原生多模态模型Qwen3.5-35B-A3B部署与使用
前言
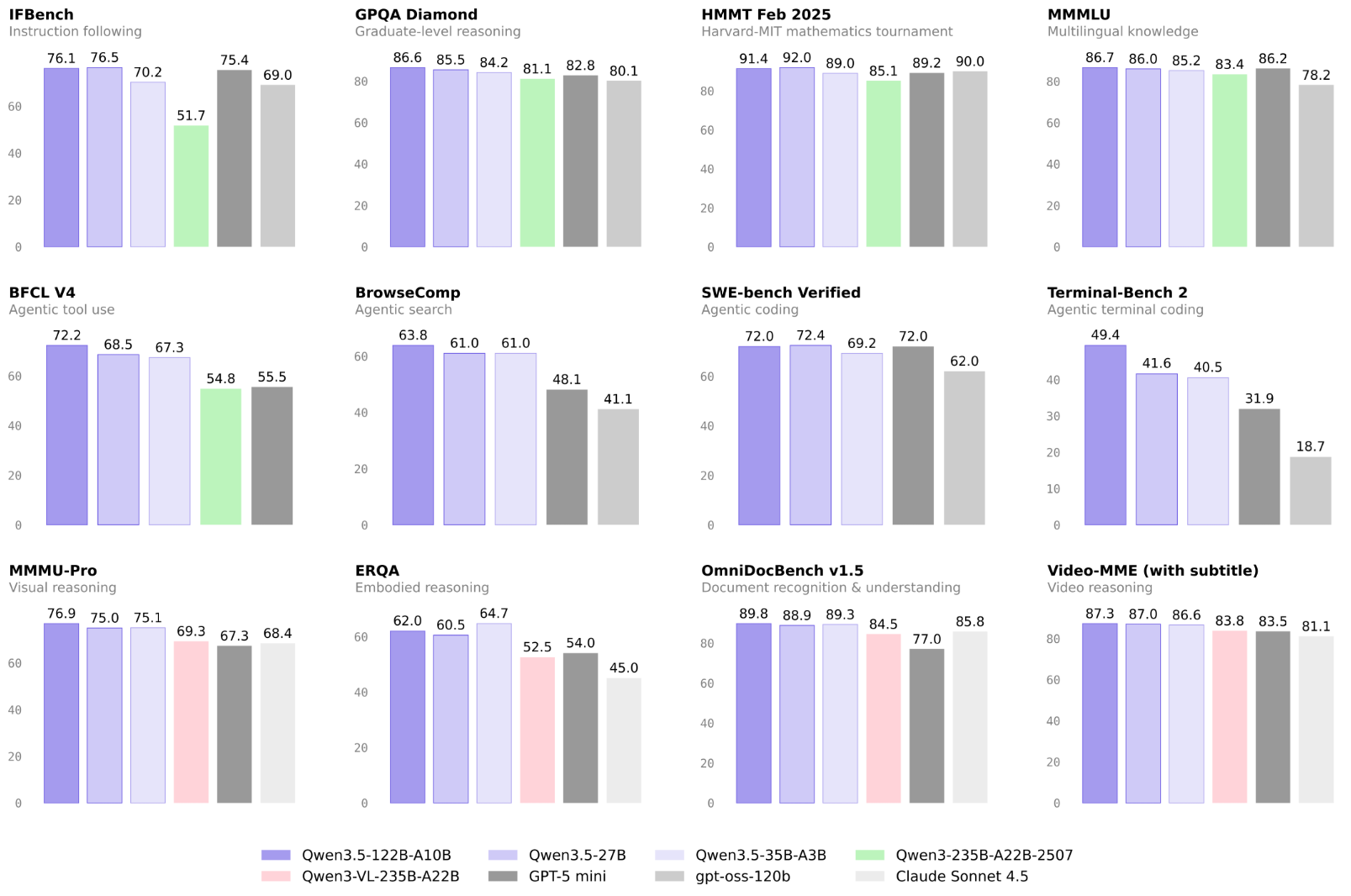
Qwen3.5 在多个方面实现显著增强:
- 多模态融合:通过早期视觉-语言融合,在多项基准上媲美 Qwen3 并超越 Qwen3-VL;
- 高效推理架构:采用门控 Delta 网络与稀疏混合专家机制,实现低延迟、低成本、高吞吐;
- 强化学习泛化:在百万级智能体环境中训练,逐步提升任务复杂度,增强现实适应力;
- 全球语言支持:覆盖 201 种语言及方言,具备文化与区域敏感性;
- 先进训练体系:多模态训练效率接近纯文本水平,并集成异步强化学习与大规模环境编排能力。
对比
模型下载
1 | modelscope download --model Qwen/Qwen3.5-35B-A3B |
https://modelscope.cn/models/Qwen/Qwen3.5-4B
1 | modelscope download --model Qwen/Qwen3.5-4B |
https://modelscope.cn/models/Qwen/Qwen3.5-9B
1 | modelscope download --model Qwen/Qwen3.5-9B |
https://modelscope.cn/models/Qwen/Qwen3.5-27B
1 | modelscope download --model Qwen/Qwen3.5-27B |
Docker
Dockerfile
1 | FROM image.sourcefind.cn:5000/dcu/admin/base/custom:pytorch2.9.1-ubuntu22.04-dtk26.04-0130-py3.10-20260204-qwen3_5 |
模型运行脚本
run_model.sh
1 | MODEL_PORT=${MODEL_PORT:-8001} |
实测
海光DCU 2张 64G可运行
运行方式
标准版本:
这种方式海光DCU上正常运行。✔️
以下命令可用于在 8 个 GPU 上使用张量并行创建一个最大上下文长度为 262,144 个 token 的 API 端点。
1 | VLLM_USE_MODELSCOPE=true vllm serve Qwen/Qwen3.5-35B-A3B --port 8000 --tensor-parallel-size 8 --max-model-len 262144 --reasoning-parser qwen3 |
工具调用:
这种方式
Qwen/Qwen3.5-35B-A3B在海光DCU上无法运行。✖️这种方式
Qwen/Qwen3.5-9B在海光DCU上正常运行。✔️
若要支持工具调用,可使用以下命令。
1 | VLLM_USE_MODELSCOPE=true vllm serve Qwen/Qwen3.5-35B-A3B --port 8000 --tensor-parallel-size 8 --max-model-len 262144 --reasoning-parser qwen3 --enable-auto-tool-choice --tool-call-parser qwen3_coder |
多 Token 预测(MTP):
这种方式
Qwen/Qwen3.5-35B-A3B在海光DCU上无法运行。✖️这种方式
Qwen/Qwen3.5-9B在海光DCU上正常运行。✔️
推荐使用以下命令进行 MTP:
1 | VLLM_USE_MODELSCOPE=true vllm serve Qwen/Qwen3.5-35B-A3B --port 8000 --tensor-parallel-size 8 --max-model-len 262144 --reasoning-parser qwen3 --speculative-config '{"method":"qwen3_next_mtp","num_speculative_tokens":2}' |
纯文本模式:
这种方式海光DCU上正常运行。✔️
以下命令将跳过视觉编码器和多模态配置,以释放更多内存用于 KV 缓存:
1 | VLLM_USE_MODELSCOPE=true vllm serve Qwen/Qwen3.5-35B-A3B --port 8000 --tensor-parallel-size 8 --max-model-len 262144 --reasoning-parser qwen3 --language-model-only |
经测试
海光DCU上
工具调用只能单卡正常调用,多卡不能调用。
测试
文字
1 | { |
图像
1 | { |