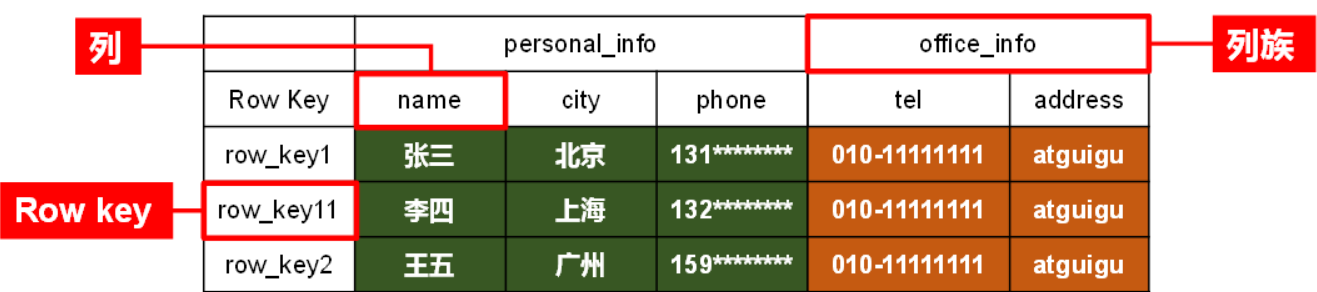
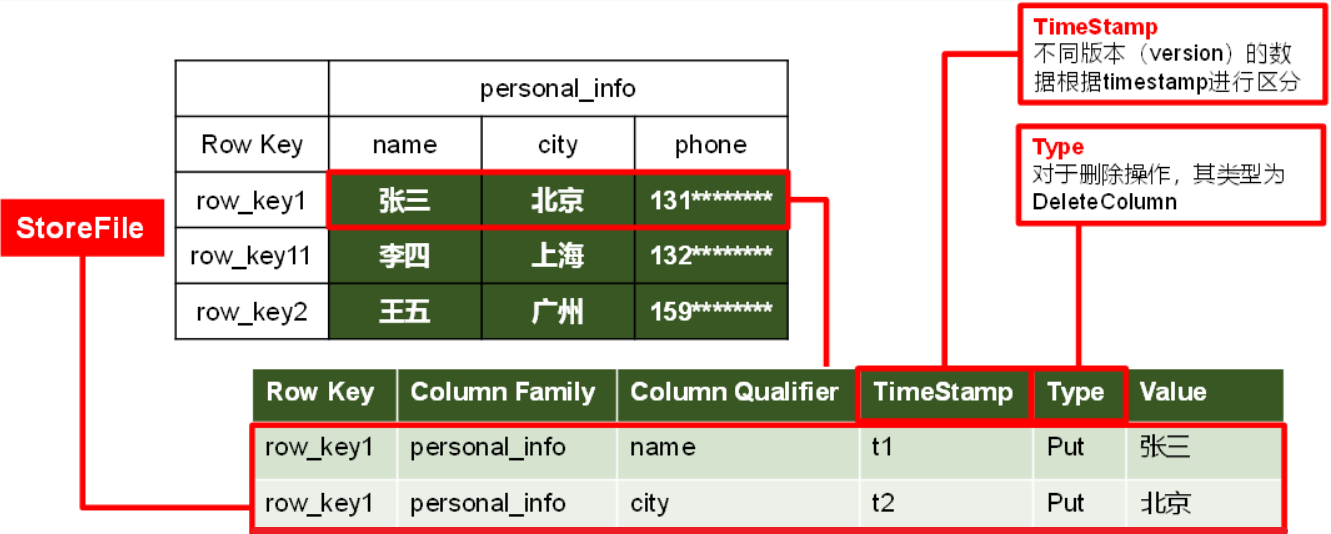
逻辑结构和物理结构 命名空间就相当于于库 命名空间下是表
逻辑结构
物理结构
在建表的时候,我们设置的字段其实是上面说的列族,列我们也可以不用。
启动和停止 先启动Zookeeper和Hadoop
启动Hbase
1 $HBASE_HOME /bin/start-hbase.sh
停止Hbase
1 $HBASE_HOME /bin/stop-hbase.sh
HMaster 的 Web 接口
http://192.168.7.101:16010
http://192.168.7.102:16010
HRegionServer 的 Web 接口
http://192.168.7.101:16030
http://192.168.7.102:16030
http://192.168.7.103:16030
HBase的操作 下面的操作主要是在hbase的shell中操作的,进入hbase shell
命名空间 注意
HBase的命名空间 表 列都是区分大小写的。
查看所有namespace
创建namespace
删除namespace
注意
删除命名空间前要删除命名空间下的所有表
删除命名空间下的表
1 2 disable 'ZDB:tuser' drop 'ZDB:tuser'
查看namespace
1 describe_namespace 'ZDB'
在namespace下创建表
1 create 'ZDB:tuser' ,'s_name' ,'s_sex' ,'s_age' ,'s_dept' ,'s_course'
查看namespace下的表
1 list_namespace_tables 'ZDB'
表操作 创建表
1 2 3 4 create 'student' ,'s_name' ,'s_sex' ,'s_age' ,'s_dept' ,'s_course' create 'teacher' ,{NAME=>'username' ,VERSIONS=>5}
创建命令空间下的表
1 create 'ZDB:tuser' ,'s_name' ,'s_sex' ,'s_age' ,'s_dept' ,'s_course'
查看表详情
1 2 3 describe 'student' describe 'ZDB:tuser'
显示所有的表
查看表数据
1 2 3 scan 'student' , {LIMIT => 1} scan 'student' , {FORMATTER => 'toString' } scan 'ZDB:tuser' , {FORMATTER => 'toString' }
插入数据
1 2 3 4 5 6 7 8 9 put 'student' ,'95001' ,'s_name' ,'LiYing' put 'student' ,'95001' ,'s_sex' ,'Male' put 'student' ,'95001' ,'s_course:math' ,'80' put 'student' ,'95001' ,'s_course:english' ,'90' put 'student' ,'95002' ,'s_name' ,'XiaoHong' put 'student' ,'95002' ,'s_sex' ,'Femal' put 'student' ,'95002' ,'s_course:math' ,'90' put 'student' ,'95002' ,'s_course:english' ,'70'
注意:一次只能为一个表的一行数据的一个列,也就是一个单元格添加一个数据,所以直接用shell命令插入数据效率很低,在实际应用中,一般都是利用编程操作数据。
当运行命令:put ‘student’,’95001’,’s_name’,’LiYing’时,即为student表添加了学号为95001,名字为LiYing的一行数据,其行键为95001。
查询数据 HBase中有两个用于查看数据的命令:
get命令,用于查看表的某一行数据;
scan命令用于查看某个表的全部数据
示例
1 2 3 4 5 6 7 get 'student' ,'95001' get 'student' ,'95001' ,'s_course' get 'student' ,'95001' ,'s_course:math' scan 'student' scan 'student' , {FORMATTER => 'toString' }
删除数据 在HBase中用delete以及deleteall命令进行删除数据操作,它们的区别是: ① delete用于删除一个数据,是put的反向操作; ② deleteall操作用于删除一行数据。
1 2 delete 'student' ,'95001' ,'s_sex' deleteall 'student' ,'95001'
修改数据 在添加数据时,HBase会自动为添加的数据添加一个时间戳,故在需要修改数据时,只需直接添加数据,HBase即会生成一个新的版本,从而完成“改”操作,旧的版本依旧保留,系统会定时回收垃圾数据,只留下最新的几个版本,保存的版本数可以在创建表的时候指定。下面是一个操作的例子:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 hbase(main):034:0> get 'student' ,'95001' COLUMN CELL s_name: timestamp=1537497681798, value=LiYing s_sex: timestamp=1537497682400, value=Male s_course:english timestamp=1537497872225, value=90 s_course:math timestamp=1537497681859, value=80 4 row(s) in 0.0310 seconds hbase(main):035:0> put 'student' ,'95001' ,'s_course:english' ,'100' 0 row(s) in 0.0130 seconds hbase(main):036:0> get 'student' ,'95001' COLUMN CELL s_name: timestamp=1537497681798, value=LiYing s_sex: timestamp=1537497682400, value=Male s_course:english timestamp=1537498062541, value=100 s_course:math timestamp=1537497681859, value=80 4 row(s) in 0.0130 seconds
删除表 删除表有两步,第一步先让该表不可用,第二步删除表。直接drop未disable的表会失败。
1 2 disable 'student' drop 'student'
查询历史的表
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 create 'teacher' ,{NAME=>'username' ,VERSIONS=>5} put 'teacher' ,'91001' ,'username' ,'Mary' put 'teacher' ,'91001' ,'username' ,'Mary1' put 'teacher' ,'91001' ,'username' ,'Mary2' put 'teacher' ,'91001' ,'username' ,'Mary3' put 'teacher' ,'91001' ,'username' ,'Mary4' put 'teacher' ,'91001' ,'username' ,'Mary5' get 'teacher' ,'91001' ,{COLUMN=>'username' ,VERSIONS=>5} hbase(main):064:0> get 'teacher' ,'91001' ,{COLUMN=>'username' ,VERSIONS=>5} COLUMN CELL username: timestamp=1537498459746, value=Mary5 username: timestamp=1537498455244, value=Mary4 username: timestamp=1537498455193, value=Mary3 username: timestamp=1537498455174, value=Mary2 username: timestamp=1537498455149, value=Mary1 5 row(s) in 0.0110 seconds
退出hbase
授权 具备Create权限的namespace Admin可以对表创建和删除、生成和恢复快照
具备Admin权限的namespace Admin可以对表splits或major compactions
授权命名空间 授权zuser01用户对ZDB下的写权限
1 grant 'zuser01' 'W' '@ZDB'
回收zuser01用户对ZDB的所有权限
当前用户:hbase
1 2 namespace_create 'ns_hbase' grant 'zuser02' , 'W' , '@ns_hbase'
授权表 当前用户:zuser02
1 2 create 'ns_hbase.tuser01' , 'name' create 'ns_hbase.tuser02' , 'name'
zuser02创建了两张表tuser01和tuser02,同时成为这两张表的owner,意味着有RWXCA权限
此时,zuser02团队的另一名成员zuser03也需要获得ns_hbase下的权限,hbase管理员操作如下
如果希望zuser03可以访问已经存在的表,则hbase管理员操作如下
当前用户:hbase
1 2 grant 'zuser03' , 'RW' , 'ns_hbase.tuser01' grant 'zuser03' , 'RW' , 'ns_hbase.tuser02'
不要只设置写权限
当前用户:hbase
1 grant 'zuser03' , 'W' , '@ns_hbase'
此时zuser03可以在ns_hbase下创建表,但是无法读、写、修改和删除ns_hbase下已存在的表
当前用户:zuser03
报错AccessDeniedException
在HBase中启用授权机制
hbase-site.xml
1 2 3 4 5 6 7 8 9 10 11 12 <property > <name > hbase.security.authorization</name > <value > true</value > </property > <property > <name > hbase.coprocessor.master.classes</name > <value > org.apache.hadoop.hbase.security.access.AccessController</value > </property > <property > <name > hbase.coprocessor.region.classes</name > <value > org.apache.hadoop.hbase.security.token.TokenProvider,org.apache.hadoop.hbase.security.access.AccessController</value > </property >
配置完成后需要重启HBase集群
Java操作 添加依赖
1 2 3 4 5 <dependency > <groupId > org.apache.hbase</groupId > <artifactId > hbase-client</artifactId > <version > 2.1.10</version > </dependency >
Java代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 package cn.psvmc;import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.hbase.HBaseConfiguration;import org.apache.hadoop.hbase.client.Connection;import org.apache.hadoop.hbase.client.ConnectionFactory;import org.apache.hadoop.hbase.Cell;import org.apache.hadoop.hbase.CellUtil;import org.apache.hadoop.hbase.TableName;import org.apache.hadoop.hbase.client.*;import org.apache.hadoop.hbase.util.Bytes;import java.io.IOException;import java.net.URISyntaxException;public class HbaseTest { public static Connection getConn () throws IOException, URISyntaxException { Configuration conf = HBaseConfiguration.create(); conf.set("hbase.zookeeper.property.clientPort" , "2181" ); conf.set("hbase.zookeeper.quorum" , "hadoop01:2181,hadoop02:2181,hadoop03:2181" ); return ConnectionFactory.createConnection(conf); } public static void close (Connection conn) throws IOException { if (null != conn) conn.close(); } public static Table getTable (Connection conn, String tablename, String namespace) throws IOException { TableName tableName1 = TableName.valueOf(namespace, tablename); return conn.getTable(tableName1); } public static void put (Connection conn, String tablename, String namespace, String rowkey, String cf, String lie, String value) throws IOException { Table table = getTable(conn, tablename, namespace); Put put = new Put (Bytes.toBytes(rowkey)); put.addColumn(Bytes.toBytes(cf), Bytes.toBytes(lie), Bytes.toBytes(value)); table.put(put); table.close(); } public static void get (Connection conn, String tablename, String namespace, String rowkey) throws IOException { Table table = getTable(conn, tablename, namespace); Get get = new Get (Bytes.toBytes(rowkey)); Result result = table.get(get); if (result != null ) { Cell[] cells = result.rawCells(); for (Cell cell : cells) { String row = Bytes.toString(CellUtil.cloneRow(cell)); String family = Bytes.toString(CellUtil.cloneFamily(cell)); String qualifier = Bytes.toString(CellUtil.cloneQualifier(cell)); String value = Bytes.toString(CellUtil.cloneValue(cell)); System.out.printf("行:%s 列族: %s 列名: %s 值: %s%n" , row, family, qualifier, value); } } table.close(); } public static void get (Connection conn, String tablename, String rowkey) throws IOException { get(conn,tablename,null ,rowkey); } public static void main (String[] args) throws IOException, URISyntaxException { Connection conn = HbaseTest.getConn(); HbaseTest.put(conn,"student" ,"default" ,"95001" ,"s_course" ,"yw" ,"100" ); HbaseTest.put(conn,"student" ,"default" ,"95001" ,"s_name" ,"zw" ,"小明" ); HbaseTest.get(conn,"student" ,"default" ,"95001" ); } }
分页 RowKey + Filter的方式 RowKey一般是必不可少的,但是如果数据量少,几十万数据,就问题不大。很多时候查询都会选择时间,如果能把时间放在RowKey里面,会极大的提升查询的效率。这里有个小技巧:如果Rowkey是按时间戳的方式递增,不要将时间放在二进制码的前面,建议将Rowkey的高位作为散列字段,由程序循环生成,低位放时间字段,这样将提高数据均衡分布在每个Regionserver实现负载均衡的几率。如果没有散列字段,首字段直接是时间信息将产生所有新数据都在一个RegionServer上堆积的热点现象,这样在做数据检索的时候负载将会集中在个别RegionServer,降低查询效率。
HBase的Scan可以通过setFilter方法添加过滤器(Filter),这也是分页、多条件查询的基础。HBase为筛选数据提供了一组过滤器,通过这个过滤器可以在HBase中的数据的多个维度(行,列,数据版本)上进行对数据的筛选操作。通常来说,通过行键,值来筛选数据的应用场景较多。这里简单举个例子,使用SingleColumnValueFilter过滤行,查找数据库中vehicle_speed列是77的数据:
1 2 3 4 5 6 7 8 9 10 FilterList filterList = new FilterList ();SingleColumnValueFilter scvf = new SingleColumnValueFilter ( Bytes.toBytes("f" ), Bytes.toBytes("vehicle_speed" ), CompareOp.EQUAL, Bytes.toBytes("77" ) ); filterList.addFilter(scvf); scan.setFilter(filterList); ResultScanner scanner = table.getScanner(scan);
Filter是可以加多个的,HBase提供十多种Filter类型。filterList.addFilter(scvf) 就是可以添加多个查询条件,然后调用setFilter函数给Scanner。
这里再简单介绍一下分页的方式:
client分页,scan查到N*M条,过滤掉N*M-M条,返回M条。对于M,N较小时比较适合。
自定义Filter,该filter可以传递offset(server端需要过滤的记录条数),在server端分页,注意,跨不同的region时需要重新计算该offset
缓存上次分页查询的最后一条,下次分页查询从这条(不包含)开始查。
查询条件固定的话,定时任务汇总表
PageFilter
使用RowKey + Filter的方式只能满足一些查询(数据量少,或者RowKey是必须的参数),包括其分页的实现并不是最优,但这是使用原生的HBase的方法,比较简单。下面介绍的方法更好,但是依赖于其他的组件。
Phoenix 最早由Salesforce.com开源的Apache Phoenix 是一个Java中间层,可以让开发者在Apache HBase上执行SQL查询,目前的版本基本支持常用的操作(分页,排序,Group By,Having,函数,序列等等)。目前的Phoenix是非常成熟的解决方案,阿里、Salesforce、eBay等互联网都在广泛使用。
Phoenix完全使用Java编写,代码位于GitHub上,并且提供了一个客户端可嵌入的JDBC驱动。它查询的实时性非常高,一般查询都在秒级返回,可以应用OLTP的系统中。在用户必须通过Phoenix来建HBase的表,它会映射到HBase的表上。Phoenix可以创建索引来提升提升多条件查询HBase的效率。比如,在查询订单的时候,可以通过订单号、时间、状态等不同的维度来查询,要想把这么多角度的数据都放到RowKey中几乎不可能。而在Phoenix中,你可以针对这几个字段建立索引。在写SQL语句的时候,如果Where语句中使用到了这些条件,Phoenix就会自动判断是否走索引。
Phoenix的索引本质上也是一张HBase的表,它维护了索引和RowKey的关系。在查询的时候,它会从索引表中先找到RowKey,然后再根据RowKey再去HBase原始数据表中获取数据。
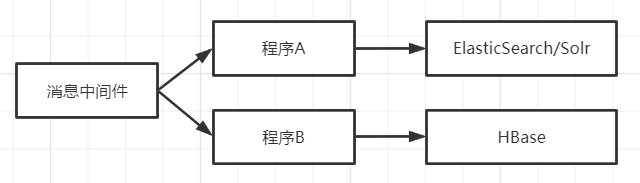
ElasticSearch/Solr + HBase 针对HBase使用RowKey访问超高的效率,我们可以把索引数据放在类似于ElasticSearch或者Solr这样的搜索引擎里面。用搜索引擎做二级索引。查询数据的时候先从搜索引擎中查询出RowKey,然后再用RowKey去获取数据。流行的搜索引擎基本可以满足查询的所有需求。
举个例子:
订单数据项有10个,但是用于查询的有5个。当数据插入HBase的同时,也把这5个数据项加上预先生成的RowKey插入搜索引擎,也就是说部分数据存储两份。
选择
同时方案的系统维护难度和对技术的要求也是逐级递增的。