官网
https://nightlies.apache.org/flink/flink-docs-release-1.16/zh/docs/concepts/overview/
依赖
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
| <?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>cn.psvmc</groupId>
<artifactId>WordCount</artifactId>
<version>1.0</version>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
<flink.version>1.12.7</flink.version>
<scala.version>2.12.15</scala.version>
<hadoop.version>2.7.7</hadoop.version>
</properties>
<repositories>
<repository>
<id>alimaven</id>
<name>aliyun maven</name>
<url>https://maven.aliyun.com/repository/public</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_2.12</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-scala_2.12</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.12</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_2.12</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-hadoop-compatibility_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.4.6</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.0.0</version>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
|
加载数据
代码中加载
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| import org.apache.flink.api.scala.{DataSet, ExecutionEnvironment, _}
object WordCount {
case class Student(id: String, name: String, sex: String, age: Int, department: String)
def main(args: Array[String]): Unit = {
System.setProperty("HADOOP_USER_NAME", "hadoop");
val env = ExecutionEnvironment.getExecutionEnvironment
val stu: DataSet[(Int, String, Double)] = env.fromElements(
(19, "Wilson", 178.8),
(17, "Edith", 168.8),
(18, "Joyce", 174.8),
(18, "May", 195.8),
(18, "Gloria", 182.7),
(21, "Jessie", 184.8)
)
stu.print
}
}
|
从本地文件中加载
文件
D:\bigdata_study\stu_list.txt
1
2
3
4
| 10010,张三,女,16,IS
10011,李四,男,18,IS
10012,王五,男,19,IS
10013,赵六,女,15,CS
|
示例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| import org.apache.flink.api.scala.{DataSet, ExecutionEnvironment, _}
object WordCount {
case class Student(id: String, name: String, sex: String, age: Int, department: String)
def main(args: Array[String]): Unit = {
System.setProperty("HADOOP_USER_NAME", "root");
val environment = ExecutionEnvironment.getExecutionEnvironment
val stu_list: DataSet[Student] = environment.readCsvFile[Student](
filePath = "file:///D:/bigdata_study/stu_list.txt",
lineDelimiter = "\n",
fieldDelimiter = ",",
quoteCharacter = null,
ignoreFirstLine = false,
ignoreComments = "#",
lenient = false,
includedFields = Array[Int](0, 1, 2, 3, 4),
pojoFields = Array[String]("id", "name", "sex", "age", "department")
)
println("-------------原数据----------")
stu_list.print
}
}
|
HDFS文件
创建文件夹
1
| hadoop fs -mkdir /bigdata_study
|
查看 http://192.168.7.101:50070/explorer.html#/
导入文件
1
| hadoop fs -put /data/tools/bigdata/bigdata_study/stu_list.txt /bigdata_study
|
依赖中添加
1
2
3
4
5
6
7
8
9
10
11
|
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-hadoop-compatibility_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
|
readTextFile()
通过 readTextFile() 方法可以将本地或hdfs上的文件作为数据源读入Flink
HDFS文件
1
| val inputFile = "hdfs://192.168.7.101:9000/bigdata_study/stu_list.txt"
|
示例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| import org.apache.flink.api.scala.{DataSet, ExecutionEnvironment, _}
object WordCount {
case class Student(id: String, name: String, sex: String, age: Int, department: String)
def main(args: Array[String]): Unit = {
System.setProperty("HADOOP_USER_NAME", "root");
val environment = ExecutionEnvironment.getExecutionEnvironment
val stu_list: DataSet[Student] = environment.readCsvFile[Student](
filePath = "hdfs://192.168.7.101:9000/bigdata_study/stu_list.txt",
lineDelimiter = "\n",
fieldDelimiter = ",",
quoteCharacter = null,
ignoreFirstLine = false,
ignoreComments = "#",
lenient = false,
includedFields = Array[Int](0, 1, 2, 3, 4),
pojoFields = Array[String]("id", "name", "sex", "age", "department")
)
println("-------------原数据----------")
stu_list.print
}
}
|
服务所在服务器上执行Jar
1
2
3
4
5
|
flink run ./WordCount.jar "hdfs://192.168.7.102:9000/bigdata_study/stu_list.txt"
flink run ./WordCount.jar "hdfs://hdfsns/bigdata_study/stu_list.txt"
|
注意
假如我们配置了Hadoop NameNode的高可用
可以通过hdfs://hdfsns来访问,但是实际生效的节点为 hdfs://192.168.7.102:9000
如果在Hadoop所在的环境中 两种方式均可以访问,但是如果从外部访问只能选择hdfs://192.168.7.102:9000这种方式
创建一个YARN模式的flink集群:
1
| bash $FLINK_HOME/bin/yarn-session.sh -n 4 -jm 1024m -tm 4096m -d
|
在Yarn中执行
1
| flink run -m yarn-cluster -ynm mytest ./WordCount.jar "hdfs://192.168.7.102:9000/bigdata_study/stu_list.txt"
|
Kafka中加载
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
| import java.util
import java.util.Properties
import com.google.gson.Gson
import org.apache.flink.api.common.functions.RuntimeContext
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.connectors.elasticsearch.{ElasticsearchSinkFunction, RequestIndexer}
import org.apache.flink.streaming.connectors.elasticsearch7.{ElasticsearchSink, RestClientFactory}
import org.apache.flink.streaming.util.serialization.SimpleStringSchema
import org.apache.http.HttpHost
import org.apache.http.auth.{AuthScope, UsernamePasswordCredentials}
import org.apache.http.impl.client.BasicCredentialsProvider
import org.apache.http.impl.nio.client.HttpAsyncClientBuilder
import org.elasticsearch.action.index.IndexRequest
import org.elasticsearch.client.RestClientBuilder.HttpClientConfigCallback
import org.elasticsearch.client.{Requests, RestClientBuilder}
object FLink_Kafka_ES {
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
env.enableCheckpointing(1000)
val topic: String = "test"
val props: Properties = new Properties
props.setProperty("bootstrap.servers", "hadoop01:9092,hadoop02:9092,hadoop03:9092")
props.setProperty("group.id", "test01")
props.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer")
props.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer")
import org.apache.flink.streaming.connectors.kafka._
import org.apache.flink.api.scala._
import scala.collection.JavaConverters._
val consumer: FlinkKafkaConsumer011[String] = new FlinkKafkaConsumer011[String](topic, new SimpleStringSchema(), props)
consumer.setStartFromLatest()
val kafkaSource: DataStream[String] = env.addSource(consumer)
val mapDS: DataStream[Map[String, AnyRef]] = kafkaSource.map(x => {
(new Gson).fromJson(x, classOf[util.Map[String, AnyRef]]).asScala.toMap
})
val httpHosts: util.ArrayList[HttpHost] = new java.util.ArrayList[HttpHost]
httpHosts.add(new HttpHost("192.168.100.111", 9200, "http"))
val esSinkBuilder: ElasticsearchSink.Builder[Map[String, AnyRef]] = new ElasticsearchSink.Builder[Map[String, AnyRef]](
httpHosts,
new ElasticsearchSinkFunction[Map[String, AnyRef]] {
override def process(t: Map[String, AnyRef], runtimeContext: RuntimeContext, requestIndexer: RequestIndexer): Unit = {
val map: util.Map[String, AnyRef] = t.asJava
val indexRequest: IndexRequest = Requests
.indexRequest()
.index("flink_kafka")
.source(map)
requestIndexer.add(indexRequest)
println("data saved successfully")
}
})
esSinkBuilder.setRestClientFactory(
new RestClientFactory {
override def configureRestClientBuilder(restClientBuilder: RestClientBuilder): Unit = {
restClientBuilder.setHttpClientConfigCallback(new HttpClientConfigCallback {
override def customizeHttpClient(httpClientBuilder: HttpAsyncClientBuilder): HttpAsyncClientBuilder = {
val provider: BasicCredentialsProvider = new BasicCredentialsProvider()
val credentials: UsernamePasswordCredentials = new UsernamePasswordCredentials("elastic", "123456")
provider.setCredentials(AuthScope.ANY, credentials)
httpClientBuilder.setDefaultCredentialsProvider(provider)
}
})
}
})
esSink.setBulkFlushBackoffDelay(1)
esSink.setBulkFlushBackoffRetries(3)
esSink.setBulkFlushBackoffType(ElasticsearchSinkBase.FlushBackoffType.EXPONENTIAL)
esSink.setBulkFlushMaxActions(1)
esSink.setFailureHandler(
new ActionRequestFailureHandler {
override def onFailure(actionRequest: ActionRequest, throwable: Throwable, i: Int, requestIndexer: RequestIndexer): Unit = {
if (ExceptionUtils.findThrowable(throwable, classOf[EsRejectedExecutionException]).isPresent) {
requestIndexer.add(actionRequest)
} else if (ExceptionUtils.findThrowable(throwable, classOf[EsRejectedExecutionException]).isPresent) {
println("WARN 数据格式出错了")
} else {
println("ES 出问题了")
throw throwable
}
}
}
)
esSink
}
mapDS.setMaxParallelism(1)
mapDS.addSink(esSinkBuilder.build())
env.execute("Kafka_Flink")
}
}
|
依赖
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
| <?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>cn.cloudfall</groupId>
<artifactId>flink_elk</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<encoding>UTF-8</encoding>
<scala.version>2.12.15</scala.version>
<scala.compat.version>2.11</scala.compat.version>
<flink.version>1.9.3</flink.version>
<scala.binary.version>2.12.15</scala.binary.version>
</properties>
<dependencies>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_${scala.compat.version}</artifactId>
<version>${flink.version}</version>
<exclusions>
<exclusion>
<artifactId>scala-library</artifactId>
<groupId>org.scala-lang</groupId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-scala_${scala.compat.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_${scala.compat.version}</artifactId>
<version>${flink.version}</version>
<exclusions>
<exclusion>
<artifactId>scala-parser-combinators_${scala.compat.version}</artifactId>
<groupId>org.scala-lang.modules</groupId>
</exclusion>
<exclusion>
<artifactId>slf4j-api</artifactId>
<groupId>org.slf4j</groupId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-elasticsearch7_${scala.compat.version}</artifactId>
<version>${flink.version}</version>
<exclusions>
<exclusion>
<artifactId>slf4j-api</artifactId>
<groupId>org.slf4j</groupId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka-0.11_${scala.compat.version}</artifactId>
<version>${flink.version}</version>
<exclusions>
<exclusion>
<artifactId>slf4j-api</artifactId>
<groupId>org.slf4j</groupId>
</exclusion>
<exclusion>
<artifactId>snappy-java</artifactId>
<groupId>org.xerial.snappy</groupId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>com.google.code.gson</groupId>
<artifactId>gson</artifactId>
<version>2.3.1</version>
</dependency>
</dependencies>
<build>
<sourceDirectory>src/main/scala</sourceDirectory>
<testSourceDirectory>src/test/scala</testSourceDirectory>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>2.5.1</version>
<configuration>
<source>${maven.compiler.source}</source>
<target>${maven.compiler.target}</target>
</configuration>
</plugin>
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.2.0</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
<configuration>
<args>
<arg>-dependencyfile</arg>
<arg>${project.build.directory}/.scala_dependencies</arg>
</args>
</configuration>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>2.18.1</version>
<configuration>
<useFile>false</useFile>
<disableXmlReport>true</disableXmlReport>
<includes>
<include>**/*Test.*</include>
<include>**/*Suite.*</include>
</includes>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>2.3</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<filters>
<filter>
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
<transformers>
<transformer
implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<mainClass>cn.cloudFall.FLinkKafka</mainClass>
</transformer>
</transformers>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
|
数据导出
导出到HDFS
1
2
3
4
|
val output2 = "hdfs://bdedev/flink/Student002.csv"
ds2.writeAsCsv(output2, rowDelimiter = "\n", fieldDelimiter = "|||", WriteMode.OVERWRITE)
env.execute()
|
导出到文件
1
2
3
4
|
val output2 = "file:///D:/bigdata_study/result001.txt"
ds3.writeAsCsv(output2, rowDelimiter = "\n", fieldDelimiter = ",", WriteMode.OVERWRITE)
env.execute()
|
值转换
Flink的Transformation转换主要包括四种:
- 单数据流基本转换
- 基于Key的分组转换
- 多数据流转换
- 数据重分布转换
单数据流基本转换
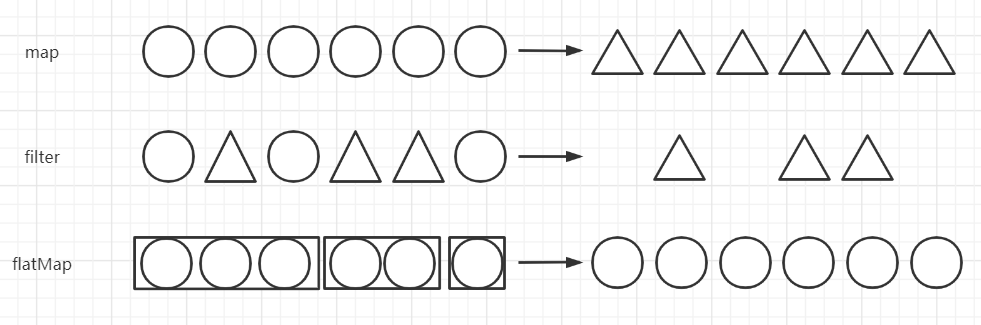
map
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| import org.apache.flink.api.scala.{DataSet, ExecutionEnvironment, _}
object Test01 {
def main(args: Array[String]): Unit = {
System.setProperty("HADOOP_USER_NAME", "hadoop");
val env = ExecutionEnvironment.getExecutionEnvironment
val stu: DataSet[(Int, String, Double)] = env.fromElements(
(19, "Wilson", 178.8),
(17, "Edith", 168.8),
(18, "Joyce", 174.8),
(18, "May", 195.8),
(18, "Gloria", 182.7),
(21, "Jessie", 184.8)
)
val data2 = stu.map((item)=>{
(item._1,item._2,BigDecimal(item._3).-(100))
})
data2.print
}
}
|
添加或删除属性
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
import org.apache.flink.api.scala.{DataSet, ExecutionEnvironment, _}
object Test01 {
def main(args: Array[String]): Unit = {
System.setProperty("HADOOP_USER_NAME", "hadoop");
val env = ExecutionEnvironment.getExecutionEnvironment
val stu: DataSet[(Int, String, Double)] = env.fromElements(
(19, "Wilson", 178.8),
(17, "Edith", 168.8),
)
val data2 = stu.map((item)=>{
(item._1,item._2,BigDecimal(item._3).-(100),"男")
})
data2.print
}
}
|
基于Key的分组转换
对数据分组主要是为了进行后续的聚合操作,即对同组数据进行聚合分析。
groupBy会将一个DataSet转化为一个GroupedDataSet,聚合操作会将GroupedDataSet转化为DataSet。如果聚合前每个元素数据类型是T,聚合后的数据类型仍为T。
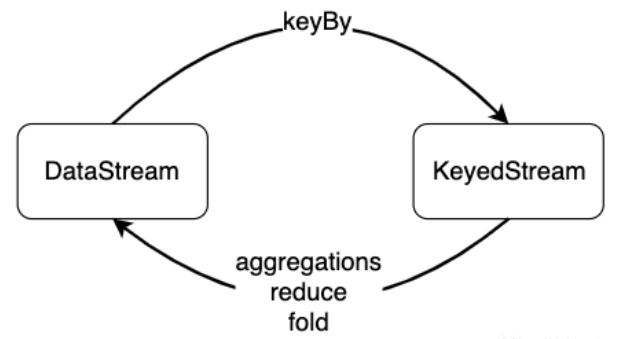
aggregation
常见的聚合操作有sum、max、min等,这些聚合操作统称为aggregation。aggregation需要一个参数来指定按照哪个字段进行聚合。跟groupBy相似,我们可以使用数字位置来指定对哪个字段进行聚合,也可以使用字段名。
与批处理不同,这些聚合函数是对流数据进行数据,流数据是依次进入Flink的,聚合操作是对之前流入的数据进行统计聚合。sum算子的功能对该字段进行加和,并将结果保存在该字段上。min操作无法确定其他字段的数值。
1
2
3
4
5
| val tupleStream = env.fromElements(
(0, 0, 0), (0, 1, 1), (0, 2, 2),
(1, 0, 6), (1, 1, 7), (1, 2, 8)
)
tupleStream.groupBy(0).sum(1).print()
|
第0个分组,第1个求和
结果
(1,3,8)
(0,3,2)
reduce
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| import org.apache.flink.api.common.operators.Order
import org.apache.flink.api.scala.{DataSet, ExecutionEnvironment, _}
object WordCount {
def main(args: Array[String]): Unit = {
System.setProperty("HADOOP_USER_NAME", "hadoop");
val env = ExecutionEnvironment.getExecutionEnvironment
val ds1: DataSet[String] = env.fromElements(
"good good study", "day day up"
)
val group_ds = ds1.flatMap(line => line.split(" ")).map(word => (word, 1)).groupBy(0)
val ds3 = group_ds.reduce((a, b) => (a._1, a._2 + b._2))
ds3.sortPartition(0, Order.ASCENDING).print
}
}
|
结果
(up,1)
(day,2)
(good,2)
(study,1)
Java和Scala对比
Java
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
| import org.apache.flink.api.common.functions.FilterFunction;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.functions.ReduceFunction;
import org.apache.flink.api.java.tuple.Tuple;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
public class FlinkDS001 {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<String> ds01 = env.fromElements("小 名", "小 红", "小 李");
DataStream<String> ds02 = ds01.filter(new FilterFunction<String>() {
@Override
public boolean filter(String s) throws Exception {
return s.split(" ").length == 2;
}
});
DataStream<String> ds03 = ds02.flatMap(new FlatMapFunction<String, String>() {
@Override
public void flatMap(String s, Collector<String> collector) throws Exception {
String[] s1 = s.split(" ");
for (String s2 : s1) {
collector.collect(s2);
}
}
});
DataStream<Tuple2<String, Integer>> ds04 = ds03.map(new MapFunction<String, Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> map(String s) throws Exception {
return new Tuple2<>(s, 1);
}
});
KeyedStream<Tuple2<String, Integer>, Tuple> ks01 = ds04.keyBy(0);
DataStream<Tuple2<String, Integer>> ds05 = ks01.reduce(new ReduceFunction<Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> reduce(Tuple2<String, Integer> stringIntegerTuple2, Tuple2<String, Integer> t1) throws Exception {
return Tuple2.of(stringIntegerTuple2.f0, stringIntegerTuple2.f1 + t1.f1);
}
});
ds05.print();
env.execute();
}
}
|
Scala
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| import org.apache.flink.api.scala._
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.api.common.RuntimeExecutionMode
object FlinkDS01 {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setRuntimeMode(RuntimeExecutionMode.BATCH)
env.setParallelism(1)
val ds01 = env.fromElements("小 名", "小 红", "小 李")
val ds02 = ds01.filter(s => s.split(" ").length == 2)
val ds03 = ds02.flatMap { str => str.split(" ") }
val ds04 = ds03.map(s=>(s, 1))
val ks01 = ds04.keyBy(_._1)
val ds05 = ks01.reduce((a, b) => (a._1, a._2 + b._2))
ds05.print
env.execute
}
}
|
日志报错
ERROR StatusLogger No log4j2 configuration file found. Using default configuration: logging only errors to the console
原因:
在pom.xml文件中导入了log4j的依赖:
1
2
3
4
5
| <dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>2.9.0</version>
</dependency>
|
但是,log4j2的配置文件并没有导入,尝试导入log4j.properties ,但并不行,需要导入log4j2.xml
解决方式
在工程的resources目录下新建一个文件:log4j2.xml ,
然后在该文件中下入以下配置信息:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
| <?xml version="1.0" encoding="UTF-8"?>
<Configuration>
<Appenders>
<Console name="STDOUT" target="SYSTEM_OUT">
<PatternLayout pattern="%d %-5p [%t] %C{2} (%F:%L) - %m%n"/>
</Console>
<RollingFile name="RollingFile" fileName="logs/strutslog1.log"
filePattern="logs/$${date:yyyy-MM}/app-%d{MM-dd-yyyy}-%i.log.gz">
<PatternLayout>
<Pattern>%d{MM-dd-yyyy} %p %c{1.} [%t] -%M-%L- %m%n</Pattern>
</PatternLayout>
<Policies>
<TimeBasedTriggeringPolicy />
<SizeBasedTriggeringPolicy size="1 KB"/>
</Policies>
<DefaultRolloverStrategy fileIndex="max" max="2"/>
</RollingFile>
</Appenders>
<Loggers>
<Logger name="com.opensymphony.xwork2" level="WAN"/>
<Logger name="org.apache.struts2" level="WAN"/>
<Root level="warn">
<AppenderRef ref="STDOUT"/>
</Root>
</Loggers>
</Configuration>
|
机器学习Alink
Spark对应的机器学习框架SparkML
Flink对应的机器学习框架FlinkML/Alink
FlinkML
https://github.com/apache/flink-ml
1
2
3
4
5
| <dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-ml_2.12</artifactId>
<version>1.9.3</version>
</dependency>
|
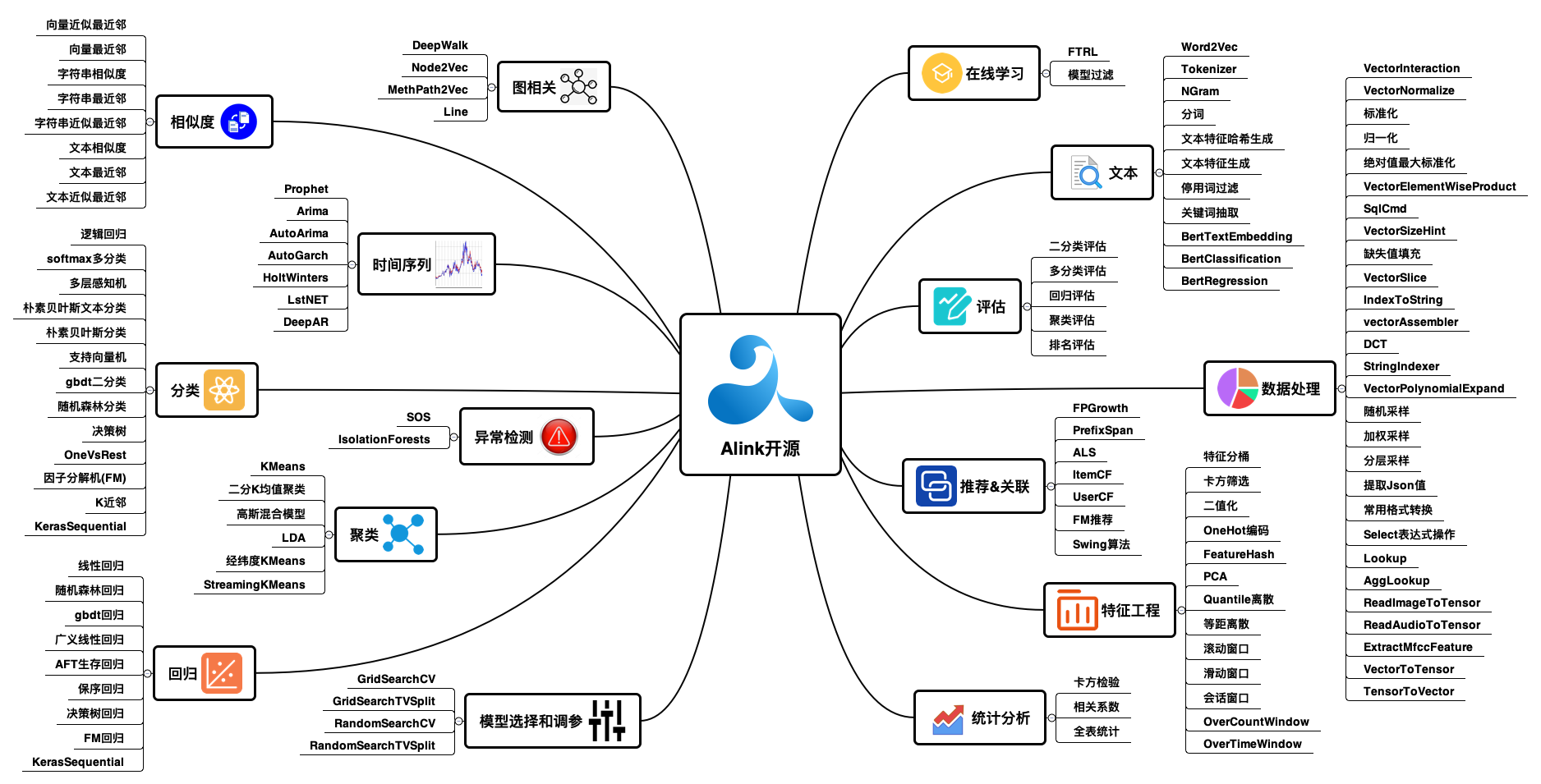
Alink
Alink与SparkML算法相比,Alink算法更全面,性能更优异,场景更丰富(同时支持流批),本地化更出色(支持中文分词)是快速搭建在线机器学习系统的不二之选。
镜像仓库:Alink
教程:https://www.yuque.com/pinshu/alink_tutorial/book_java