数据中台数据准备(各个数据库对比)
库名表名字段大小写
| 数据库 | 创建时 | 查询时 |
|---|---|---|
| Mysql | 区分大小写。 表名和字段名大小写和创建时一致。 |
大小写均能查询。 查询是大写返回大写,查询小写返回小写。 |
| Oracle | 不区分大小写。 表名和字段名无论创建时候大写或小写创建后都是大写。 |
大小写均能查询。 查询无论是大写还是小写,返回均是大写。 |
| SqlServer | 区分大小写。 表名和字段名大小写和创建时一致。 |
大小写均能查询。 查询是大写返回大写,查询小写返回小写。 |
| Hive | 不区分大小写。 表名和字段名无论创建时候大写或小写创建后都是小写。 |
大小写均能查询。 查询无论是大写还是小写,返回均是小写。 |
| Phoenix | 在不加双引号的时候均是大写。 加双引号的时候才区分大小写。 |
在不加双引号的时候均是大写。 加双引号的时候才区分大小写。 |
Mysql和SqlServer的规则不一致。
Mysql
区分大小写。
表名和字段名大小写和创建时一致。
创建库
1 | create DATABASE zdb_mysql; |
创建表
1 | CREATE TABLE `zdb_mysql`.`t_user` ( |
清空表
1 | TRUNCATE TABLE t_user; |
测试数据
1 | INSERT INTO `t_user` (`id`, `name`, `age`, `height`, `birthday`) VALUES (1, '蒋震南', 66, 199.49, '2017-09-09 08:38:52'); |
Oracle
不区分大小写。
表名和字段名无论创建时候大写或小写创建后都是大写。
数据类型
**字符型:**varchar、char、nchar、nvarchar、long(在数据库中是以ASCII码的格式存储的)
**数字型:**number、float(表示整数和小数)
**日期类型:**date、timestamp(存放日期和时间)
**其他数据类型:**blob、clob、bfile
服务启动与停止
停止服务
1 | sqlplus /nolog |
启动服务
1 | #启动监听 |
创建表空间
临时表空间
1 | 创建临时表空间 |
表空间
1 | -- 创建表空间 |
注意
一个用户可以有多个表空间,一个表空间可以有多个用户,但是为了方便,一个用户只设置一个表空间,这样在执行SQL的时候就不用再指定表空间了。
建用户
1 | create user zhangjian identified by zhangjian |
指定表空间给用户
1 | alter user zhangjian default tablespace ZDB; |
修改密码
1 | alter user zhangjian identified by zhangjian; |
删除用户
1 | --查看用户的连接状态 |
Oracle赋权限
1 | grant connect,resource,dba to zhangjian; |
删除表
1 | DROP TABLE T_USER; |
创建表
1 | CREATE TABLE T_USER ( |
在表空间下建表
1 | CREATE TABLE T_USER ( |
删除数据
1 | delete from T_USER; |
插入数据
1 | INSERT INTO "T_USER" ("ID", "NAME", "AGE", "HEIGHT", "BIRTHDAY") VALUES ('1', '陶杰宏', '56', '152.8', TO_DATE('2014-08-07 00:29:45', 'SYYYY-MM-DD HH24:MI:SS')); |
查询数据
1 | select * from T_USER; |
SqlServer
区分大小写。
表名和字段名大小写和创建时一致。
查询时不区分大小写,返回和查询时的大小写一致。
创建库
1 | CREATE DATABASE zdb_mssql |
创建表
1 | CREATE TABLE t_user ( |
清空表
1 | TRUNCATE TABLE t_user; |
测试数据
1 | INSERT INTO t_user (id, name, age, height, birthday) VALUES (1, '蒋震南', 66, 199.49, '2017-09-09 08:38:52'); |
Hive
不区分大小写。
表名和字段名无论创建时候大写或小写创建后都是小写。
创建库
1 | CREATE DATABASE IF NOT EXISTS zdb; |
查看表结构
1 | describe zdb.t_user_clean; |
示例
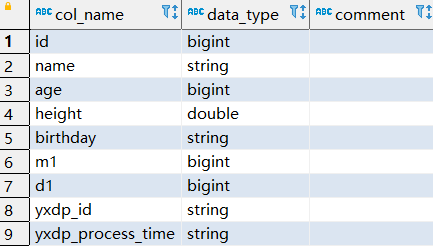
删除表
1 | drop table zdb.t_user01; |
创建表
以相同结构创建表
1 | create table t_user_trans like t_user; |
创建表
1 | create table t_user01(id bigint,name string,age bigint,height double,birthday string,yxdp_id string,yxdp_process_time string)row format delimited fields terminated by '\001'; |
清洗的表
1 | create table t_user_clean(id bigint,name string,age bigint,height double,birthday string,yxdp_id string,yxdp_process_time string)row format delimited fields terminated by '\001'; |
宽表数据准备
表1
1 | create table t_user(id bigint,name string,age bigint,height double,birthday string)row format delimited fields terminated by '\001'; |
关联的表
1 | create table t_user_detail(id bigint,userid bigint,hobby string)row format delimited fields terminated by '\001'; |
目标表
1 | create table t_user_all(id bigint,name string,age bigint,height double,birthday string,hobby string,yxdp_id string,yxdp_process_time string)row format delimited fields terminated by '\001'; |
聚合相关的表
源数据表
1 | create table t_student(id bigint,username string,subject string,score double)row format delimited fields terminated by '\001'; |
聚合数据表
1 | create table t_subject_score(id string,subject string,maxscore double,minscore double,avgscore double)row format delimited fields terminated by '\001'; |
插入数据
1 | INSERT into t_student values |
测试下聚合查询
1 | select max(score) as maxscore, avg(score) as avgscore,min(score) as minscore,subject from t_student group by subject; |
插入数据
插入数据时字段是不能选择的,要和数据库中的完全一致。
插入单条
1 | INSERT into t_user values(1, '蒋震南', 66, 199.49, '2017-09-09 08:38:52'); |
插入多条
1 | INSERT into t_user values |
插入多条
1 | INSERT into t_user_detail values |
注意
直接使用Hive插入或者在Flink中导入Hive的时候
insert into表名后的字段是不生效的,并且字段的顺序和数量一定要和数据库中保持一致!
下面的SQL
1 | insert into t_user_clean(id,name,age,height,birthday,m1,d1,yxdp_id,yxdp_process_time) select id,name,age,height,birthday,m1,d1,yxdp_id,yxdp_process |
就相当于
1 | insert into t_user_clean select id,name,age,height,birthday,m1,d1,yxdp_id,yxdp_process |
所以说我们就要保证查询时的字段顺序和Hive数据库中的字段顺序一致。
字段处理
获取Hive数据库中的字段
1 | /** |
字段要完全按照Hive的字段,所以可能处理的数据缺少我们就要补充缺少的字段
1 | //字段缺少则补充字段 |
其中默认值的函数
1 | //添加列时默认值的函数 |
DefaultValueLongUdf
1 | import org.apache.flink.table.functions.ScalarFunction; |
插入数据
1 | String hiveAllFieldStr = String.join(",", fieldNameSet); |
删除数据
Hive表删除数据不能使用DELETE FROM table_name SQL语句
删除所有数据
推荐这种方式比较快(Hive SQL支持,但是Flink SQL中不支持)
1 | truncate table t_user01; |
下面的这种方式虽然能删除所有数据,但是不推荐,运行比较慢(Flink SQL中的批模式支持,流模式不支持)。
1 | insert overwrite table t_user01 select * from t_user01 where 1=0; |
注意流模式不支持
Streaming mode not support overwrite。
删除部分数据
当需要删除某一条数据的时候,我们需要使用 insert overwrite
释义:就是用满足条件的数据去覆盖原表的数据,这样只要在where条件里面过滤需要删除的数据就可以了
删除id为1的数据:
1 | insert overwrite table t_user01 select * from t_user01 where id <> 1; |
Phoenix
库名,表名,字段名如果没加双引号都会变成大写。
添加双引号则区分大小写。
删除库
1 | DROP SCHEMA zdb; |
注意:确保该 schema 下的表都已删除,否则该 schema 会删除失败。
创建库
1 | create schema zdb; |
使用库
1 | use zdb; |
删除表
1 | drop table zdb.tuser; |
创建表
1 | CREATE TABLE IF NOT EXISTS zdb.tuser( |
插入数据
1 | upsert into tuser values(1, '蒋震南', 66, 199.49, '2017-09-09 08:38:52'); |
删除数据
1 | DELETE FROM zdb.tuser; |