是对普通变量v的一个包装器,通过调用value方法就可以获得这个广播变量的值,具体代码如下:
1 2 val broadcastVar = sc.broadcast(Array (1 , 2 , 3 ))println(broadcastVar.value.mkString("Array(" , ", " , ")" ))
这个广播变量被创建以后,那么在集群中的任何函数中,都应该使用广播变量broadcastVar的值,而不是使用v的值,这样就不会把v重复分发到这些节点上。此外,一旦广播变量创建后,普通变量v的值就不能再发生修改,从而确保所有节点都获得这个广播变量的相同的值。
累加器 累加器是仅仅被相关操作累加的变量,通常可以被用来实现计数器(counter)和求和(sum)。
Spark原生地支持数值型(numeric)的累加器,程序开发人员可以编写对新类型的支持。如果创建累加器时指定了名字,则可以在Spark UI界面看到,这有利于理解每个执行阶段的进程。SparkContext.longAccumulator()或者SparkContext.doubleAccumulator()来创建。
运行在集群中的任务,就可以使用add方法来把数值累加到累加器上,但是,这些任务只能做累加操作,不能读取累加器的值,只有任务控制节点(Driver Program)可以使用value方法来读取累加器的值。
1 2 3 val accum = sc.longAccumulator("My Accumulator" )sc.parallelize(Array (1 , 2 , 3 , 4 )).foreach(x => accum.add(x)) println(accum.value)
结果
10
JSON处理 转换的库的网址
https://github.com/json4s/json4s/
1 2 3 4 5 6 7 8 9 10 import org.json4s._import org.json4s.jackson.JsonMethods ._import org.json4s.jackson.Serialization implicit val formats = Serialization .formats(ShortTypeHints (List ()))val testjson = """{"name":"joe","age":15,"luckNumbers":[1,2,3,4,5]}""" val p = parse(testjson).extract[Person ]println(p.name) println(p.age) println(p.luckNumbers)
JSON文件json.txt
1 2 3 {"name": "xiaoming","age": 10, "luckNumbers":[1,2,3,4,5]} {"name": "xiaohong","age": 18,"luckNumbers":[3,4,5]} {"name": "xiaogang","age": 6,"luckNumbers":[1,2,3]}
代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 import org.apache.spark.{SparkConf , SparkContext }import org.json4s._import org.json4s.jackson.JsonMethods ._import org.json4s.jackson.Serialization object Test case class Person (name: String , age: Int , luckNumbers: List [Int ] ) def main Array [String ]): Unit = { val conf = new SparkConf ().setAppName("WordCount" ).setMaster("local" ) val sc = new SparkContext (conf) val inputFile = "file:///D:\\spark_study\\json.txt" val rdd = sc.textFile(inputFile) rdd.foreach(item => { implicit val f1 = Serialization .formats(ShortTypeHints (List ())) val p = parse(item).extract[Person ] println(p.name) }) } }
结果
xiaoming
读取HBase 创建项目
修改build.sbt
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 name := "SparkDemo01" version := "1.0-SNAPSHOT" scalaVersion := "2.12.15" idePackagePrefix := Some("org.example" ) val sparkVersion = "3.1.3" // 将阿里云仓库做为默认仓库 externalResolvers := List("my repositories" at "https://maven.aliyun.com/nexus/content/groups/public/" ) libraryDependencies ++= Seq( "org.apache.spark" %% "spark-core" % sparkVersion, "org.apache.hbase" % "hbase-client" % "2.1.10" , "org.apache.hbase" % "hbase-common" % "2.1.10" , "org.apache.hbase" % "hbase-server" % "2.1.10" , "org.apache.hbase" % "hbase-mapreduce" % "2.1.10" , "org.apache.hbase" % "hbase-protocol" % "2.1.10" )
示例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 package org.exampleimport org.apache.hadoop.hbase._import org.apache.hadoop.hbase.mapreduce.TableInputFormat import org.apache.hadoop.hbase.util.Bytes import org.apache.spark.{SparkConf , SparkContext }object SparkHBase def main Array [String ]): Unit = { val config = new SparkConf () config .setMaster("local[*]" ) .setAppName("SparkHBase" ) val sc = new SparkContext (config) val conf = HBaseConfiguration .create() conf.set(TableInputFormat .INPUT_TABLE , "student" ) val stuRDD = sc.newAPIHadoopRDD( conf, classOf[TableInputFormat ], classOf[org.apache.hadoop.hbase.io.ImmutableBytesWritable ], classOf[org.apache.hadoop.hbase.client.Result ] ) val count = stuRDD.count() println("Students RDD Count:" + count) stuRDD.cache() stuRDD.foreach({ case (_, result) => val key = Bytes .toString(result.getRow) val s_name = Bytes .toString(result.getValue("s_name" .getBytes, "" .getBytes)) val math = Bytes .toString(result.getValue("s_course" .getBytes, "math" .getBytes)) println("Row key:" + key) println("s_name:" + s_name) println("math:" + math) }) } }
如果运行报错
Error running HBaseSpark. Command line is too long.
找到.idea下的workspace.xml
搜索 PropertiesComponent
内部添加
1 <property name ="dynamic.classpath" value ="true" />
添加后结构如下
1 2 3 4 5 6 7 8 9 10 <component name ="PropertiesComponent" > <property name ="dynamic.classpath" value ="true" /> <property name ="RunOnceActivity.OpenProjectViewOnStart" value ="true" /> <property name ="RunOnceActivity.ShowReadmeOnStart" value ="true" /> <property name ="WebServerToolWindowFactoryState" value ="false" /> <property name ="project.structure.last.edited" value ="Modules" /> <property name ="project.structure.proportion" value ="0.0" /> <property name ="project.structure.side.proportion" value ="0.0" /> <property name ="vue.rearranger.settings.migration" value ="true" /> </component >
Kafka作为数据源 数据产生者
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 import java.util.HashMap import org.apache.kafka.clients.producer.{KafkaProducer , ProducerConfig , ProducerRecord }object KafkaWordProducer def main Array [String ]) { val brokers = "localhost:9092" val topic = "test" val messagesPerSec = 2 val wordsPerMessage = 10 val props = new HashMap [String , Object ]() props.put(ProducerConfig .BOOTSTRAP_SERVERS_CONFIG , brokers) props.put( ProducerConfig .VALUE_SERIALIZER_CLASS_CONFIG , "org.apache.kafka.common.serialization.StringSerializer" ) props.put( ProducerConfig .KEY_SERIALIZER_CLASS_CONFIG , "org.apache.kafka.common.serialization.StringSerializer" ) val producer = new KafkaProducer [String , String ](props) while (true ) { (1 to messagesPerSec).foreach { messageNum => val str = (1 to wordsPerMessage).map(x => scala.util.Random .nextInt(10 ).toString) .mkString(" " ) print(str) println() val message = new ProducerRecord [String , String ](topic, null , str) producer.send(message) } println("-------------------------" ) Thread .sleep(1000 ) } } }
消费及运算
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 package org.exampleimport org.apache.kafka.common.serialization.StringDeserializer import org.apache.spark._import org.apache.spark.rdd.RDD import org.apache.spark.streaming._import org.apache.spark.streaming.kafka010.ConsumerStrategies .Subscribe import org.apache.spark.streaming.kafka010.KafkaUtils import org.apache.spark.streaming.kafka010.LocationStrategies .PreferConsistent object KafkaWordCount def main Array [String ]) { val sparkConf = new SparkConf ().setAppName("KafkaWordCount" ).setMaster("local[2]" ) val sc = new SparkContext (sparkConf) sc.setLogLevel("ERROR" ) val ssc = new StreamingContext (sc, Seconds (10 )) ssc.checkpoint("file:///usr/local/spark/mycode/kafka/checkpoint" ) val kafkaParams = Map [String , Object ]( "bootstrap.servers" -> "localhost:9092" , "key.deserializer" -> classOf[StringDeserializer ], "value.deserializer" -> classOf[StringDeserializer ], "group.id" -> "use_a_separate_group_id_for_each_stream" , "auto.offset.reset" -> "latest" , "enable.auto.commit" -> (true : java.lang.Boolean ) ) val topics = Array ("test" ) val stream = KafkaUtils .createDirectStream[String , String ]( ssc, PreferConsistent , Subscribe [String , String ](topics, kafkaParams) ) stream.foreachRDD(rdd => { val maped: RDD [(String , String )] = rdd.map(record => (record.key, record.value)) val lines = maped.map(_._2) val words = lines.flatMap(_.split(" " )) val pair = words.map(x => (x, 1 )) val wordCounts = pair.reduceByKey(_ + _) wordCounts.foreach(println) println("--------------------------------" ) }) ssc.start ssc.awaitTermination } }
build.sbt
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 name := "SparkDemo01" version := "1.0-SNAPSHOT" scalaVersion := "2.12.15" idePackagePrefix := Some("org.example" ) val sparkVersion = "3.1.3" // 将阿里云仓库做为默认仓库 externalResolvers := List("my repositories" at "https://maven.aliyun.com/nexus/content/groups/public/" ) libraryDependencies ++= Seq( "org.apache.spark" %% "spark-core" % sparkVersion, "org.apache.spark" % "spark-streaming_2.12" % sparkVersion, "org.apache.spark" % "spark-streaming-kafka-0-10_2.12" % "2.4.8" )
运行时我们就能看到
生产者每1秒都会产生一组数据
1 2 3 9 3 1 5 9 9 8 9 2 7 9 8 2 6 5 2 9 4 9 7 -------------------------
每10秒进行一次统计
1 2 3 4 5 6 7 8 9 10 11 (4,22) (8,17) (7,22) (5,25) (6,11) (0,15) (2,15) (9,15) (3,21) (1,17) --------------------------------