DeepSeek-R1模型本地部署
前言
DeepSeek-R1官方
安装Ollama
Ollama是一个方便进行模型安装和测试的工具
选择对应的平台安装即可
安装后可以输入
1 | ollama -v |
可以看到如下就说明安装成功了
ollama version is 0.5.7
查看运行状态
访问 http://localhost:11434,查看是否正常运行
环境变量
设置环境变量
1 | OLLAMA_HOST: 0.0.0.0 |
其中:
OLLAMA_HOST:设置为0.0.0.0 会将ollama服务暴露到所有的网络,默认ollama只绑定到了127.0.0.1和localhost上了。
OLLAMA_MODELS:设置了模型的存放的地址。
设置环境变量后要重启下电脑才能生效。
常用命令
1 | #查看已下载的模型 |
安装模型
可以在这个地址看到所有的可用模型
目前比较火的排在第一位的就是DeepSeek-R1模型
https://ollama.com/library/deepseek-r1
可以看到不同参数数量的模型
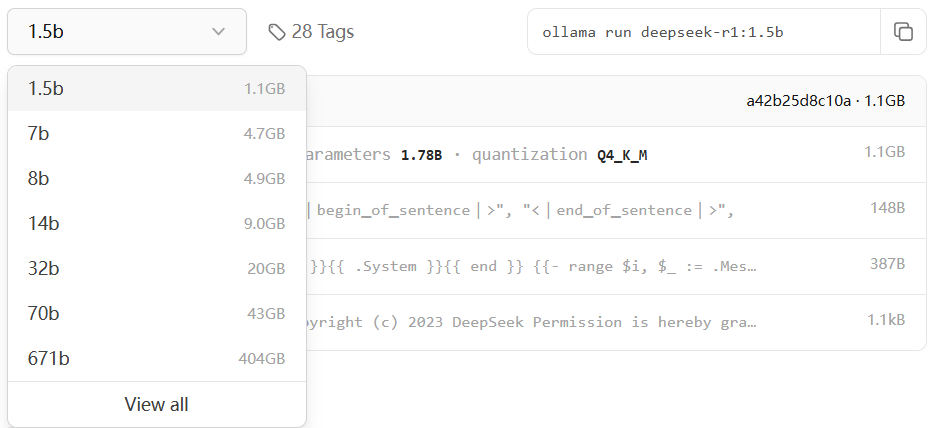
可以大致参考自己显卡显存的大小除3来选择模型
一个7B的模型,参数数量是70亿,每个参数2字节,那么参数需要的显存是7,000,000,000 * 2 bytes = 14,000,000,000 bytes ≈14 GB。
但实际上,模型在推理时可能需要更多的显存,因为除了参数之外,还有计算激活值(中间结果)的存储。
因此,在估算时,通常会说模型参数所需显存的两倍左右,以考虑激活值和其他开销。例如,7B模型可能需要大约14GB的参数显存,所以总显存需求可能在20GB左右。
下载模型
这里使用最小的模型做测试
1.5b,适用于一般文字编辑使用
1 | ollama run deepseek-r1:1.5b |
中断了也不要紧,再次运行会接着之前的进度下载。
7b下载
7b,DS 第一代推理模型,性能与 OpenAl-o1 相当。
1 | ollama run deepseek-r1:7b |
下载脚本
ollama下载会原来越慢,但是中断后重新运行命令会接着下载,速度也会提升,所以这里写一个脚本实现。
run.bat
1 | @echo off |
查看安装的模型
1 | ollama list |
接口测试
流式请求
1 | curl http://localhost:11434/api/generate -d "{\"model\": \"deepseek-r1:1.5b\",\"prompt\": \"你是谁\"}" |
非流式请求
1 | curl http://localhost:11434/api/generate -d "{\"model\": \"deepseek-r1:1.5b\",\"prompt\": \"你是谁\",\"stream\":false}" |
返回的数据
1 | {"model":"deepseek-r1:1.5b","created_at":"2025-02-06T10:05:52.8353077Z","response":"\u003cthink\u003e\n\n\u003c/think\u003e\n\n您好!我是由中国的深度求索(DeepSeek)公司开发的智能助手DeepSeek-R1。如您有任何任何问题,我会尽我所能为您提供帮助。","done":true,"done_reason":"stop","context":[151644,105043,100165,151645,151648,271,151649,271,111308,6313,104198,67071,105538,102217,30918,50984,9909,33464,39350,7552,73218,100013,9370,100168,110498,33464,39350,10911,16,1773,29524,87026,110117,99885,86119,3837,105351,99739,35946,111079,113445,100364,1773],"total_duration":934602900,"load_duration":18992300,"prompt_eval_count":5,"prompt_eval_duration":7000000,"eval_count":40,"eval_duration":908000000} |
客户端
AnythingLLM
https://anythingllm.com/desktop
Chatbox AI
浏览器插件
https://www.crxsoso.com/webstore/detail/jfgfiigpkhlkbnfnbobbkinehhfdhndo
安装Open WebUI
1 | conda create -n open-webui python=3.11.0 -y |
配置 WebUl:运行以下命令启动 Open WebUl:
1 | open-webui serve |
启动后,你可以通过浏览器访问WebUl界面,通常是 http://localhost:8080
WEB调用流式API
1 | <!DOCTYPE html> |
上下文
1 | // 模拟上下文 |
拼接好的类似于
1 | const data = { |
Nginx反代
要在 Nginx 中反向代理流式 API(如 OpenAI 的流式响应 API),需要确保 Nginx 能够正确处理流式数据(如分块传输编码 chunked transfer encoding),并且不会在代理过程中缓冲整个响应。以下是一个配置示例和说明:
Nginx 配置示例
1 | server { |
关键配置说明
proxy_buffering off;
这是最关键的部分。Nginx 默认会缓冲整个响应,然后一次性发送给客户端。对于流式 API,这会导致客户端无法实时接收数据。通过禁用缓冲(proxy_buffering off),Nginx 会将数据直接传递给客户端,实现流式传输。proxy_http_version 1.1;
使用 HTTP/1.1 协议,以支持分块传输编码(chunked transfer encoding),这是流式传输的基础。proxy_set_header Connection "";
确保连接是持久的,避免在流式传输过程中断开。超时设置
流式 API 的响应时间可能较长,因此需要适当调整超时时间:proxy_read_timeout:从后端服务器读取数据的超时时间。proxy_send_timeout:向客户端发送数据的超时时间。
proxy_pass
将请求转发到目标 API 地址(如http://localhost:11434/)。
测试配置
保存配置文件并重新加载 Nginx:
1
2sudo nginx -t # 测试配置文件是否正确
sudo systemctl reload nginx # 重新加载 Nginx使用
curl或浏览器测试流式 API:1
curl -X POST http://yourdomain.com/api/generate -d '{"model": "deepseek-r1:1.5b", "prompt": "你是谁"}' --header "Content-Type: application/json"
如果配置正确,你应该能够实时接收到流式数据。
注意事项
- 性能优化:如果流式 API 的并发量较大,可能需要调整 Nginx 的
worker_connections和keepalive_timeout等参数。 - SSL/TLS:如果 API 需要通过 HTTPS 访问,可以在 Nginx 中配置 SSL 证书。
- 日志记录:如果需要调试,可以启用 Nginx 的访问日志和错误日志。
通过以上配置,Nginx 可以正确代理流式 API,并确保数据实时传输到客户端。
RAG
体验地址
官方仓库
https://github.com/infiniflow/ragflow
RAGFlow
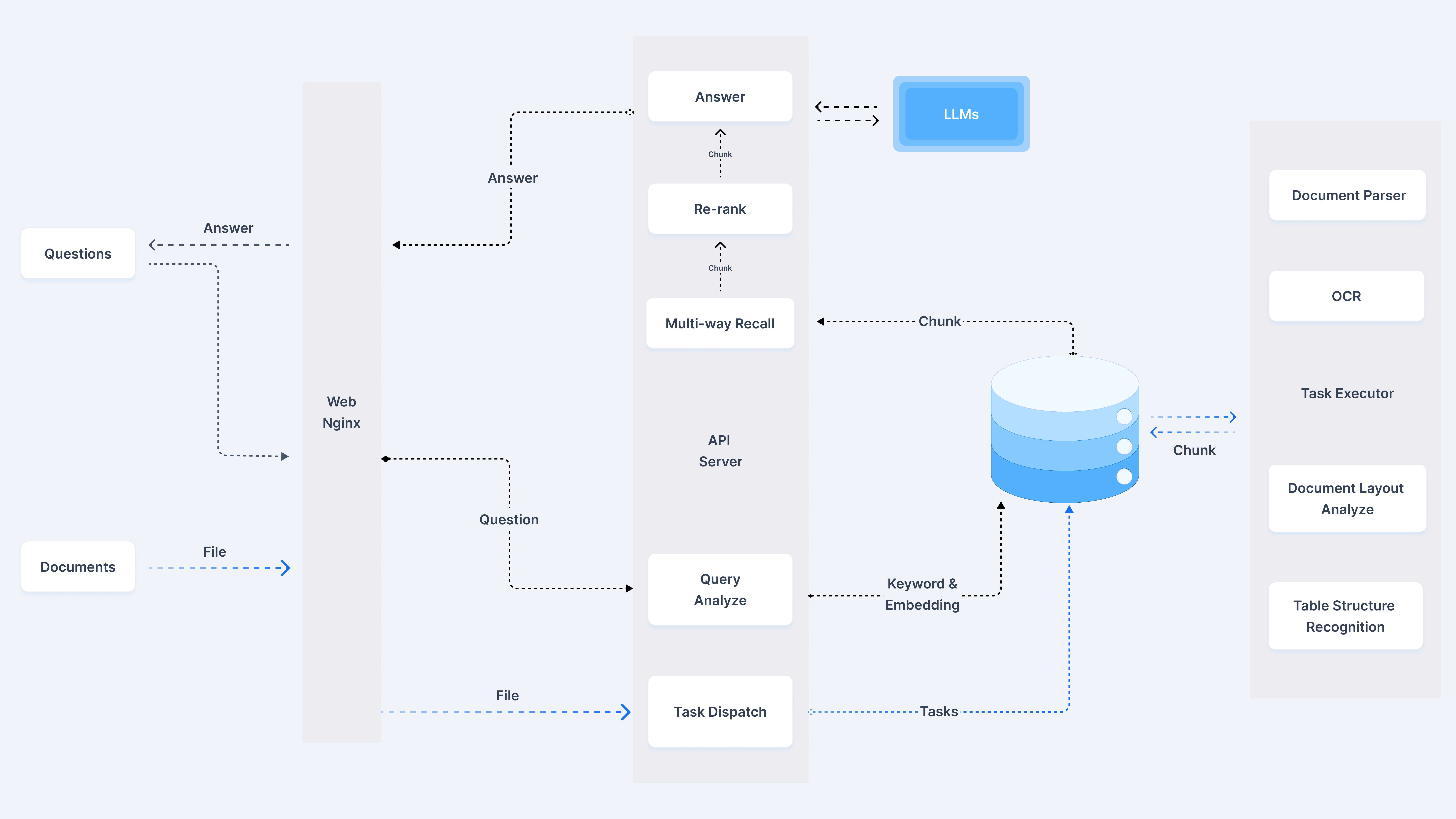
部署
Linux下配置参数
vm.max_map_count 是 Linux 内核中的一个参数,它定义了一个进程可以拥有的最大内存映射区域(memory map areas)数量。
查看该值
1 | sysctl vm.max_map_count |
修改/etc/sysctl.conf
1 | vm.max_map_count=262144 |
Clone代码
1 | git clone https://github.com/infiniflow/ragflow.git |
可以在 docker/.env 文件内根据变量 RAGFLOW_IMAGE 的注释提示选择华为云或者阿里云的相应镜像。
- 华为云镜像名:
swr.cn-north-4.myhuaweicloud.com/infiniflow/ragflow - 阿里云镜像名:
registry.cn-hangzhou.aliyuncs.com/infiniflow/ragflow
注释掉
1 | # RAGFLOW_IMAGE=infiniflow/ragflow:v0.16.0-slim |
解除注释
1 | RAGFLOW_IMAGE=swr.cn-north-4.myhuaweicloud.com/infiniflow/ragflow:nightly |
运行
1 | cd ragflow/docker |
检查运行日志
1 | docker logs -f ragflow-server |
停止
1 | docker compose -f docker/docker-compose.yml down -v |
访问
本地IP端口80就能正常访问。
内存需求
1. 推理场景(Inference)
非量化模型(FP16/BF16)
- 参数存储:每个参数占2字节(16位)。
- 激活值开销:约为参数显存的0.5-1倍(取决于输入序列长度和批次大小)。
- 总显存估算:
参数数量 × 2 × (1.5~2)字节。
| 参数规模 | 参数显存 (GB) | 总显存需求 (GB) | 推荐显卡示例 |
|---|---|---|---|
| 7B | 14 | 18-24 | NVIDIA RTX 3090/4090 (24GB) |
| 13B | 26 | 32-40 | NVIDIA A40 (48GB) |
| 33B | 66 | 80-100 | 多卡并行或A100 (80GB) |
| 70B | 140 | 168-200 | 多卡并行或H100 (显存扩展) |
量化模型(INT8)
- 参数存储:每个参数占1字节(8位)。
- 总显存估算:约为非量化模型的50%-70%。
| 参数规模 | 参数显存 (GB) | 总显存需求 (GB) | 推荐显卡示例 |
|---|---|---|---|
| 7B | 7 | 10-14 | NVIDIA RTX 3080 (12GB) |
| 13B | 13 | 16-22 | NVIDIA RTX 4090 (24GB) |
| 70B | 70 | 90-120 | 多卡并行或A100 (80GB) |
2. 训练场景(Training)
非量化模型(FP16 + Adam优化器)
- 参数、梯度、优化器状态:每个参数需12字节(参数2B + 梯度2B + 优化器状态8B)。
- 总显存估算:
参数数量 × 12字节。
| 参数规模 | 显存需求 (GB) | 硬件要求 |
|---|---|---|
| 7B | 84 | 多卡并行(如4×A100 80GB) |
| 13B | 156 | 多卡并行或H100集群 |
| 70B | 840 | 大规模分布式训练(如TPU Pod) |