前言 https://nightlies.apache.org/flink/flink-docs-release-1.12/dev/table/tableApi.html
https://nightlies.apache.org/flink/flink-docs-release-1.12/zh/dev/table/functions/udfs.html
本文使用环境版本
Hive:2.3.9
Flink:flink-1.12.7-bin-scala_2.12
依赖 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 <?xml version="1.0" encoding="UTF-8" ?> <project xmlns ="http://maven.apache.org/POM/4.0.0" xmlns:xsi ="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation ="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd" > <modelVersion > 4.0.0</modelVersion > <groupId > cn.psvmc</groupId > <artifactId > WordCount</artifactId > <version > 1.0</version > <properties > <maven.compiler.source > 8</maven.compiler.source > <maven.compiler.target > 8</maven.compiler.target > <flink.version > 1.12.7</flink.version > <hadoop.version > 2.7.7</hadoop.version > <scala.binary.version > 2.12</scala.binary.version > </properties > <repositories > <repository > <id > alimaven</id > <name > aliyun maven</name > <url > https://maven.aliyun.com/repository/public</url > </repository > </repositories > <dependencies > <dependency > <groupId > org.apache.flink</groupId > <artifactId > flink-java</artifactId > <version > ${flink.version}</version > </dependency > <dependency > <groupId > org.apache.flink</groupId > <artifactId > flink-clients_${scala.binary.version}</artifactId > <version > ${flink.version}</version > </dependency > <dependency > <groupId > org.apache.flink</groupId > <artifactId > flink-scala_${scala.binary.version}</artifactId > <version > ${flink.version}</version > </dependency > <dependency > <groupId > org.apache.flink</groupId > <artifactId > flink-streaming-java_${scala.binary.version}</artifactId > <version > ${flink.version}</version > </dependency > <dependency > <groupId > org.apache.flink</groupId > <artifactId > flink-streaming-scala_${scala.binary.version}</artifactId > <version > ${flink.version}</version > </dependency > <dependency > <groupId > org.apache.flink</groupId > <artifactId > flink-table-common</artifactId > <version > ${flink.version}</version > </dependency > <dependency > <groupId > org.apache.flink</groupId > <artifactId > flink-table-api-scala_${scala.binary.version}</artifactId > <version > ${flink.version}</version > </dependency > <dependency > <groupId > org.apache.flink</groupId > <artifactId > flink-table-api-java-bridge_${scala.binary.version}</artifactId > <version > ${flink.version}</version > </dependency > <dependency > <groupId > org.apache.flink</groupId > <artifactId > flink-table-api-scala-bridge_${scala.binary.version}</artifactId > <version > ${flink.version}</version > </dependency > <dependency > <groupId > org.apache.flink</groupId > <artifactId > flink-table-planner_${scala.binary.version}</artifactId > <version > ${flink.version}</version > </dependency > <dependency > <groupId > org.apache.flink</groupId > <artifactId > flink-json</artifactId > <version > ${flink.version}</version > </dependency > <dependency > <groupId > org.apache.flink</groupId > <artifactId > flink-statebackend-rocksdb_${scala.binary.version}</artifactId > <version > ${flink.version}</version > </dependency > <dependency > <groupId > org.apache.flink</groupId > <artifactId > flink-connector-hive_${scala.binary.version}</artifactId > <version > ${flink.version}</version > </dependency > <dependency > <groupId > org.apache.flink</groupId > <artifactId > flink-table-planner-blink_2.12</artifactId > <version > ${flink.version}</version > </dependency > <dependency > <groupId > org.apache.hive</groupId > <artifactId > hive-exec</artifactId > <version > 2.1.1</version > <exclusions > <exclusion > <groupId > org.apache.calcite</groupId > <artifactId > calcite-core</artifactId > </exclusion > <exclusion > <groupId > org.apache.calcite</groupId > <artifactId > calcite-avatica</artifactId > </exclusion > <exclusion > <artifactId > hadoop-hdfs</artifactId > <groupId > org.apache.hadoop</groupId > </exclusion > </exclusions > </dependency > <dependency > <groupId > org.apache.hadoop</groupId > <artifactId > hadoop-client</artifactId > <version > ${hadoop.version}</version > </dependency > <dependency > <groupId > org.apache.flink</groupId > <artifactId > flink-hadoop-compatibility_2.12</artifactId > <version > ${flink.version}</version > </dependency > </dependencies > <build > <plugins > <plugin > <groupId > net.alchim31.maven</groupId > <artifactId > scala-maven-plugin</artifactId > <version > 3.4.6</version > <executions > <execution > <goals > <goal > compile</goal > </goals > </execution > </executions > </plugin > <plugin > <groupId > org.apache.maven.plugins</groupId > <artifactId > maven-assembly-plugin</artifactId > <version > 3.0.0</version > <configuration > <descriptorRefs > <descriptorRef > jar-with-dependencies</descriptorRef > </descriptorRefs > </configuration > <executions > <execution > <id > make-assembly</id > <phase > package</phase > <goals > <goal > single</goal > </goals > </execution > </executions > </plugin > </plugins > </build > </project >
先看一个简单的例子
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 import org.apache.flink.table.api.{$, EnvironmentSettings , FieldExpression , SqlDialect , TableEnvironment }import org.apache.flink.table.catalog.hive.HiveCatalog object WordCount case class Student (id: String , name: String , sex: String , age: Int , department: String ) def main Array [String ]): Unit = { val settings: EnvironmentSettings = EnvironmentSettings .newInstance().useBlinkPlanner().build() val tableEnv: TableEnvironment = TableEnvironment .create(settings) val name: String = "hive" val defaultDataBase: String = "default" val hiveConfDir: String = "/data/tools/bigdata/apache-hive-2.3.9-bin/conf" val hive = new HiveCatalog (name, defaultDataBase, hiveConfDir) tableEnv.registerCatalog("myHive" , hive) tableEnv.getConfig.setSqlDialect(SqlDialect .HIVE ) tableEnv.useCatalog("myHive" ) tableEnv.useDatabase("default" ) tableEnv.executeSql("show tables" ).print() val selectTables_sql = "select id,name,password from t_user" val result = tableEnv.sqlQuery(selectTables_sql) result.execute().print() val mTable = tableEnv.from("t_user" ).select($"id" ,$"name" ,$"password" ) mTable.execute().print() } }
如上我们可以看到
Table 可以调用计算处理相关方法 Table调用execute返回TableResult
TableResult 可以用来打印
1 2 3 4 tableEnv.sqlQuery(sqlstr) tableEnv.executeSql(sqlstr)
Flink Table与Flink SQL 1 2 3 4 5 6 7 8 9 val selectTables_sql = "select id,name,password from t_user order by id desc" val result = tableEnv.sqlQuery(selectTables_sql)result .execute() .print() var mTable = tableEnv.from("t_user" ).select($"id" , $"name" , $"password" )mTable = mTable.orderBy($"id" desc()) mTable.execute().print()
排序 1 2 3 var mTable = tableEnv.from("t_user" ).select($"id" , $"name" , $"password" )mTable = mTable.orderBy($"id" desc()) mTable.execute().print()
对应的SQL模式
1 2 3 4 5 val selectTables_sql = "select id,name,password from t_user order by id desc" val result = tableEnv.sqlQuery(selectTables_sql)result .execute() .print()
别名
1 2 val mTable2 = tableEnv.from("t_user" ).select(call(new MySubstringFunction (), $"name" , 0 , 5 ) as ("name2" ))mTable2.execute().print()
添加字段 Flink SQL 1 cast (0 as bigint )as mark_del
Flink Table 1 tb01 = tb01.addColumns(call("DefaultValueNumLongUdf" ,0L ).as("mark_del" ));
添加对应的方法
1 tableEnv.createTemporarySystemFunction("DefaultValueNumLongUdf" , DefaultValueNumLongUdf.class);
方法
1 2 3 4 5 6 7 8 9 10 11 12 package com.xhkjedu.udf.trans;import org.apache.flink.table.functions.ScalarFunction;public class DefaultValueNumLongUdf extends ScalarFunction { public Long eval (Long num) { return num; } }
替换字段 Flink Table
1 tb01 = tb01.renameColumns($("b" ).as("b2" ), $("c" ).as("c2" ));
打印Schema 或者
1 2 System.out.println(Arrays.toString(tb01.getSchema().getFieldNames())); System.out.println(Arrays.toString(tb01.getSchema().getFieldDataTypes()));
DataType判断 根据字段名称获取类型
1 2 3 4 5 6 7 8 9 10 public static DataType getTypeByName (Table tb, String name) { String[] fieldNames = tb.getSchema().getFieldNames(); DataType[] fieldDataTypes = tb.getSchema().getFieldDataTypes(); for (int i = 0 ; i < fieldNames.length; i++) { if (fieldNames[i].equals(name)) { return fieldDataTypes[i]; } } return null ; }
判断类型
1 2 3 4 5 6 7 public static Boolean isLong (DataType type) { return type.getLogicalType().equals(DataTypes.BIGINT().getLogicalType()); } public static Boolean isDouble (DataType type) { return type.getLogicalType().equals(DataTypes.DOUBLE().getLogicalType()); }
Table数据保存 1 2 3 4 5 6 val tb3 = tb2.select(call("prefunc" , $"classname" , "ba年级" ).as("classname" ),$"id" ) .distinct() .select(call("subfunc" ,$"classname" ,0 ,3 ).as("classname2" )).execute().print() val sql="insert into t_class2(id,classname) select id,classname from " +tb3.toString
方式2
1 2 tableEnv.createTemporaryView("mytable" , tb3) val sql="insert into t_class2(id,classname) select id,classname from mytable"
类型推断 自动类型推导会检查函数的类和求值方法,派生出函数参数和结果的数据类型, @DataTypeHint 和 @FunctionHint 注解支持自动类型推导。
@DataTypeHint 在 Flink Table API 和 SQL 中,@DataTypeHint 注解可以用来指定自定义函数(UDF)的参数和返回值类型,它有以下作用:
帮助 Flink 引擎推断出自定义函数的参数和返回值的数据类型。
避免 Flink 自动推断类型时产生错误结果。
提高自定义函数的运行时性能。
@DataTypeHint 的使用方式:
设置返回值
1 2 3 4 public @DataTypeHint("DECIMAL(12, 3)") BigDecimal eval (double a, double b) { return BigDecimal.valueOf(a + b); }
设置参数
1 2 3 4 5 public class MyUDF extends ScalarFunction { public void eval (@DataTypeHint("STRING") String str) { } }
@FunctionHint 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 @FunctionHint( input = {@DataTypeHint("INT"), @DataTypeHint("INT")}, output = @DataTypeHint("INT") ) @FunctionHint( input = {@DataTypeHint("BIGINT"), @DataTypeHint("BIGINT")}, output = @DataTypeHint("BIGINT") ) @FunctionHint( input = {}, output = @DataTypeHint("BOOLEAN") ) public static class OverloadedFunction extends TableFunction <Object> { public void eval (Object... o) { if (o.length == 0 ) { collect(false ); } collect(o[0 ]); } }
所以使用 @DataTypeHint 可以让 Flink 更准确地知道 UDF 的数据类型信息,从而提高 Table API 和 SQL 的运行效率。
定制类型推导 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 import org.apache.flink.table.api.DataTypes;import org.apache.flink.table.catalog.DataTypeFactory;import org.apache.flink.table.functions.ScalarFunction;import org.apache.flink.table.types.inference.TypeInference;import org.apache.flink.types.Row;public static class LiteralFunction extends ScalarFunction { public Object eval (String s, String type) { switch (type) { case "INT" : return Integer.valueOf(s); case "DOUBLE" : return Double.valueOf(s); case "STRING" : default : return s; } } @Override public TypeInference getTypeInference (DataTypeFactory typeFactory) { return TypeInference.newBuilder() .typedArguments(DataTypes.STRING(), DataTypes.STRING()) .outputTypeStrategy(callContext -> { if (!callContext.isArgumentLiteral(1 ) || callContext.isArgumentNull(1 )) { throw callContext.newValidationError("Literal expected for second argument." ); } final String literal = callContext.getArgumentValue(1 , String.class).orElse("STRING" ); switch (literal) { case "INT" : return Optional.of(DataTypes.INT().notNull()); case "DOUBLE" : return Optional.of(DataTypes.DOUBLE().notNull()); case "STRING" : default : return Optional.of(DataTypes.STRING()); } }) .build(); } }
自定义函数(UDF) 在 Table API 中,根处理的数据类型以及计算方式的不同将自定义函数一共分为三种类别,
分别为 :
ScalarFunction
TableFunction
AggregationFunction
TableAggregateFunction
注意项 类型无法映射 UDF参数如果可能为空 要用Long等封装的类型,不要用long,Long会被映射被BIGINT,而long会被映射为BIGINT NOT NULL
String类型被推断为Char(1) 当我们的Java中传的类型是String时,在UDF中处理的时候,它会自动推断,比如单字符的字符串就会推断为Char(1),导致无法找到对应的处理方法。
解决方式:
指定传入的参数的类型,不进行推断
1 2 3 4 5 public class MyUDF extends ScalarFunction { public void eval (@DataTypeHint("STRING") String str) { } }
ScalarFunction标量函数 自定义标量函数可以把 0 到多个标量值映射成 1 个标量值,数据类型 里列出的任何数据类型都可作为求值方法的参数和返回值类型。
简单的说
就是把每行的数据的列进行处理。
想要实现自定义标量函数,你需要扩展 org.apache.flink.table.functions 里面的 ScalarFunction 并且实现一个或者多个求值方法。
标量函数的行为取决于你写的求值方法。求值方法必须是 public 的,而且名字必须是 eval。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 package com.xhkjedu.test;import org.apache.flink.table.annotation.DataTypeHint ;import org.apache.flink.table.api.DataTypes ;import org.apache.flink.table.api.EnvironmentSettings ;import org.apache.flink.table.api.Table ;import org.apache.flink.table.api.TableEnvironment ;import org.apache.flink.table.functions.ScalarFunction ;import static org.apache.flink.table.api.Expressions .*;public class TableApiExample public static class ZConcatString extends ScalarFunction public String eval(@DataTypeHint ("STRING" ) String s, @DataTypeHint ("STRING" ) String str2) { return s + str2; } } public static void main(String [] args) throws Exception { EnvironmentSettings settings = EnvironmentSettings .newInstance() .useBlinkPlanner() .inBatchMode() .build(); TableEnvironment tableEnv = TableEnvironment .create(settings); Table tb01 = tableEnv.fromValues( DataTypes .ROW ( DataTypes .FIELD ("name" , DataTypes .STRING ()), DataTypes .FIELD ("hobbys" , DataTypes .STRING ()) ), row("小明" , "苹果,橘子" ), row("小红" , "橘子,香蕉,菠萝" ), row("小刚" , "苹果,火龙果" ) ); tb01.printSchema(); tb01 = tb01 .select(call(ZConcatString .class , $("name" ), "同学" ).as("name" ), $("hobbys" )); tb01.execute().print(); } }
TableFunction表值函数 跟自定义标量函数一样,自定义表值函数的输入参数也可以是 0 到多个标量。但是跟标量函数只能返回一个值不同的是,它可以返回任意多行。返回的每一行可以包含 1 到多列,如果输出行只包含 1 列,会省略结构化信息并生成标量值,这个标量值在运行阶段会隐式地包装进行里。
简单的说
一行多列转多行多列。
和 Scalar Function 不同,Table Function:将一个或多个标量字段作为输入参数,且经过计算和处理后返回的是任意数量的记录,不再是单独的一个标量指标,且返回结果中可以含有一列或多列指标,根据自定义 Table Funciton函数返回值确定,因此从形式上看更像是 Table结构数据 。
在Table API中,
表函数
在Scala语言中使用方法如下:.join(Expression) 或者 .leftOuterJoin(Expression),
在Java语言中使用方法如下:.join(String) 或者.leftOuterJoin(String)。
在Sql语法中稍微有点区别:
cross join用法是LATERAL TABLE(<TableFunction>)。
LEFT JOIN用法是在join条件中加入ON TRUE。
示例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 package com.xhkjedu.test;import org.apache.flink.table.annotation.DataTypeHint;import org.apache.flink.table.annotation.FunctionHint;import org.apache.flink.table.api.DataTypes;import org.apache.flink.table.api.EnvironmentSettings;import org.apache.flink.table.api.Table;import org.apache.flink.table.api.TableEnvironment;import org.apache.flink.table.functions.TableFunction;import org.apache.flink.types.Row;import static org.apache.flink.table.api.Expressions.*;public class TableApiExample { @FunctionHint(output = @DataTypeHint("ROW<hobby STRING, length INT>")) public static class SplitFunction extends TableFunction <Row> { public void eval (String str) { for (String s : str.split("," )) { collect(Row.of(s, s.length())); } } } public static void main (String[] args) throws Exception { EnvironmentSettings settings = EnvironmentSettings .newInstance() .useBlinkPlanner() .inBatchMode() .build(); TableEnvironment tableEnv = TableEnvironment.create(settings); Table tb01 = tableEnv.fromValues( DataTypes.ROW( DataTypes.FIELD("name" , DataTypes.STRING()), DataTypes.FIELD("hobbys" , DataTypes.STRING()) ), row("小明" , "苹果,橘子" ), row("小红" , "橘子,香蕉,菠萝" ), row("小刚" , "苹果,火龙果" ) ); tb01.printSchema(); tb01 = tb01 .joinLateral(call(SplitFunction.class, $("hobbys" ))) .select($("name" ), $("hobby" ), $("length" )); tb01.execute().print(); } }
结果
调用注册后的函数
1 2 3 4 5 tableEnv.createTemporarySystemFunction("SplitFunction" , SplitFunction.class); tb01 = tb01 .joinLateral(call("SplitFunction" , $("hobbys" ))) .select($("name" ), $("hobby" ), $("length" ));
使用SQL
1 2 3 4 5 6 tableEnv.createTemporarySystemFunction("SplitFunction" , SplitFunction.class); tableEnv.registerTable("MyTable" , tb01); tb01 = tableEnv.sqlQuery( "SELECT name, hobby, length FROM MyTable, LATERAL TABLE(SplitFunction(hobbys))" );
设置别名
1 2 3 4 5 6 tableEnv.createTemporarySystemFunction("SplitFunction" , SplitFunction.class); tableEnv.registerTable("MyTable" , tb01); tb01 = tableEnv.sqlQuery( "SELECT name, newWord, newLength FROM MyTable, LATERAL TABLE(SplitFunction(hobbys)) AS T(newWord, newLength)" );
AggregationFunction聚合函数 自定义聚合函数(UDAGG)是把一个表(一行或者多行,每行可以有一列或者多列)聚合成一个标量值。
简单的说
多行多列转1行1列。
Flink Table API 中提供了User-Defined Aggregate Functions (UDAGGs),其主要功能是将一行或多行数据进行聚合然后输出一个标量值,
例如在数据集中根据 Key求取指定Value 的最大值或最小值。
下面几个方法是每个 AggregateFunction 必须要实现的:
createAccumulator() 主要用于创建 Accumulator,以用于存储计算过程中读取的中间数据,同时在 Accumulator中完成数据的累加操作accumulate() 将每次接入的数据元素累加到定义的accumulator中,另外accumulate()方法也可以通过方法复载的方式处理不同类型的数据getValue() 当完成所有的数据累加操作结束后,最后通过 getValue() 方法返回函数的统计结果,最终完成整个AggregateFunction的计算流程
AggregateFunction 的以下方法在某些场景下是必须实现的:
retract() 在 bounded OVER 窗口中是必须实现的。merge() 在许多批式聚合和会话以及滚动窗口聚合中是必须实现的。除此之外,这个方法对于优化也很多帮助。例如,两阶段聚合优化就需要所有的 AggregateFunction 都实现 merge 方法。resetAccumulator() 在许多批式聚合中是必须实现的
注意
AggregateFunction<T, ACC>中T是返回值的类型,ACC是累加器的类型。
accumulate(Accumulator acc, Long input, Long weight)中第一个参数是累加器的类型,后面的是传入参数的类型,可以传入多个参数。
AggregateFunction 接口中定义了三个 需要复写的方法,其中 add()定义数据的添加逻辑,getResult 定义了根据 accumulator 计 算结果的逻辑,merge 方法定义合并 accumulator 的逻辑。
根据权重获取值
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 import org.apache.flink.table.functions.AggregateFunction;import java.util.ArrayList;import java.util.List;public class DuplicateAggregateFunction extends AggregateFunction <Long, DuplicateAggregateFunction.Accumulator> { public static class WeightMoodel { public long value; public long weight; public WeightMoodel (long value, long weight) { this .value = value; this .weight = weight; } public WeightMoodel () { } } public static class Accumulator { public List<WeightMoodel> values = new ArrayList <>(); } @Override public Accumulator createAccumulator () { return new Accumulator (); } public void accumulate (Accumulator acc, Long input, Long weight) { acc.values.add(new WeightMoodel (input, weight)); } @Override public Long getValue (Accumulator acc) { List<WeightMoodel> values = acc.values; if (values.size() > 0 ) { long weight = values.get(0 ).weight; long value = values.get(0 ).value; for (WeightMoodel weightMoodel : values) { if (weightMoodel.weight >= weight) { value = weightMoodel.value; } } return value; } else { return null ; } } }
测试
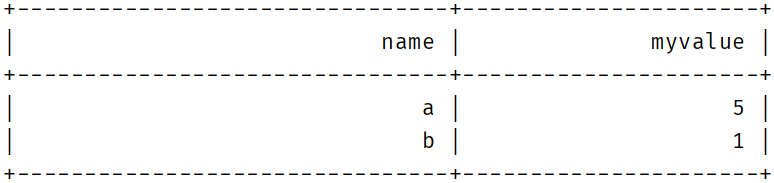
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 package com.xhkjedu.test;import org.apache.flink.table.api.DataTypes;import org.apache.flink.table.api.EnvironmentSettings;import org.apache.flink.table.api.Table;import org.apache.flink.table.api.TableEnvironment;import static org.apache.flink.table.api.Expressions.$;import static org.apache.flink.table.api.Expressions.row;public class TableApiExample { public static void main (String[] args) throws Exception { EnvironmentSettings settings = EnvironmentSettings .newInstance() .useBlinkPlanner() .inBatchMode() .build(); TableEnvironment tableEnv = TableEnvironment.create(settings); tableEnv.createTemporarySystemFunction("duplicate" , DuplicateAggregateFunction.class); Table result = tableEnv.fromValues( DataTypes.ROW( DataTypes.FIELD("name" , DataTypes.STRING()), DataTypes.FIELD("value" , DataTypes.BIGINT()), DataTypes.FIELD("weight" , DataTypes.BIGINT()) ), row("a" , 3L , 1 ), row("a" , 5L , 2 ), row("b" , 4L , 2 ), row("b" , 2L , 1 ), row("b" , 1L , 3 ) ); result.printSchema(); result = result .groupBy($("name" )) .select("name, duplicate(value,weight) as myvalue" ); result.execute().print(); } }
结果
TableAggregateFunction表值聚合函数 自定义表值聚合函数(UDTAGG)可以把一个表(一行或者多行,每行有一列或者多列)聚合成另一张表,结果中可以有多行多列。
表聚合,多对多,多行输入多行输出
用户定义的表聚合函数(User-Defined Table Aggregate Functions,UDTAF),可以把一个表中数据,聚合为具有多行和多列的结果表
用户定义表聚合函数,是通过继承 TableAggregateFunction 抽象类来实现的
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 package com.xhkjedu.test;import org.apache.flink.api.java.tuple.Tuple2;import org.apache.flink.table.functions.TableAggregateFunction;import org.apache.flink.util.Collector;public class MinMaxAggregator extends TableAggregateFunction <Tuple2<Integer, Integer>, Tuple2<Integer, Integer>> { public void accumulate (Tuple2<Integer, Integer> acc, Integer value) { if (value < acc.f0) { acc.f0 = value; } if (value > acc.f1) { acc.f1 = value; } } public void emitValue (Tuple2<Integer, Integer> acc, Collector<Tuple2<Integer, Integer>> out) { out.collect(acc); } public void merge (Tuple2<Integer, Integer> acc, Iterable<Tuple2<Integer, Integer>> its) { for (Tuple2<Integer, Integer> it : its) { if (it.f0 < acc.f0) { acc.f0 = it.f0; } if (it.f1 > acc.f1) { acc.f1 = it.f1; } } } public void resetAccumulator (Tuple2<Integer, Integer> acc) { acc.f0 = Integer.MAX_VALUE; acc.f1 = Integer.MIN_VALUE; } @Override public Tuple2<Integer, Integer> createAccumulator () { return new Tuple2 <>(); } }
测试
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 package com.xhkjedu.test;import org.apache.flink.api.java.tuple.Tuple2;import org.apache.flink.table.api.DataTypes;import org.apache.flink.table.api.EnvironmentSettings;import org.apache.flink.table.api.Table;import org.apache.flink.table.api.TableEnvironment;import org.apache.flink.table.functions.TableAggregateFunction;import org.apache.flink.types.Row;import static org.apache.flink.table.api.Expressions.*;public class TableApiExample { public static void main (String[] args) throws Exception { EnvironmentSettings settings = EnvironmentSettings .newInstance() .useBlinkPlanner() .inBatchMode() .build(); TableEnvironment tableEnv = TableEnvironment.create(settings); tableEnv.createTemporarySystemFunction("minmax" , new MinMaxAggregator ()); Table inputTable = tableEnv.fromValues( Row.of(1 ), Row.of(5 ), Row.of(3 ), Row.of(2 ) ).as("value" ); Table result = inputTable .groupBy() .flatAggregate("minmax(value) as (min_value, max_value)" ) .select("min_value, max_value" ); result.execute().print(); } }
TableAggregateFunction 要求必须实现的方法
createAccumulator()accumulate()emitValue()
首先,它同样需要一个累加器(Accumulator),它是保存聚合中间结果的数据结构。通过调用 createAccumulator() 方法可以创建空累加器
随后,对每个输入行调用函数的 accumulate() 方法来更新累加器
处理完所有行后,将调用函数的 emitValue() 方法来计算并返回最终结果
常用算法 线性分布 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 public static double linearRandom (int [] values) { int min = values[0 ]; int max = values[0 ]; for (int v : values) { min = Math.min(min, v); max = Math.max(max, v); } Random rand = new Random (); double u = rand.nextDouble(); return u * (max - min) + min; } public static void main (String[] args) { int [] values = {1 , 2 , 3 , 4 , 5 }; for (int i = 0 ; i < 5 ; i++) { System.out.println((int ) linearRandom(values)); } }
正态分布 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 public static double normalRandom (int [] values) { double mean = 0.0 ; double stdDev = 0.0 ; for (int v : values) { mean += v; } mean /= values.length; for (int v : values) { stdDev += (v - mean) * (v - mean); } stdDev = Math.sqrt(stdDev / values.length); Random r = new Random (); double u1 = r.nextDouble(); double u2 = r.nextDouble(); double z = Math.sqrt(-2 * Math.log(u1)) * Math.cos(2 * Math.PI * u2); return mean + z * stdDev; }
众数 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 public static int getMode (int [] nums) { Map<Integer, Integer> freq = new HashMap <>(); for (int num : nums) { freq.put(num, freq.getOrDefault(num, 0 ) + 1 ); } int max = 0 ; int mode = 0 ; for (Map.Entry<Integer, Integer> entry : freq.entrySet()) { if (entry.getValue() > max) { max = entry.getValue(); mode = entry.getKey(); } } return mode; }
中位数 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 public static double findMedian (int [] nums) { Arrays.sort(nums); int middle = nums.length / 2 ; if (nums.length % 2 == 1 ) { return nums[middle]; } else { return (nums[middle - 1 ] + nums[middle]) / 2.0 ; } }
平均数 1 2 3 4 5 6 7 8 9 10 11 12 13 public static double getAverage (int [] nums) { int sum = 0 ; for (int num : nums) { sum += num; } return (double ) sum / nums.length; }
聚合函数示例 注意
流处理不支持聚合操作!!!
流处理不支持聚合操作!!!
流处理不支持聚合操作!!!
空值填充 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 import org.apache.flink.table.functions.ScalarFunction;public class FillStringFix extends ScalarFunction { public String eval (String source, String txt) { if (source == null || source.equals("" )) { return txt; } else { return source; } } public Long eval (Long source, Long txt) { if (source == null ) { return txt; } else { return source; } } public Double eval (Double source, Double txt) { if (source == null ) { return txt; } else { return source; } } }
随机数 正态分布、线性分布的随机数
处理Long 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 package com.xhkjedu.udf.clean;import org.apache.flink.table.functions.AggregateFunction;import java.util.ArrayList;import java.util.List;import java.util.Random;public class HandleLongRandom extends AggregateFunction <Long, HandleLongRandom.Accumulator> { public static class Accumulator { public List<Long> values = new ArrayList <>(); public String type; public Long min; public Long max; } @Override public Accumulator createAccumulator () { return new Accumulator (); } public void accumulate (Accumulator acc, Long input, String type, Long min, Long max) { if (input != null ) { acc.values.add(input); } acc.type = type; acc.min = min; acc.max = max; } public static long normalRandom (Long[] values) { double mean = 0.0 ; double stdDev = 0.0 ; for (long v : values) { mean += v; } mean /= values.length; for (long v : values) { stdDev += (v - mean) * (v - mean); } stdDev = Math.sqrt(stdDev / values.length); Random r = new Random (); double u1 = r.nextDouble(); double u2 = r.nextDouble(); double z = Math.sqrt(-2 * Math.log(u1)) * Math.cos(2 * Math.PI * u2); return (long ) (mean + z * stdDev); } public static long linearRandom (Long[] values, Long min, Long max) { if (min == null || max == null ) { min = values[0 ]; max = values[0 ]; for (long v : values) { min = Math.min(min, v); max = Math.max(max, v); } } Random rand = new Random (); double u = rand.nextDouble(); return (long ) (u * (max - min) + min); } @Override public Long getValue (Accumulator acc) { List<Long> values = acc.values; Long[] arr = values.toArray(new Long [0 ]); if (acc.type.equals("normal" )) { return normalRandom(arr); } else { return linearRandom(arr, acc.min, acc.max); } } }
处理Double 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 package com.xhkjedu.udf.clean;import org.apache.flink.table.functions.AggregateFunction;import java.util.ArrayList;import java.util.List;import java.util.Random;public class HandleDoubleRandom extends AggregateFunction <Double, HandleDoubleRandom.Accumulator> { public static class Accumulator { public List<Double> values = new ArrayList <>(); public String type; public Double min; public Double max; } @Override public Accumulator createAccumulator () { return new Accumulator (); } public void accumulate (HandleDoubleRandom.Accumulator acc, Double input, String type, Double min, Double max) { if (input != null ) { acc.values.add(input); } acc.type = type; acc.min = min; acc.max = max; } public static double normalRandom (Double[] values) { double mean = 0.0 ; double stdDev = 0.0 ; for (double v : values) { mean += v; } mean /= values.length; for (double v : values) { stdDev += (v - mean) * (v - mean); } stdDev = Math.sqrt(stdDev / values.length); Random r = new Random (); double u1 = r.nextDouble(); double u2 = r.nextDouble(); double z = Math.sqrt(-2 * Math.log(u1)) * Math.cos(2 * Math.PI * u2); return (mean + z * stdDev); } public static double linearRandom (Double[] values, Double min, Double max) { if (min == null || max == null ) { min = values[0 ]; max = values[0 ]; for (double v : values) { min = Math.min(min, v); max = Math.max(max, v); } } Random rand = new Random (); double u = rand.nextDouble(); return u * (max - min) + min; } @Override public Double getValue (Accumulator acc) { List<Double> values = acc.values; Double[] arr = values.toArray(new Double [0 ]); if (acc.type.equals("normal" )) { return normalRandom(arr); } else { return linearRandom(arr, acc.min, acc.max); } } }
测试 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 package com.xhkjedu.test;import com.xhkjedu.udf.clean.FillStringFix;import com.xhkjedu.udf.clean.HandleLongRandom;import com.xhkjedu.udf.clean.HandleLongStat;import org.apache.flink.table.api.DataTypes;import org.apache.flink.table.api.EnvironmentSettings;import org.apache.flink.table.api.Table;import org.apache.flink.table.api.TableEnvironment;import org.apache.flink.types.Row;import static org.apache.flink.table.api.Expressions.*;public class TableApiExample { public static void main (String[] args) throws Exception { EnvironmentSettings settings = EnvironmentSettings .newInstance() .useBlinkPlanner() .inBatchMode() .build(); TableEnvironment tableEnv = TableEnvironment.create(settings); tableEnv.createTemporarySystemFunction("HandleLongRandom" , HandleLongRandom.class); tableEnv.createTemporarySystemFunction("FillStringFix" , FillStringFix.class); Table tb01 = tableEnv.fromValues( DataTypes.ROW( DataTypes.FIELD("name" , DataTypes.STRING()), DataTypes.FIELD("value" , DataTypes.BIGINT().nullable()) ), Row.of("a" , null ), Row.of("b" , 3L ), Row.of("c" , 5L ), Row.of("d" , 2L ), Row.of("e" , null ), Row.of("f" , 1L ) ); tb01.printSchema(); Table tb02 = tb01 .select(call("HandleLongRandom" , $("value" ), "linear" , 0 , 5 ).as("randomValue" )); tb01 = tb01.leftOuterJoin(tb02); tb01 = tb01.addOrReplaceColumns(call("FillStringFix" , $("value" ), $("randomValue" )).as("value" )); tb01.execute().print(); } }
众数/中位数/平均数 处理Long 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 package com.xhkjedu.udf.clean;import org.apache.flink.table.functions.AggregateFunction;import java.util.*;public class HandleLongStat extends AggregateFunction <Long, HandleLongStat.Accumulator> { public static class Accumulator { public List<Long> values = new ArrayList <>(); public String type; } @Override public Accumulator createAccumulator () { return new Accumulator (); } public void accumulate (Accumulator acc, Long input, String type) { if (input != null ) { acc.values.add(input); } acc.type = type; } public static Long getMode (Long[] nums) { Map<Long, Long> freq = new HashMap <>(); for (long num : nums) { freq.put(num, freq.getOrDefault(num, 0L ) + 1 ); } long max = 0 ; long mode = 0 ; for (Map.Entry<Long, Long> entry : freq.entrySet()) { if (entry.getValue() > max) { max = entry.getValue(); mode = entry.getKey(); } } return mode; } public static Long findMedian (Long[] nums) { Arrays.sort(nums); int middle = nums.length / 2 ; if (nums.length % 2 == 1 ) { return nums[middle]; } else { return (long ) ((nums[middle - 1 ] + nums[middle]) / 2.0 ); } } public Long getAverage (Long[] nums) { int sum = 0 ; for (long num : nums) { sum += num; } return (long ) (sum / nums.length); } @Override public Long getValue (Accumulator acc) { List<Long> values = acc.values; Long[] arr = values.toArray(new Long [0 ]); switch (acc.type) { case "mode" : return getMode(arr); case "median" : return findMedian(arr); default : return getAverage(arr); } } }
处理Double 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 package com.xhkjedu.udf.clean;import org.apache.flink.table.functions.AggregateFunction;import java.util.*;public class HandleDoubleStat extends AggregateFunction <Double, HandleDoubleStat.Accumulator> { public static class Accumulator { public List<Double> values = new ArrayList <>(); public String type; } @Override public Accumulator createAccumulator () { return new Accumulator (); } public void accumulate (Accumulator acc, Double input, String type) { if (input != null ) { acc.values.add(input); } acc.type = type; } public static Double getMode (Double[] nums) { Map<Double, Double> freq = new HashMap <>(); for (double num : nums) { freq.put(num, freq.getOrDefault(num, 0d ) + 1 ); } double max = 0 ; double mode = 0 ; for (Map.Entry<Double, Double> entry : freq.entrySet()) { if (entry.getValue() > max) { max = entry.getValue(); mode = entry.getKey(); } } return mode; } public static Double findMedian (Double[] nums) { Arrays.sort(nums); int middle = nums.length / 2 ; if (nums.length % 2 == 1 ) { return nums[middle]; } else { return (double ) ((nums[middle - 1 ] + nums[middle]) / 2.0 ); } } public Double getAverage (Double[] nums) { int sum = 0 ; for (double num : nums) { sum += num; } return (double ) (sum / nums.length); } @Override public Double getValue (Accumulator acc) { List<Double> values = acc.values; Double[] arr = values.toArray(new Double [0 ]); switch (acc.type) { case "mode" : return getMode(arr); case "median" : return findMedian(arr); default : return getAverage(arr); } } }
测试 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 package com.xhkjedu.test;import com.xhkjedu.udf.clean.FillStringFix;import com.xhkjedu.udf.clean.HandleLongRandom;import com.xhkjedu.udf.clean.HandleLongStat;import org.apache.flink.table.api.DataTypes;import org.apache.flink.table.api.EnvironmentSettings;import org.apache.flink.table.api.Table;import org.apache.flink.table.api.TableEnvironment;import org.apache.flink.types.Row;import static org.apache.flink.table.api.Expressions.*;public class TableApiExample { public static void main (String[] args) throws Exception { EnvironmentSettings settings = EnvironmentSettings .newInstance() .useBlinkPlanner() .inBatchMode() .build(); TableEnvironment tableEnv = TableEnvironment.create(settings); tableEnv.createTemporarySystemFunction("HandleLongStat" , HandleLongStat.class); tableEnv.createTemporarySystemFunction("FillStringFix" , FillStringFix.class); Table tb01 = tableEnv.fromValues( DataTypes.ROW( DataTypes.FIELD("name" , DataTypes.STRING()), DataTypes.FIELD("value" , DataTypes.BIGINT().nullable()) ), Row.of("a" , null ), Row.of("b" , 3L ), Row.of("c" , 5L ), Row.of("d" , 2L ), Row.of("e" , null ), Row.of("f" , 1L ) ); tb01.printSchema(); Table tb02 = tb01 .select(call("HandleLongStat" , $("value" ), "mode" ).as("randomValue" )); tb01 = tb01.leftOuterJoin(tb02); tb01 = tb01.addOrReplaceColumns(call("FillStringFix" , $("value" ), $("randomValue" )).as("value" )); tb01.execute().print(); } }