BI开发过程中的数据处理(Doris)
前言
这里使用Mysql保存最终数据,Apache Doris保存处理过程中的数据
Apache Doris
https://github.com/apache/doris
https://doris.apache.org/zh-CN/docs/dev/get-starting/what-is-apache-doris/
Doris的SQL函数
https://doris.apache.org/zh-CN/docs/dev/sql-manual/sql-functions/string-functions/split-part
https://doris.apache.org/zh-CN/docs/dev/sql-manual/sql-functions/string-functions/regexp/
Mysql测试表
创建库
1 | create database zdb; |
行列转换测试表
创建表
1 | CREATE TABLE `t_student` ( |
插入数据
1 | INSERT INTO t_student(name,subject,score) VALUES ('张三','语文',60); |
准备数据
1 | create table t_student2 as ( |
结果如下

其他测试表
创建表
1 | CREATE TABLE `t_student_detail` ( |
插入数据
1 | INSERT INTO t_student_detail(name,phone) VALUES ('张三','15225178321'); |
Doris测试表
创建库
1 | create database zdb; |
创建表
行列转换测试表
1 | DROP TABLE IF EXISTS t_student; |
插入数据
1 | INSERT INTO t_student(id,name,subject,score) VALUES (1,'张三','语文',60); |
创建透视后的表
1 | CREATE TABLE IF NOT EXISTS t_student2 ( |
注意
字段不支持中文。
括号的最后不能有逗号。
透视查询
1 | select name, |
结果
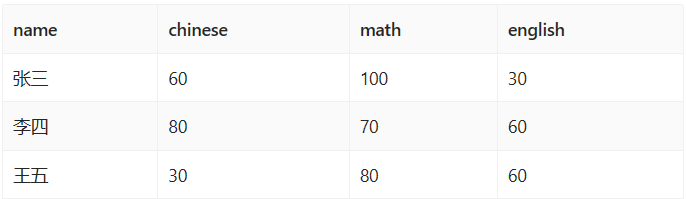
导入到透视后的表中
1 | insert into t_student2(name,chinese,math,english) select name, |
查询数据
1 | select * from t_student2; |
列转行
1 | select name,'chinese' as subject,chinese as 'score' from t_student2 |
结果
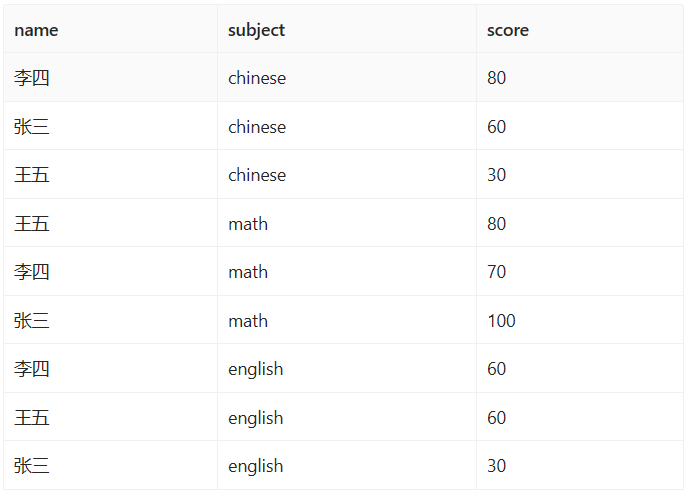
数据处理表
1 | CREATE TABLE IF NOT EXISTS t_user_hobby ( |
插入数据
1 | INSERT INTO t_user_hobby(id,name,hobby) VALUES (1,'张三','唱歌-跳舞-打篮球'); |
数据源
关系型数据源
1 | { |
读取Excel
1 | { |
目标源
追加
1 | { |
覆盖
1 | { |
行处理
过滤(单)
where
示例参数
1 | { |
空值处理(多)
COALESCE()
null替换为设置的字符
1 | select name,COALESCE(phone,'-') as phone from t_student_detail; |
处理策略
- 替换为最小值 replace_min
- 替换为最大值 replace_max
- 替换为平均值 replace_avg
- 替换为中位数 replace_median
- 替换为出现频率最高的值 replace_high_frequency
- 替换为指定值 replace_value
- 过滤整行 remove
示例参数
1 | { |
行选择(单)
- 根据行号筛选:输入正整数或负整数,分别代表TopN和BottomN。
- 根据行号区间筛选:输入两个正整数,代表区间行。
- 根据条件筛选:从左至右依次分别为设置字段、逻辑符和值。
TopN
1 | select * FROM t_student_detail LIMIT 2; |
BottomN
1 | select * from (select * FROM t_student_detail ORDER BY id desc LIMIT 2) t1 ORDER BY t1.id asc ; |
区间
1 | select * FROM t_student_detail LIMIT 2 OFFSET 2; |
dealType
- top_n
- bottom_n
- range
- filter
示例参数
top_n
1 | { |
range
1 | { |
filter
1 | { |
去重(单)
1 | SELECT DISTINCT name,subject,score FROM t_student; |
参数
1 | { |
排序(多)
1 | { |
添加序号(单)
1 | SELECT (@i:= @i + 1) AS rownum, name, subject,score FROM t_student, (SELECT @i:=0) AS rownum ORDER BY score desc; |
参数
1 | { |
值替换(多)
dealType
- str_replace 字符串替换
- regex_replace
参数
1 | { |
replace()
1 | #直接替换字符串中的部分字符 |
case when
1 | select name,case name when '张三' then '-' ELSE phone END as phone from t_student_detail; |
注意对null无效
1 | select name,case phone when null then '-' ELSE phone END as phone from t_student_detail; |
数据清洗(多)
dealType 清洗方式
- 移除首尾空格 remove_space_trim
- 移除所有空格 remove_space_all
- 移除标点符号 remove_symbol
- 移除字母 remove_letter
- 移除数字 remove_num
- 设置为大写 uppercase
- 设置为小写 lowercase
参数
1 | { |
正则替换标点符号
1 | SELECT regexp_replace('Leung Kwok Yin2语文$#', "([^0-9a-zA-Z\u4e00-\u9fa5 ]+)", ""); |
上面的在JS中没问题但是在Doris有问题,Doris不支持Unicode编码,改成如下即可
1 | SELECT regexp_replace('Leung Kwok Yin2语文$#', "([^0-9a-zA-Z一-龥 ]+)", ""); |
脱敏(多)
参数
1 | { |
脱敏
1 | select sub_replace("15225178666","****",3,4); |
或者
1 | select sub_replace("15225178666",repeat("*",4),3,4); |
上面中文乱码,使用下面的替代
1 | select replace("你好中国,我是郑州",substring("你好中国,我是郑州",3,2),repeat("*",2)); |
其中
substring(源字符串,开始索引,截取长度) 开始索引从1开始。
加密(多)
1 | SELECT name,MD5(phone)as phone FROM t_student_detail; -- 进行MD5加密 |
使用AES加解密
1 | SELECT AES_DECRYPT(AES_ENCRYPT('码客说', '1234567891011121'),'1234567891011121'); |
列处理
列选择(单)
1 | { |
派生列(多)
参数
1 | { |
派生列的名称不能和已有列重复
目前派生列支持的函数有:
数字函数
| 函数名称 | 函数及示例 | 说明 |
|---|---|---|
| 向上取整 | ceil(<column>) |
获取大于或等于取整字段的最小整数。 <column>:表示取整的字段。 |
| 向下取整 | floor(<column>) |
获取小于或等于取整字段的最大整数。 <column>:表示取整的字段。 |
| 四舍五入 | round(<column>) |
获取四舍五入后的整数。 <column>:表示四舍五入的字段。 |
| 行最小值 | least(<column>,<column>,<column>) |
获取指定行中的最小值。 <column>:表示用来比较最小值的字段,默认三个,可以有多个字段。 |
| 行最大值 | greatest(<column>,<column>,<column>) |
获取指定行中的最大值。 <column>:表示用来比较最大值的字段,默认三个,可以有多个字段。 |
字符串函数
| 函数名称 | 函数及示例 | 说明 |
|---|---|---|
| 字符拼接 (拼接符) | concat_ws("sep",str1,str2,...,strN) |
通过sep连接符将字符串拼接。sep由用户自定义。str:表示连接的字符。 |
| 字符拼接 | concat(str1, str2, ..., strN) |
不需要连接符,直接将字符串连接。str:表示连接的字符。 |
| 字符截取 | substring(<column>, pos[, len]) |
从字段中截取指定位置的len个字符。<column>:表示截取的字段;pos:表示从第几个位置开始截取,设置为正整数;len:表示一共取多少个字符,设置为正整数; |
| 转小写 | lower(<column>) |
|
| 转大写 | upper(<column>) |
|
| 字符串替换 | replace(<column>,oldstr,newstr) |
|
| 按分隔符截取 | split_part(VARCHAR content, VARCHAR delimiter, INT field) |
select split_part("hello world", " ", 1)结果hello |
日期函数
| 函数名称 | 函数及示例 | 说明 |
|---|---|---|
| 内容提取(年) | year(<column>) |
截取时间字段中的年信息。<column>:表示截取的字段; |
| 内容提取(月) | month(<column>) |
截取时间字段中的月信息。<column>:表示截取的字段; |
| 内容提取(日) | day(<column>) |
截取时间字段中的日信息。<column>:表示截取的字段; |
| 内容提取(时) | hour(<column>) |
截取时间字段中的时信息。<column>:表示截取的字段; |
| 内容提取(分) | minute(<column>) |
截取时间字段中的分信息。 <column>:表示截取的字段; |
| 内容提取(秒) | second(<column>) |
截取时间字段中的秒信息。<column>:表示截取的字段; |
示例
1 | select name,least(`语文`,`数学`,`英语`) as min_score FROM t_student2; |
范围分组列(单)
适用于数值型,日期型
参数
1 | { |
其中
useOriginal: 0 不使用原值 1 使用原值
枚举分组列(单)
适用于所有类型
参数
1 | { |
其中
useOriginal: 0 不使用原值 1 使用原值
计算列(单)
参数
1 | { |
其中
- fieldType 支持 long/double
拆分列(多)
分隔符:逗号、分号、空格、tab、-
拆分后的列将按照新字段名称_数字序号的格式按顺序依次命名,数字序号从1开始
参数
1 | { |
使用SUBSTRING_INDEX
拆分列
1 | SELECT SUBSTRING_INDEX(hobby, '-', 1) AS hobby1, |
或者
1 | SELECT SUBSTRING_INDEX(SUBSTRING_INDEX(hobby, '-', 1), '-', -1) AS hobby1, |
使用正则
1 | SELECT regexp_extract(hobby, '([^-]+)-([^-]+)-([^-]+)', 1) AS hobby1, |
使用split_part
1 | SELECT split_part(hobby, '-', 1) AS hobby1, |
合并列(多)
合并一个表的多个字段为一个新字段,和Smart不一致
1 | { |
示例
1 | SELECT concat( name,':',hobby) AS name_hobby FROM t_user_hobby; |
日期处理(多)
1 | { |
日期格式
| 名称 | 格式 |
|---|---|
| 年-月-日 时:分:秒 | %Y-%m-%d %H:%i:%s |
| 年-月-日 时:分 | %Y-%m-%d %H:%i |
| 年-月-日 | %Y-%m-%d |
| 年/月/日 时:分:秒 | %Y/%m/%d %H:%i:%s |
| 年/月/日 时:分 | %Y/%m/%d %H:%i |
| 年/月/日 | %Y/%m/%d |
| 时:分:秒 | %H:%i:%s |
| 时:分 | %H:%i |
字符传转日期
1 | select str_to_date('2014-12-21 12:34:56', '%Y-%m-%d %H:%i:%s'); |
日期转字符串
1 | select DATE_FORMAT(now(),'%Y%m%d%H%i%s'); |
两者结合
1 | select DATE_FORMAT(str_to_date('2014-12-21 12:34:56','%Y-%m-%d %H:%i:%s'), '%Y%m%d%H%i%s'); |
SQL查询(单)
1 | { |
多表JOIN(多)
joinType支持
- 左连接 left join
- 右连接 right join
- 内连接 inner join
参数
1 | { |
元数据编辑(多)
编辑页面显示 原字段、新字段、别名、数据类型、顺序调整
1 | { |
dataType可取值
| 可选值 | 说明 | Doris类型 |
|---|---|---|
| long | 整数 | BIGINT |
| double | 浮点数 | DOUBLE |
| string | 字符串 | VARCHAR |
| text | 长字符串 | STRING |
| datetime | 日期时间 | DATETIME |
| date | 日期 | DATE |
| time | 时间 | VARCHAR |
匹配为long的类型
- long
- bigint
- int
- integer
- number
匹配为double的
- float
- double
匹配为text
- longtext
- text
匹配为datetime
- datetime
- date
其他的都匹配为string
聚合(多)
参数示例
1 | { |
dealType支持
- group 分组 对应的字段不能再聚合操作
- count:统计行数
- sum:求和
- max:最大值
- min:最小值
- avg:平均值
常见聚合函数有:
COUNT():统计行数
SUM():求和
MAX():最大值
MIN():最小值
AVG():平均值
1 | select name,max(score) max_score FROM t_student GROUP BY name; |
此外,MySQL还提供一些高级聚合函数:
- STD():标准差
- VARIANCE():方差
- STDDEV_POP():总体标准差
- STDDEV_SAMP():样本标准差
- VAR_POP():总体方差
- VAR_SAMP():样本方差
示例
1 | select name,STD(score) std_score FROM t_student GROUP BY name; |
行转列(透视)(单)
参数示例
1 | { |
属性说明
- fieldName 名称列
- fieldPivot 透视列
- fieldValue 值列名称
- dealType 聚合方式
dealType
- 求和 sum
- 计数 count
- 最大值 max
- 最小值 min
通过case实现
先查出要进行行转列的列属性的值
1 | select DISTINCT subject FROM t_student; |
再生成SQL
1 | select name 姓名, |
通过if实现
1 | SELECT name as 姓名, |
列转行(单)
参数示例
1 | { |
属性说明
- fieldName 名称列
- fieldPivotList 透视反转列
- fieldPivotName 反转后的列名
- fieldValue 值列名称
实现列转行
1 | select name,'yuwen' as subject,yuwen as 'score' from t_student2 |
执行到此节点
前端一个一个节点执行