vLLM简介
前言
vLLM(发音为 “velm”)是一个开源、高性能的大语言模型(LLM)推理和服务引擎,由加州大学伯克利分校的 Sky Lab 团队于 2023 年推出。
它的核心目标是:以极高的吞吐量和低延迟运行大语言模型,同时保持简单易用的部署方式。
vLLM 目前官方仅支持 NVIDIA GPU(CUDA),不能在非 NVIDIA 显卡(如 AMD GPU、Intel Arc、Apple Silicon 等)上运行其核心推理功能。
后文
在海光GPU平台上也有兼容的vLLM镜像使用。
vLLM 的核心优势
| 特性 | 说明 |
|---|---|
| 🚀 超高吞吐 | 比 Hugging Face Transformers 快 10–24 倍(官方数据) |
| 💡 PagedAttention | 自研内存管理技术,显著提升显存利用率,支持更长上下文和更高并发 |
| 🔌 OpenAI API 兼容 | 开箱即用提供 /v1/chat/completions 等接口,可直接替代 OpenAI |
| 🧩 支持主流模型 | Qwen、Llama、ChatGLM、Baichuan、Mistral、Gemma、Yi 等数十种模型 |
| 📦 易于部署 | 一行命令启动服务,支持 Docker、Kubernetes |
| 🔄 流式输出 & Token 级别响应 | 支持 SSE(Server-Sent Events),适合聊天场景 |
核心技术:PagedAttention
传统 LLM 推理中,每个请求的 KV Cache(键值缓存)必须连续存储在 GPU 显存中,容易造成内存碎片,限制并发。
vLLM 借鉴操作系统虚拟内存分页思想,将 KV Cache 分成固定大小的“块”(blocks),按需分配,非连续存储。
这带来:
- 显存利用率提升 2–4 倍
- 支持更多并发请求
- 减少 OOM(显存溢出)风险
类比:
就像硬盘上的文件可以分散存储,但通过页表统一寻址。
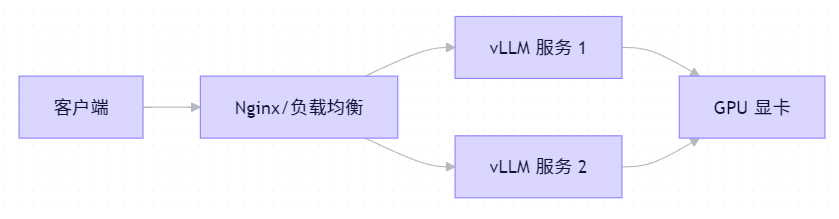
私有化部署架构
使用示例
安装
1 | pip install vllm |
启动一个 Qwen 模型服务
1 | python -m vllm.entrypoints.openai.api_server \ |
启动后,自动提供标准 OpenAI API 接口(也是 MCP 兼容的!):
POST http://localhost:8000/v1/chat/completionsPOST http://localhost:8000/v1/completions
调用
兼容 OpenAI SDK
1 | from openai import OpenAI |
vLLM vs Hugging Face Transformers
| 对比项 | Hugging Face Transformers | vLLM |
|---|---|---|
| 推理速度 | 慢(逐请求处理) | 极快(批处理 + PagedAttention) |
| 并发能力 | 低 | 高(支持数千 RPM) |
| 显存效率 | 低(KV Cache 连续) | 高(分页管理) |
| 部署复杂度 | 简单 | 简单(甚至更简单) |
| OpenAI 兼容 | 需自行封装 | 内置支持 |
| 适合场景 | 实验、小规模 | 生产、高并发服务 |
与 MCP 的关系
由于 MCP 协议高度兼容 OpenAI API,而 vLLM 原生提供 OpenAI 兼容接口,因此:
✅ vLLM 可直接作为 MCP Server 使用!
你无需额外开发 API 层,只需启动 vLLM 服务,它就自动成为一个符合 MCP 规范的模型服务端。
官方资源
- GitHub: https://github.com/vllm-project/vllm
- 文档: https://docs.vllm.ai/
- 支持模型列表: https://docs.vllm.ai/en/latest/models/supported_models.html
总结
vLLM = 高性能 LLM 推理引擎 + 开箱即用的 OpenAI/MCP 兼容 API
如果你要部署自己的大模型服务(无论是用于 MCP 生态、私有 AI 助手,还是 SaaS 产品),vLLM 是目前最推荐的推理后端之一。