Hive中SQL语法及连接工具
Hive数据类型
Hive中的数据类型分为两类:
基本类型和复杂类型
基本类型包含:
tinyint,smallint,int,bigint,float,double,boolean,string,timestamp,binary复杂类型:
array,map和structarray:数组类型,对应了Java中的集合或者数组。
连接的两种方式
启动Hive
这种方式只能连接本地的Hive
1 | $HIVE_HOME/bin/hive |
查询表
1 | show tables; |
Beeline连接
这种方式可以连接远程的Hive服务
启动Hive服务
1 | nohup $HIVE_HOME/bin/hiveserver2& |
连接Hive服务
1 | beeline -n hive -u jdbc:hive2://hadoop01:10000 |
其中
- -u 设置连接地址
- -n 设置连接用户名
SQL语法
查询
创建库
1 | CREATE DATABASE IF NOT EXISTS zdb; |
查询库
1 | show databases; |
查询表
1 | show tables; |
显示所有以t_user开头的表
1 | show tables 't_user*'; |
显示表中有多少分区
1 | show partitions t_user03; |
创建表
删除已存在的表
1 | drop table t_user01; |
创建表设置分隔符
hive 默认的字段分隔符为ascii码的控制符\001,建表的时候用fields terminated by '\001'。
如果要测试的话,造数据在vi 打开文件里面,用ctrl+v然后再ctrl+a可以输入这个控制符\001。按顺序,\002的输入方式为ctrl+v,ctrl+b。以此类推。
1 | create table t_user01(id int,name string)row format delimited fields terminated by '\001'; |
以相同结构创建表
1 | create table t_user02 like t_user01; |
创建表设置分区
1 | create table t_user03(id int,name string) partitioned by (m1 int,d1 int) row format delimited fields terminated by '\001'; |
显示表的结构信息
1 | describe tablename; |
修改表名字
1 | alter table table01 rename to table02; |
在原表上新添加一列
1 | alter table tablename add columns(new_col2 int comment 'a commment'); |
删除表
1 | drop table tablename; |
创建表设置编码和注释
1 | CREATE TABLE table03 ( |
插入数据
直接插入
1 | INSERT INTO t_user01(id,name) VALUES (1,'李四'); |
查询插入
查询插入
1 | INSERT INTO t_user02(id,name) select id,name from t_user; |
查询覆盖
insert overwrite:覆盖表中已存在的数据
1 | insert overwrite table t_user02 select id,name from t_user; |
注意括号内的是分区字段
- 静态插入数据:要求插入数据时指定与建表时相同的分区字段,如:
1 | insert overwrite tablename (year='2017', month='03') select a, b from tablename2; |
- 动静混合分区插入:要求指定部分分区字段的值,如:
1 | insert overwrite tablename (year='2017', month) select a, b from tablename2; |
- 动态分区插入:只指定分区字段,不用指定值,如:
1 | insert overwrite tablename (year, month) select a, b from tablename2; |
导入导出
export和import主要用于两个Hadoop平台集群之间Hive表迁移
先用export导出后,再将数据导入。
注意
导出的位置在HDFS中。
不用创建文件夹,导出的时候会自动创建。
从a集群中导出hive表数据:
1 | export table default.t_user01 to '/export_hive/t_user01'; |
向b集群中导入数据到hive表:
1 | import table t_user01 from '/export_hive/t_user01'; |
向表中Load数据
1 | load data [local] inpath '路径' [overwrite] into table 表名 [partition (分区字段=值,…)]; |
overwrite:表示覆盖表中已有数据,否则表示追加
如:
从本地文件系统加载数据到hive表
1 | load data local inpath '/data/t_user.txt' into table t_user; |
从HDFS文件系统加载数据覆盖hive表
1 | dfs -put /root/t_user.txt /wcinput; |
创建表时加载数据
(1)创建表时使用查询语句as select
1 | create table if not exists t_user05 as select * FROM t_user01; |
(2)创建表时通过location指定加载数据路径
视图
创建视图:
1 | CREATE VIEW t_user_view AS SELECT * FROM t_user WHERE id !=9999; |
查看视图详细信息:
1 | DESCRIBE EXTENDED t_user_view; |
函数
显示所有函数
1 | show functions; |
查看函数的用法
1 | describe function substr; |
其他
查看数组、map、结构
1 | select col1[0],col2['b'],col3.c from complex; |
查看数组、map、结构
1 | select col1[0],col2['b'],col3.c from complex; |
内连接:
1 | SELECT sales., things. FROM sales JOIN things ON (sales.id = things.id); |
查看hive为某个查询使用多少个MapReduce作业
1 | Explain SELECT sales., things. FROM sales JOIN things ON (sales.id = things.id); |
外连接:
1 | SELECT sales., things. FROM sales LEFT OUTER JOIN things ON (sales.id = things.id); |
in查询:Hive不支持,但可以使用LEFT SEMI JOIN
1 | SELECT * FROM things LEFT SEMI JOIN sales ON (sales.id = things.id); |
Map连接:
Hive可以把较小的表放入每个Mapper的内存来执行连接操作
1 | SELECT /+ MAPJOIN(things) / sales., things. FROM sales JOIN things ON (sales.id = things.id); |
造数据
data_create.sh
1 | rm -rf ./user_data.txt |
注意分隔符\001的写法。
运行脚本
1 | sh data_create.sh |
进入hive
1 | hive |
删除表
1 | drop table t_user01; |
创建表
1 | create table t_user01(id int,name string) row format delimited fields terminated by '\001'; |
导入数据
1 | LOAD DATA LOCAL INPATH '/root/user_data.txt' OVERWRITE INTO TABLE t_user01; |
换行符和分隔符问题
如果数据中有换行符,导入后数据就会变成多条
方式1
Hive创建表的时候 设置特殊的分隔符和换行符
1 | create table t_user03(id int,name string)row format delimited fields terminated by '\001' LINES TERMINATED BY '\n'; |
Hive默认使用的行分隔符是'\n'分隔符 ,也可以加一句:LINES TERMINATED BY '\n' ,加不加效果一样。
比较扯得是
Hive能指定行分隔符,但是只能是
'\n'。
方式2
使用 Flink 的字符串处理函数替换掉换行符
RichSourceFunction中
在继承RichSourceFunction<Row>的方法中直接替换字符串
Flink SQL
1 | SELECT REGEXP_REPLACE(string, '\n', ' ') FROM table; |
Flink Table
1 | tb01 = tb01 |
Hive连接工具DBever
链接:https://pan.baidu.com/s/1XjhohO-JV7_PTPaD85sEtg
提取码:psvm
启动Hive服务
1 | nohup $HIVE_HOME/bin/hiveserver2& |
连接Hive
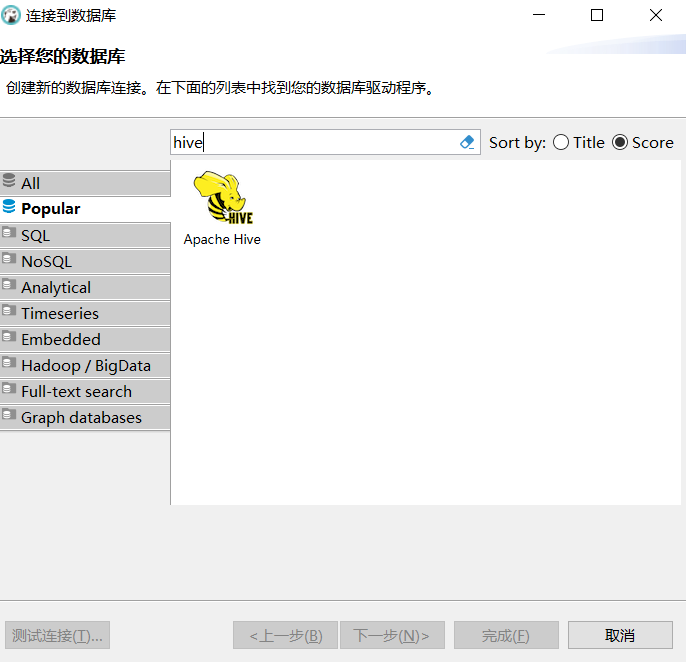
设置地址
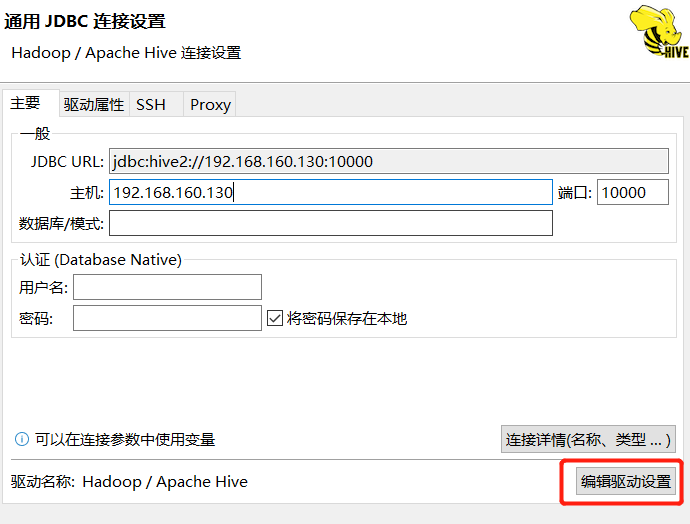
默认驱动会从Github上下载,但是下载超时
这里建议添加本地驱动
下载地址:
链接:https://pan.baidu.com/s/1XjhohO-JV7_PTPaD85sEtg
提取码:psvm
下载其中的两个Jar
- hive-jdbc-2.1.0-standalone.jar
- hadoop-common-2.7.7.jar
添加本地驱动
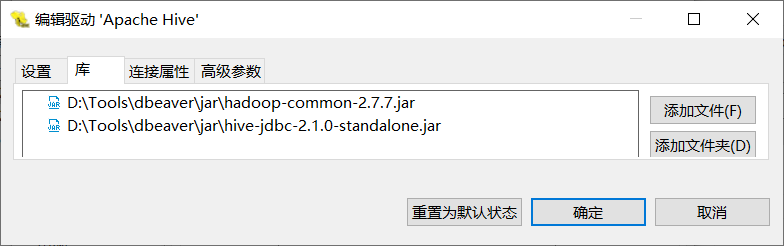
这样我们就可以连接了。