数据类型 概要 Go 语言中的数据类型主要包括以下几种:
基本数据类型:
如整数类型(int, int8, int16, int32, int64, uint, uint8, uint16, uint32, uint64, uintptr)、
浮点数类型(float32, float64)、
复数类型(complex64, complex128)、
布尔类型(bool)、
字符串类型(string)、
字节类型(byte, rune)等。
复合数据类型:
如数组(array)、切片(slice)、字典(map)、结构体(struct)、函数(function)、通道(channel)、接口(interface)等。
特殊数据类型:
如空类型(nil)和错误类型(error)。
跟Java不同的是,所有的基本数据类型也可以使用对应的指针形式变成引用类型。
引用类型
注意
结构体是值复制,结构体指针是引用复制。
数组(array)也是值类型
nil 相信写过Golang的程序员对下面一段代码是非常非常熟悉的了:
error其实一个接口,内置的,我们看下它的定义
1 2 3 type error interface { Error() string }
当出现不等于nil的时候,说明出现某些错误了,需要我们对这个错误进行一些处理,而如果等于nil说明运行正常。
那什么是nil呢?查一下词典可以知道,nil的意思是无,或者是零值。零值,zero value。
在Go语言中,如果你声明了一个变量但是没有对它进行赋值操作,那么这个变量就会有一个类型的默认零值。
这是每种类型对应的零值:
1 2 3 4 5 6 7 8 9 10 bool -> false number -> 0 string -> "" pointer -> nil slice -> nil map -> nil channel -> nil function -> nil interface -> nil
举个例子,当你定义了一个struct:
1 2 3 4 5 6 7 type Person struct { AgeYears int Name string Friends []Person } var p Person
字符串 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 package mainimport ( "fmt" "strings" ) func main () str1 := "1234 56789" fmt.Println("str1:" , str1, "len:" , len (str1)) str2 := string (str1[1 :5 ]) fmt.Println("str2:" , str2, "len:" , len (str2)) str3 := strings.TrimSpace(str2) fmt.Println("str3:" , str3, "len:" , len (str3)) str4 := strings.Split(str1, " " ) fmt.Println("str4:" , str4, "len:" , len (str4)) }
结果
str1: 1234 56789 len: 10
字符串拼接
1 2 3 4 var progress = 2 var target = 8 title := fmt.Sprintf("已采集%d个药草, 还需要%d个完成任务" , progress, target)
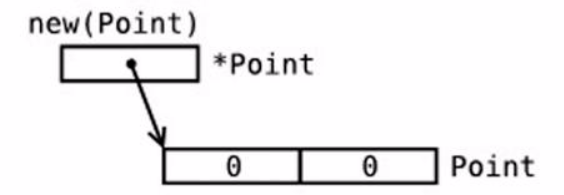
指针与值 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 package mainimport "fmt" func main () var a int = 20 var b *int b = &a fmt.Printf("&a 变量的地址是: %x\n" , &a) fmt.Printf("a 变量的值是: %d\n" , a) fmt.Printf("a 变量的值是: %d\n" , *&a) fmt.Printf("b 变量储存的指针地址: %x\n" , b) fmt.Printf("*b 变量的值: %d\n" , *b) }
结果
&a 变量的地址是: c000012088
总结
* 定义指针,指针前加*则是取变量的值&则是取变量的指针
array(数组)长度不变 1 2 3 4 5 6 var arr0 [3 ]int fmt.Println("arr0" , arr0) arr1 := [3 ]int {1 , 2 , 3 } fmt.Println("arr1" , arr1) arr2 := [3 ]int {} fmt.Println("arr2" , arr2)
结果
arr0 [0 0 0]
slice(切片)长度可变 与数组相比,切片的长度是不固定的,并且切片是可以进行扩容。
切片对象非常小,是因为它是只有3个字段的数据结构:一个是指向底层数组的指针,一个是切片的长度,一个是切片的容量。这3个字段,就是Go语言操作底层数组的元数据,有了它们,我们就可以任意的操作切片了。
1 2 var s1 []int s1 = append (s1, 110 )
创建切片 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 package testimport ( "fmt" "testing" ) func TestSlice (t *testing.T) var s1 []int printSlice(s1) s1 = append (s1, 110 ) printSlice(s1) s2 := []int {} printSlice(s2) s3 := make ([]int , 0 , 10 ) printSlice(s3) s4 := new ([]int ) printSlice(*s4) } func printSlice (x []int ) fmt.Printf("len=%d cap=%d slice=%v\n" , len (x), cap (x), x) }
结果
len=0 cap=0 slice=[]
切片删除元素 从开头删除
删除开头的元素可以直接移动数据指针:
1 2 3 a = []int {1 , 2 , 3 } a = a[1 :] a = a[N:]
也可以不移动数据指针,但是将后面的数据向开头移动,可以用 append 原地完成(所谓原地完成是指在原有的切片数据对应的内存区间内完成,不会导致内存空间结构的变化):
1 2 3 a = []int {1 , 2 , 3 } a = append (a[:0 ], a[1 :]...) a = append (a[:0 ], a[N:]...)
还可以用 copy() 函数来删除开头的元素:
1 2 3 a = []int {1 , 2 , 3 } a = a[:copy (a, a[1 :])] a = a[:copy (a, a[N:])]
从中间位置删除
对于删除中间的元素,需要对剩余的元素进行一次整体挪动,同样可以用 append 或 copy 原地完成:
1 2 3 4 5 a = []int {1 , 2 , 3 , ...} a = append (a[:i], a[i+1 :]...) a = append (a[:i], a[i+N:]...) a = a[:i+copy (a[i:], a[i+1 :])] a = a[:i+copy (a[i:], a[i+N:])]
从尾部删除
1 2 3 a = []int {1 , 2 , 3 } a = a[:len (a)-1 ] a = a[:len (a)-N]
删除开头的元素和删除尾部的元素都可以认为是删除中间元素操作的特殊情况,下面来看一个示例。
【示例】删除切片指定位置的元素。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 package mainimport "fmt" func main () seq := []string {"a" , "b" , "c" , "d" , "e" } index := 2 fmt.Println(seq[:index], seq[index+1 :]) seq = append (seq[:index], seq[index+1 :]...) fmt.Println(seq) }
代码输出结果:
[a b] [d e]
代码说明如下:
seq[:index] 表示的就是被删除元素的前半部分,值为 [1 2],seq[index+1:] 表示的是被删除元素的后半部分,值为 [4 5]。
使用 append() 函数将两个切片连接起来。
数组和切片
1 2 3 4 5 6 a1 := [10 ]int {1 , 2 , 3 , 4 , 5 , 6 , 7 , 8 , 9 , 10 } s2 := []int {} s3 := a1[3 :5 ] s4 := a1[3 :] fmt.Println(a1, s2, s3, s4)
数组、切片和列表
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 package mainimport ( "container/list" "fmt" ) func main () arr1 := [6 ]int {1 , 2 , 3 , 4 } arr1[5 ] = 9 for _, x := range arr1 { fmt.Print(x, " " ) } fmt.Print("\n" ) fmt.Println("arr1" , " 长度:" , len (arr1), "值:" , arr1) var arr2 [3 ]int arr2[2 ] = 9 fmt.Println("arr2" , " 长度:" , len (arr2), "值:" , arr2) arr3 := [3 ][2 ]string { {"张" , "三" }, {"李" , "四" }, } fmt.Println("arr3" , " 长度:" , len (arr3), "值:" , arr3) s1 := []string {"a" , "b" } s1 = append (s1, "c" ) fmt.Println("s1" , " 长度:" , len (s1), "值:" , s1) var list1 = list.List{} l1 := list1.PushFront(1 ) l2 := list1.PushBack(2 ) list1.InsertAfter("after" , l1) list1.InsertBefore("before" , l2) printlist(list1) fmt.Println("list1" , " 长度:" , list1.Len(), "值:" , list1) list1.Remove(l2) list2 := list.New() fmt.Println("list2" , " 长度:" , list2.Len(), "值:" , list2) } func printlist (lists list.List) fmt.Print("list1" , " " ) for x := lists.Front(); x != nil ; x = x.Next() { fmt.Print(x.Value, " " ) } fmt.Println("" ) }
结果
1 2 3 4 5 6 7 8 1 2 3 4 0 9 arr1 长度: 6 值: [1 2 3 4 0 9 ] arr2 长度: 3 值: [0 0 9 ] arr3 长度: 3 值: [[张 三] [李 四] [ ]] s1 长度: 3 值: [a b c] list1 1 after before 2 list1 长度: 4 值: {{0xc00007a3f0 0xc00007a420 <nil > <nil >} 4 } list2 长度: 0 值: &{{0xc00007a4e0 0xc00007a4e0 <nil > <nil >} 0 }
list 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 package testimport ( "container/list" "fmt" "testing" ) type User struct { Name string Age int } func TestList (t *testing.T) lis := list.New() lis.PushBack(User{Name: "小明" ,Age: 18 }) lis.PushFront(User{Name: "小红" ,Age: 16 }) for i := lis.Front(); i != nil ; i = i.Next() { fmt.Println(i.Value) } for i := lis.Back(); i != nil ; i = i.Prev() { fmt.Println(i.Value.(User).Name) } }
array、slice和list
map 创建的方式
1 2 3 4 5 6 7 8 9 10 11 12 13 14 userinfo := map [string ]string {"name" :"xiaoming" } userinfo["name" ] userinfo["name" ] = "xiaohong" userinfo["age" ] = "18" userinfo := map [string ]string {} var userinfo map [string ]string
使用make创建
1 2 3 userinfo := make (map [string ]string ,10 ) userinfo["age" ] = "18"
使用new创建,返回的是指针
1 2 userinfo := new (map [string ]string )
注意:
键不能重复,必须为可哈希的类型(int/bool/float/string/array)
如
1 2 3 v1 := make (map [[2 ]int ]float32 ) v1[[2 ]int {1 ,1 }] = 1.1 v1[[2 ]int {1 ,2 }] = 1.2
interface/struct 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 package mainimport ( "fmt" ) type Phone interface { call() } type NokiaPhone struct {} func (nokiaPhone NokiaPhone) fmt.Println("I am Nokia, I can call you!" ) } type IPhone struct {} func (iPhone IPhone) fmt.Println("I am iPhone, I can call you!" ) } func main () var phone Phone phone = new (NokiaPhone) phone.call() phone = new (IPhone) phone.call() }
结果
I am Nokia, I can call you!
结构体(类?) 模仿类 与其它面向对象语言相比,Go 的方法似乎有些晦涩。它并不像Java一样定义类,创建类的实例调用其方法,它其实没有类的概念,只是改造了方法,让方法可以设置可以调用的结构而已。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 package mainimport "fmt" type User struct { name string email string } func (u User) int32 { fmt.Println("Email:" , u.email) return 0 } func (u *User) string ) { u.email = email } func main () var muser User = User{ name: "剑行者" , email: "" , } muser.changeEmail("183518918@qq.com" ) result := muser.notify() fmt.Println("result:" , result) }
关于值接收者和指针接收者,我们会发现changeEmail,因为我们要操作原结构数据,所以应该传指针才对
但是我们可以不去指针这是因为Go 在编译的时候有一个隐式转换,将其转换为正确的接收者类型。
就像下面这样:
1 (&muser).changeEmail("183518918@qq.com" )
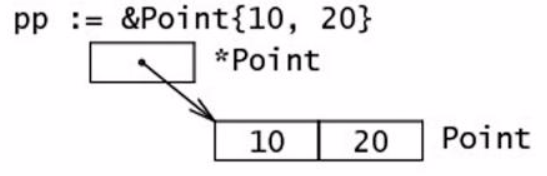
初始化方式 三种初始化结构体的方式:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 var u Useru.a = 1 u.b = 2 u := new (User) u := User{a, b} u := &User{}
使用 var u User 会给 t 分配内存,并零值化内存,但是这个时候的 t 的类型是 Tuser := new(User),变量 t 则是一个指向 T 的指针
第2种 使用 new 初始化:
第3种 使用结构体字面量初始化:
第4种
error 自定义error消息
获取错误信息
1 fmt.Println(err.Error())
循环遍历 基本 1 2 3 4 5 6 7 8 9 10 11 package mainimport "fmt" func main () sum := 0 for i := 0 ; i <= 10 ; i++ { sum += i } fmt.Println(sum) }
range(切片) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 package mainimport "fmt" func main () strings := []string {"google" , "runoob" } for i, s := range strings { fmt.Println(i, s) } numbers := [6 ]int {1 , 2 , 3 , 5 } for i, x := range numbers { fmt.Printf("第 %d 位 x 的值 = %d\n" , i, x) } }
结果
0 google
range(map) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 package mainimport "fmt" func main () var countryCapitalMap map [string ]string countryCapitalMap = make (map [string ]string ) countryCapitalMap["France" ] = "巴黎" countryCapitalMap["Italy" ] = "罗马" countryCapitalMap["Japan" ] = "东京" countryCapitalMap["India " ] = "新德里" for country := range countryCapitalMap { fmt.Println(country, "首都是" , countryCapitalMap[country]) } fmt.Println("" ) for country, capital := range countryCapitalMap { fmt.Println(country, "首都是" , capital) } }
结果
India 首都是 新德里
France 首都是 巴黎
Switch Go 语言中的 switch 语句不需要显式地使用 break 关键字来结束每个 case,一旦匹配到一个 case,后续的 case 不会被执行。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 package mainimport "fmt" func main () day := "Monday" switch day { case "Monday" : fmt.Println("Today is Monday." ) case "Tuesday" : fmt.Println("Today is Tuesday." ) case "Wednesday" : fmt.Println("Today is Wednesday." ) case "Thursday" : fmt.Println("Today is Thursday." ) case "Friday" : fmt.Println("Today is Friday." ) case "Saturday" , "Sunday" : fmt.Println("It's the weekend!" ) default : fmt.Println("Invalid day." ) } }
类型转换 []byte和string 在Go语言中,可以使用[]byte和string类型之间进行转换。
这两种类型之间的转换可以通过类型转换或者使用标准库中的函数来完成。
[]byte到string的转换:
可以使用string()函数将[]byte转换为string:
1 2 byteSlice := []byte {'H' , 'e' , 'l' , 'l' , 'o' } str := string (byteSlice)
string到[]byte的转换:
可以使用[]byte()函数将string转换为[]byte:
1 2 str := "Hello" byteSlice := []byte (str)
需要注意的是,在Go中,string是不可变的,而[]byte是可变的。
因此,将string转换为[]byte后,可以修改[]byte中的内容,但是不能直接修改string的内容。
示例:
1 2 3 4 5 str := "Hello" byteSlice := []byte (str) byteSlice[0 ] = 'h' modifiedStr := string (byteSlice) fmt.Println(modifiedStr)
但是,直接修改string中的内容是不被允许的:
这些方法可以方便地在string和[]byte之间进行转换。
interface{}转string 1 2 3 func Interface2String (value interface {}) string { return fmt.Sprint(value) }
或者
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 import ( "fmt" "strconv" ) func Interface2String (value interface {}) string { var key string if value == nil { return key } switch value.(type ) { case float64 : ft := value.(float64 ) key = strconv.FormatFloat(ft, 'f' , -1 , 64 ) case float32 : ft := value.(float32 ) key = strconv.FormatFloat(float64 (ft), 'f' , -1 , 64 ) case int : it := value.(int ) key = strconv.Itoa(it) case uint : it := value.(uint ) key = strconv.Itoa(int (it)) case int8 : it := value.(int8 ) key = strconv.Itoa(int (it)) case uint8 : it := value.(uint8 ) key = strconv.Itoa(int (it)) case int16 : it := value.(int16 ) key = strconv.Itoa(int (it)) case uint16 : it := value.(uint16 ) key = strconv.Itoa(int (it)) case int32 : it := value.(int32 ) key = strconv.Itoa(int (it)) case uint32 : it := value.(uint32 ) key = strconv.Itoa(int (it)) case int64 : it := value.(int64 ) key = strconv.FormatInt(it, 10 ) case uint64 : it := value.(uint64 ) key = strconv.FormatUint(it, 10 ) case string : key = value.(string ) case []byte : key = string (value.([]byte )) default : newValue, _ := json.Marshal(value) key = string (newValue) } return key }
string、int、float类型相互转换 string转成int:
1 int , err := strconv.Atoi(string )
string转成int64:
1 2 3 4 int64 , err := strconv.ParseInt(string , 10 , 64 )
string转成float64、float32
1 2 3 4 5 6 7 8 9 10 11 float64 ,err := strconv.ParseFloat(str,64 )float32 ,err := strconv.ParseFloat(str,32 )
int、int64、uint64转其他
1 2 3 string := strconv.Itoa(int )string := strconv.FormatInt(int64 (int ), 10 )
int64转成string:
1 string := strconv.FormatInt(int64 ,10 )
uint64转成string:
1 string := strconv.FormatUint(uint64 ,10 )
int转float32
float转其他
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 str1 = strconv.FormatFloat(11.34 ,'E' ,-1 ,32 ) str2 = strconv.FormatFloat(10.55 ,'E' ,-1 ,64 ) fmt.Println(str1,str2) h,_ :=strconv.ParseFloat(str1,32 ) fmt.Println(h) h,_ =strconv.ParseFloat(str2,64 ) fmt.Println(h)
float转int64(会有精度损失)
1 2 var x float64 = 6.9 y := int64 (x)
打印 对象 1 parasStr := fmt.Sprintf("%+v" , paras)
Print 和 Printf Print是打印输出到控制台
Printf是格式化字符串后打印输出到控制台
1 2 3 4 5 fmt.Print("a" , "\n" ) fmt.Println("a" ) fmt.Println("a" ,"b" ) fmt.Printf("conf: %p \n" , conf)
Print 和 Sprint 功能不同
Print 将输入参数转换为 string 后, 写入标准输出。也就是程序运行时,我们可以在运行界面看到转换后的 string。
Sprint 仅完成将输入参数转换为String,不会写入标准输出。
函数返回值不同
Print 的返回值有两个,分别表示写入标准输出的字节数以及写入时是否有错误发生:
func Print(a ...interface{}) (n int, err error)
Sprint 返回转换后的字符串:func Sprint(a ...interface{}) string
示例
1 2 3 4 5 6 fmt.Print("a" , "\n" ) title1 := fmt.Sprint("已采集2个药草," , "还需要8个完成任务" ) title2 := fmt.Sprintf("已采集%d个药草,还需要%d个完成任务" , 2 , 8 ) fmt.Println("title1:" , title1) fmt.Println("title2:" , title2)
Print和Println输出字符串 Print输出给定的字符串,如果是数值或字符,则输出对应的十进制表示
Println自动在结尾输出\n,两个数值之间自动加空格,每项之间自动加空格
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 fmt.Print("a" , "\n" ) fmt.Print("a" , "b" , "\n" ) fmt.Print('a' , "\n" ) fmt.Print('a' , 'b' , "\n" ) fmt.Print(12 , "\n" ) fmt.Print(12 , 13 , "\n" ) fmt.Println("---------------------------------" ) fmt.Println("a" ) fmt.Println("a" , "b" ) fmt.Println('a' ) fmt.Println('a' , 'b' ) fmt.Println(12 ) fmt.Println(12 , 13 ) fmt.Println("\n" , 12 , 13 )
Printf格式化输出 1 2 fmt.Printf("conf: %p \n" , conf)
普通占位符
占位符
说明
举例
输出
%v
相应值的默认格式fmt.Printf("%v", name){春生}
%+v
打印结构体时,会添加字段名fmt.Printf("%+v", people)main.Human{Name:"zhangsan"}
%#v
相应值的Go语法表示fmt.Printf("%#v",people)main.Human{Name:”春生”}
%T
相应值的类型的Go语法表示fmt.Printf("%T",people)main.Human
%%
字面上的百分号fmt.Printf("%%")%
布尔占位符
占位符
说明
举例
输出
%t
true 或 false。fmt.Printf("%t",true)true
整数占位符
占位符
说明
举例
输出
%b
二进制表示fmt.Printf("%b", 5)101
%c
相应Unicode码点所表示的字符fmt.Printf("%c", 0x4E2D)中
%d
十进制表示fmt.Printf("%d", 0x12)18
%o
八进制表示fmt.Printf("%d", 10)12
%q
单引号围绕的字符字面值,由Go语法安全地转义fmt.Printf("%q", 0x4E2D)‘中’
%x
十六进制表示,字母形式为小写 a-f
fmt.Printf("%x", 13)d
%X
十六进制表示,字母形式为大写 A-F
fmt.Printf("%x", 13)D
%U
Unicode格式:U+1234,等同于 “U+%04X”
fmt.Printf("%U", 0x4E2D)U+4E2D
浮点数
占位符
说明
举例
%e
(=%.6e) 6位小数点 科学计数法,例如 -1234.456e+78
fmt.Printf(“%e”, 10.2)
%E
科学计数法,例如 -1234.456E+78
fmt.Printf(“%e”, 10.2)
%f
(=%.6f) 6位小数点 有小数点而无指数,例如 123.456
fmt.Printf(“%f”, 10.2)
%g
根据情况选择 %e 或 %f 以产生更紧凑的(无末尾的0)输出
fmt.Printf(“%g”, 10.20)
%G
根据情况选择 %E 或 %f 以产生更紧凑的(无末尾的0)输出
fmt.Printf(“%G”, 10.20+2i)
字符串与字节切片
占位符
说明
举例
%s
输出字符串(string类型或[]byte)
fmt.Printf(“%s”, []byte(“oldboy”))
%10s
输出字符串最小宽度为10(右对齐)
fmt.Printf(“%10s”, “oldboy”)
%-10s
输出字符串最小宽度为10(左对齐)
fmt.Printf(“%-10s”, “oldboy”)
%.5s
输出字符串最大宽度为5
fmt.Printf(“%.5s”, “oldboy”)
%5.10s
输出字符串最小宽度为5,最大宽度为10
fmt.Printf(“%5.10s”, “oldboy”)
%-5.10s
输出字符串最小宽度为5,最大宽度为10(左对齐)
fmt.Printf(“%-5.10s”, “oldboy”)
%5.3s
输出字符串宽度为5,如果原字符串宽度大于3,则截断
fmt.Printf(“%5.3s”, “oldboy”)
%010s
如果宽度小于10,就会在字符串前面补零
fmt.Printf(“%010s”, “oldboy”)
%q
双引号围绕的字符串,由Go语法安全地转义
fmt.Printf(“%q”, “oldboy”)
%x
十六进制,小写字母,每字节两个字符
fmt.Printf(“%x”, “oldboy”)
%X
十六进制,大写字母,每字节两个字符
fmt.Printf(“%X”, “oldboy”)
指针
占位符
说明
举例
%p
十六进制表示,前缀 0x
fmt.Printf(“%p”, &site)
%#p
不带前缀 0x
fmt.Printf(“%#p”, &site)