JS输入验证
正则
范围匹配
匹配内容
| 字符 | 描述 |
|---|---|
[ABC] |
匹配 ABC 中的字符 |
[^ABC] |
匹配除了 ABC 中的字符 |
[A-Z] |
[A-Z] 表示一个区间,匹配所有大写字母,[a-z] 表示所有小写字母。 |
. |
匹配除换行符(\n、\r)之外的任何单个字符,相等于 [^\n\r]。 |
[\s\S] |
匹配所有。\s 是匹配所有空白符,包括换行,\S 非空白符,不包括换行。 |
\w |
匹配字母、数字、下划线。等价于 [A-Za-z0-9_] |
\s |
匹配任何空白字符,包括空格、制表符、换行符等。等价于 [ \t\n\r\f\v] |
\S |
匹配任何非空白字符。等价于 [^ \t\n\r\f\v] |
[\u4e00-\u9fa5]{0,} |
匹配汉字 |
\d,\w,\s |
匹配数字、字符、空格。 |
\D,\W,\S |
匹配非数字、非字符、非空格。 |
\b |
匹配单词的开始或结束。 |
匹配次数
| 字符 | 描述 | 示例 |
|---|---|---|
+ |
+ 号代表前面的字符必须至少出现一次(1次或多次) |
runoo+b,可以匹配 runoob、runooob、runoooooob 等 |
* |
* 号代表前面的字符可以不出现,也可以出现一次或者多次(0次、或1次、或多次) |
runoo\*b,可以匹配 runob、runoob、runoooooob 等 |
? |
? 问号代表前面的字符最多只可以出现一次(0次或1次) |
colou?r 可以匹配 color 或者 colour |
特殊字符
| 特别字符 | 描述 |
|---|---|
$ |
匹配输入字符串的结尾位置。如果设置了 RegExp 对象的 Multiline 属性,则 $ 也匹配 \n 或 \r。要匹配 $ 字符本身,请使用 \$。 |
() |
标记一个子表达式的开始和结束位置。子表达式可以获取供以后使用。要匹配这些字符,请使用 \( 和 \)。 |
* |
匹配前面的子表达式零次或多次。要匹配 * 字符,请使用 \*。 |
+ |
匹配前面的子表达式一次或多次。要匹配 + 字符,请使用 \+。 |
. |
匹配除换行符 \n 之外的任何单字符。要匹配 . ,请使用 \. 。 |
[] |
标记一个中括号表达式的开始。要匹配 [,请使用 \[。 |
? |
匹配前面的子表达式零次或一次,或指明一个非贪婪限定符。要匹配 ? 字符,请使用 \?。 |
\ |
将下一个字符标记为或特殊字符、或原义字符、或向后引用、或八进制转义符。例如, ‘n’ 匹配字符 ‘n’。\n 匹配换行符。序列 \\ 匹配 \,而 \( 则匹配 (。 |
^ |
放在表达式的开头代表以什么开始。[]内的开始,代表取非。[]内的非开始的位置,代表^字符和\^同理。 |
{ |
标记限定符表达式的开始。要匹配 {,请使用 \{。 |
| |
指明两项之间的一个选择。要匹配 ` |
限定符
限定符用来指定正则表达式的一个给定组件必须要出现多少次才能满足匹配。有 * 或 + 或 ? 或 {n} 或 {n,} 或 {n,m} 共6种。
正则表达式的限定符有:
| 字符 | 描述 |
|---|---|
| * | 匹配前面的子表达式零次或多次。例如,zo* 能匹配 "z" 以及 "zoo"。* 等价于 {0,}。 |
| + | 匹配前面的子表达式一次或多次。例如,zo+ 能匹配 "zo" 以及 “zoo",但不能匹配 "z"。+ 等价于 {1,}。 |
| ? | 匹配前面的子表达式零次或一次。例如,do(es)? 可以匹配 "do" 、 "does"、 "doxy" 中的 "do" 。? 等价于 {0,1}。 |
| {n} | n 是一个非负整数。匹配确定的 n 次。例如,o{2} 不能匹配 "Bob" 中的 o,但是能匹配 "food" 中的两个 o。 |
| {n,} | n 是一个非负整数。至少匹配n 次。例如,o{2,} 不能匹配 "Bob" 中的 o,但能匹配 "foooood" 中的所有 o。o{1,} 等价于 o+。o{0,} 则等价于 o*。 |
| {n,m} | m 和 n 均为非负整数,其中 n <= m。最少匹配 n 次且最多匹配 m 次。例如,o{1,3} 将匹配 "fooooood" 中的前三个 o。o{0,1} 等价于 o?。请注意在逗号和两个数之间不能有空格。 |
贪婪和非贪婪
*和 + 限定符都是贪婪的,因为它们会尽可能多的匹配文字,只有在它们的后面加上一个 ? 就可以实现非贪婪或最小匹配。
例如,您可能搜索 HTML 文档,以查找在 h1 标签内的内容。HTML 代码如下:
1 | <h1>RUNOOB-菜鸟教程</h1> |
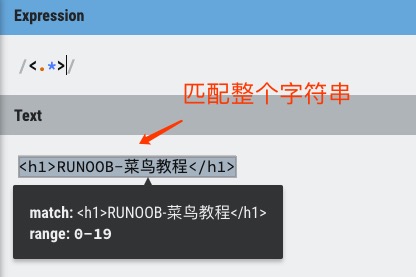
贪婪:下面的表达式匹配从开始小于符号 (<) 到关闭 h1 标记的大于符号 (>) 之间的所有内容。
1 | /<.*>/ |
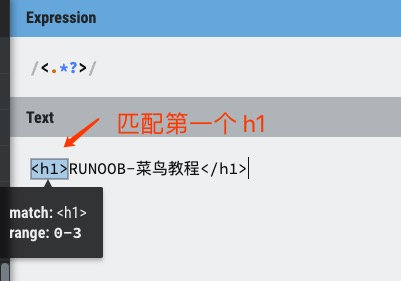
非贪婪:如果您只需要匹配开始和结束 h1 标签,下面的非贪婪表达式只匹配 <h1>。
1 | /<.*?>/ |
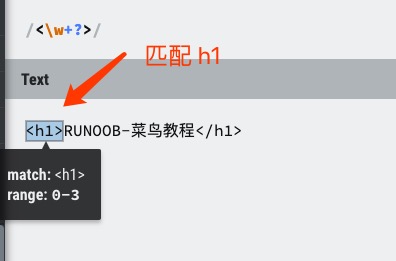
也可以使用以下正则表达式来匹配 h1 标签,表达式则是:
1 | /<\w+?>/ |
通过在 *、+ 或 ? 限定符之后放置 ?,该表达式从”贪婪”表达式转换为”非贪婪”表达式或者最小匹配。
选择
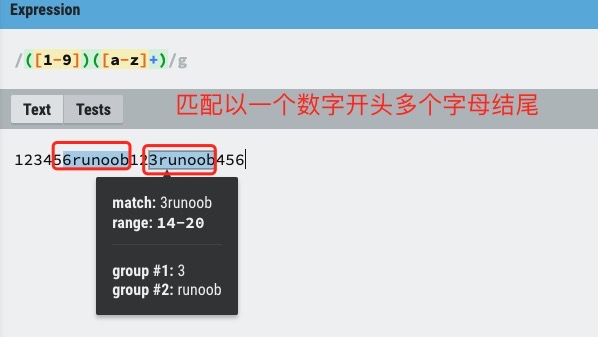
用圆括号 () 将所有选择项括起来,相邻的选择项之间用 | 分隔。
() 表示捕获分组,() 会把每个分组里的匹配的值保存起来, 多个匹配值可以通过数字 n 来查看(n 是一个数字,表示第 n 个捕获组的内容)。

但用圆括号会有一个副作用,使相关的匹配会被缓存,此时可用 ?: 放在第一个选项前来消除这种副作用。
其中 ?: 是非捕获元之一,还有两个非捕获元是 ?= 和 ?!,这两个还有更多的含义,前者为正向预查,在任何开始匹配圆括号内的正则表达式模式的位置来匹配搜索字符串,后者为负向预查,在任何开始不匹配该正则表达式模式的位置来匹配搜索字符串。
?=、?<=、?!、?<! 的区别
exp1(?=exp2):查找 exp2 前面的 exp1。
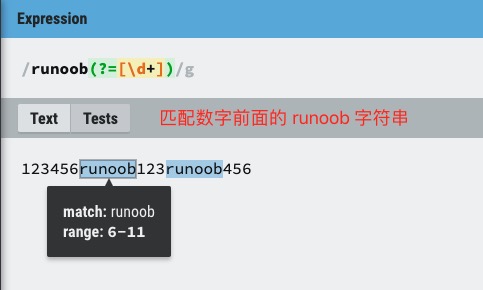
(?<=exp2)exp1:查找 exp2 后面的 exp1。
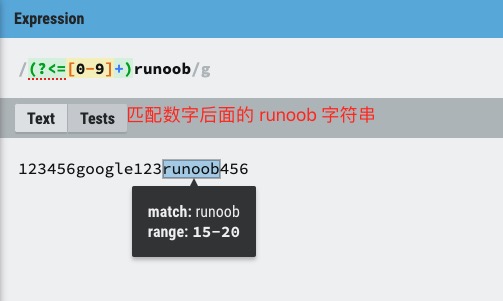
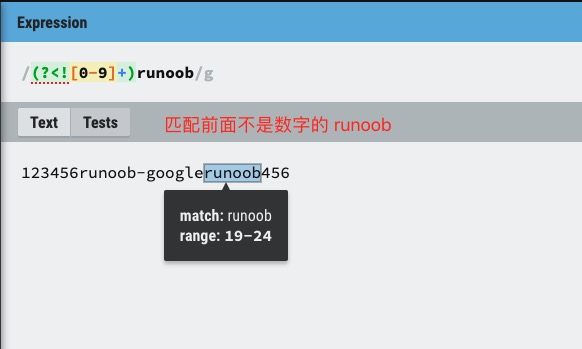
exp1(?!exp2):查找后面不是 exp2 的 exp1。

(?<!exp2)exp1:查找前面不是 exp2 的 exp1。
匹配的结果
1 | var str = "https://www.psvmc.cn:443/ztools/z/json_format/index.html"; |
结果
https://www.psvmc.cn:443/ztools/z/json_format/index.html
https
www.psvmc.cn
443
/ztools/z/json_format/index.html
修饰符
标记也称为修饰符,正则表达式的标记用于指定额外的匹配策略。
标记不写在正则表达式里,标记位于表达式之外,格式如下:
1 | /pattern/flags |
下表列出了正则表达式常用的修饰符:
| 修饰符 | 含义 | 描述 |
|---|---|---|
| i | ignore - 不区分大小写 | 将匹配设置为不区分大小写,搜索时不区分大小写: A 和 a 没有区别。 |
| g | global - 全局匹配 | 查找所有的匹配项。 |
| m | multi line - 多行匹配 | 使边界字符 ^ 和 $ 匹配每一行的开头和结尾,记住是多行,而不是整个字符串的开头和结尾。 |
| s | 特殊字符圆点 . 中包含换行符 \n |
默认情况下的圆点 . 是匹配除换行符 \n 之外的任何字符,加上 s 修饰符之后, . 中包含换行符 \n。 |
运算符优先级
正则表达式从左到右进行计算,并遵循优先级顺序,这与算术表达式非常类似。
相同优先级的从左到右进行运算,不同优先级的运算先高后低。下表从最高到最低说明了各种正则表达式运算符的优先级顺序:
| 运算符 | 描述 |
|---|---|
\ |
转义符 |
(), (?:), (?=), [] |
圆括号和方括号 |
*, +, ?, {n}, {n,}, {n,m} |
限定符 |
^, $, \任何元字符、任何字符 |
定位点和序列(即:位置和顺序) |
| ` | ` |
常用正则表达式
校验数字的表达式
- 数字:
^[0-9]\*$ - n位的数字:
^\d{n}$ - 至少n位的数字
:^\d{n,}$ - m-n位的数字:
^\d{m,n}$ - 零和非零开头的数字:
^(0|[1-9][0-9]\*)$ - 非零开头的最多带两位小数的数字:
^([1-9][0-9]\*)+(\.[0-9]{1,2})?$ - 带1-2位小数的正数或负数:
^(\-)?\d+(\.\d{1,2})$ - 正数、负数、和小数:
^(\-|\+)?\d+(\.\d+)?$ - 有两位小数的正实数:
^[0-9]+(\.[0-9]{2})?$ - 有1~3位小数的正实数:
^[0-9]+(\.[0-9]{1,3})?$ - 非零的正整数:
^[1-9]\d\*$ 或 ^([1-9][0-9]\*){1,3}$ 或 ^\+?[1-9][0-9]\*$ - 非零的负整数:
^\-[1-9][]0-9"\*$ 或 ^-[1-9]\d\*$ - 非负整数:
^\d+$ 或 ^[1-9]\d\*|0$ - 非正整数:
^-[1-9]\d\*|0$ 或 ^((-\d+)|(0+))$ - 非负浮点数:
^\d+(\.\d+)?$ 或 ^[1-9]\d\*\.\d\*|0\.\d\*[1-9]\d\*|0?\.0+|0$ - 非正浮点数:
^((-\d+(\.\d+)?)|(0+(\.0+)?))$ 或 ^(-([1-9]\d\*\.\d\*|0\.\d\*[1-9]\d\*))|0?\.0+|0$ - 正浮点数:
^[1-9]\d\*\.\d\*|0\.\d\*[1-9]\d\*$ 或 ^(([0-9]+\.[0-9]\*[1-9][0-9]\*)|([0-9]\*[1-9][0-9]\*\.[0-9]+)|([0-9]\*[1-9][0-9]\*))$ - 负浮点数:
^-([1-9]\d\*\.\d\*|0\.\d\*[1-9]\d\*)$ 或 ^(-(([0-9]+\.[0-9]\*[1-9][0-9]\*)|([0-9]\*[1-9][0-9]\*\.[0-9]+)|([0-9]\*[1-9][0-9]\*)))$ - 浮点数:
^(-?\d+)(\.\d+)?$ 或 ^-?([1-9]\d\*\.\d\*|0\.\d\*[1-9]\d\*|0?\.0+|0)$
校验字符的表达式
- 汉字:
^[\u4e00-\u9fa5]{0,}$ - 英文和数字:
^[A-Za-z0-9]+$ 或 ^[A-Za-z0-9]{4,40}$ - 长度为3-20的所有字符:
^.{3,20}$ - 由26个英文字母组成的字符串:
^[A-Za-z]+$ - 由26个大写英文字母组成的字符串:
^[A-Z]+$ - 由26个小写英文字母组成的字符串:
^[a-z]+$ - 由数字和26个英文字母组成的字符串:
^[A-Za-z0-9]+$ - 由数字、26个英文字母或者下划线组成的字符串:
^\w+$ 或 ^\w{3,20}$ - 中文、英文、数字包括下划线:
^[\u4E00-\u9FA5A-Za-z0-9_]+$ - 中文、英文、数字但不包括下划线等符号:
^[\u4E00-\u9FA5A-Za-z0-9]+$ 或 ^[\u4E00-\u9FA5A-Za-z0-9]{2,20}$ - 可以输入含有^%&’,;=?$"等字符:
[^%&',;=?$\x22]+ - 禁止输入含有
的字符:`[^]+`
特殊需求表达式
- Email地址:
^\w+([-+.]\w+)\*@\w+([-.]\w+)\*\.\w+([-.]\w+)\*$ - 域名:
[a-zA-Z0-9][-a-zA-Z0-9]{0,62}(\.[a-zA-Z0-9][-a-zA-Z0-9]{0,62})+\.? - InternetURL:
[a-zA-z]+://[^\s]\* 或 ^http://([\w-]+\.)+[\w-]+(/[\w-./?%&=]\*)?$ - 手机号码:
^(13[0-9]|14[01456879]|15[0-35-9]|16[2567]|17[0-8]|18[0-9]|19[0-35-9])\d{8}$ - 电话号码(“XXX-XXXXXXX”、”XXXX-XXXXXXXX”、”XXX-XXXXXXX”、”XXX-XXXXXXXX”、”XXXXXXX”和”XXXXXXXX):
^(\(\d{3,4}-)|\d{3.4}-)?\d{7,8}$ - 国内电话号码(0511-4405222、021-87888822):
\d{3}-\d{8}|\d{4}-\d{7} - 电话号码正则表达式(支持手机号码,3-4位区号,7-8位直播号码,1-4位分机号):
((\d{11})|^((\d{7,8})|(\d{4}|\d{3})-(\d{7,8})|(\d{4}|\d{3})-(\d{7,8})-(\d{4}|\d{3}|\d{2}|\d{1})|(\d{7,8})-(\d{4}|\d{3}|\d{2}|\d{1}))$) - 身份证号(15位、18位数字),最后一位是校验位,可能为数字或字符X:
(^\d{15}$)|(^\d{18}$)|(^\d{17}(\d|X|x)$) - 帐号是否合法(字母开头,允许5-16字节,允许字母数字下划线):
^[a-zA-Z][a-zA-Z0-9_]{4,15}$ - 密码(以字母开头,长度在6~18之间,只能包含字母、数字和下划线):
^[a-zA-Z]\w{5,17}$ - 强密码(必须包含大小写字母和数字的组合,不能使用特殊字符,长度在 8-10 之间):
^(?=.\*\d)(?=.\*[a-z])(?=.\*[A-Z])[a-zA-Z0-9]{8,10}$ - 强密码(必须包含大小写字母和数字的组合,可以使用特殊字符,长度在8-10之间):
^(?=.\*\d)(?=.\*[a-z])(?=.\*[A-Z]).{8,10}$ - 日期格式:
^\d{4}-\d{1,2}-\d{1,2} - 一年的12个月(01~09和1~12):
^(0?[1-9]|1[0-2])$ - 一个月的31天(01~09和1~31):
^((0?[1-9])|((1|2)[0-9])|30|31)$ - 钱的输入格式:
- 有四种钱的表示形式我们可以接受:”10000.00” 和 “10,000.00”, 和没有 “分” 的 “10000” 和 “10,000”:
^[1-9][0-9]\*$ - 这表示任意一个不以0开头的数字,但是,这也意味着一个字符”0”不通过,所以我们采用下面的形式:
^(0|[1-9][0-9]\*)$ - 一个0或者一个不以0开头的数字.我们还可以允许开头有一个负号:
^(0|-?[1-9][0-9]\*)$ - 这表示一个0或者一个可能为负的开头不为0的数字.让用户以0开头好了.把负号的也去掉,因为钱总不能是负的吧。下面我们要加的是说明可能的小数部分:
^[0-9]+(.[0-9]+)?$ - 必须说明的是,小数点后面至少应该有1位数,所以”10.”是不通过的,但是 “10” 和 “10.2” 是通过的:
^[0-9]+(.[0-9]{2})?$ - 这样我们规定小数点后面必须有两位,如果你认为太苛刻了,可以这样:
^[0-9]+(.[0-9]{1,2})?$ - 这样就允许用户只写一位小数.下面我们该考虑数字中的逗号了,我们可以这样:
^[0-9]{1,3}(,[0-9]{3})\*(.[0-9]{1,2})?$ - 1到3个数字,后面跟着任意个 逗号+3个数字,逗号成为可选,而不是必须:
^([0-9]+|[0-9]{1,3}(,[0-9]{3})\*)(.[0-9]{1,2})?$ - 备注:这就是最终结果了,别忘了”+”可以用”*”替代如果你觉得空字符串也可以接受的话(奇怪,为什么?)最后,别忘了在用函数时去掉去掉那个反斜杠,一般的错误都在这里
- 有四种钱的表示形式我们可以接受:”10000.00” 和 “10,000.00”, 和没有 “分” 的 “10000” 和 “10,000”:
- xml文件:
^([a-zA-Z]+-?)+[a-zA-Z0-9]+\\.[x|X][m|M][l|L]$ - 中文字符的正则表达式:
[\u4e00-\u9fa5] - 双字节字符:
[^\x00-\xff] (包括汉字在内,可以用来计算字符串的长度(一个双字节字符长度计2,ASCII字符计1)) - 空白行的正则表达式:
\n\s\*\r (可以用来删除空白行) - HTML标记的正则表达式:
<(\S\*?)[^>]\*>.\*?|<.\*? /> ( 首尾空白字符的正则表达式:^\s\*|\s\*$或(^\s\*)|(\s\*$) (可以用来删除行首行尾的空白字符(包括空格、制表符、换页符等等),非常有用的表达式) - 腾讯QQ号:
[1-9][0-9]{4,} (腾讯QQ号从10000开始) - 中国邮政编码:
[1-9]\d{5}(?!\d) (中国邮政编码为6位数字) - IPv4地址:
((2(5[0-5]|[0-4]\d))|[0-1]?\d{1,2})(\.((2(5[0-5]|[0-4]\d))|[0-1]?\d{1,2})){3}
只能输入手机号
先替换非数字
1 | <input type="text" name="userPhone" placeholder="请输入手机号" class="" onkeyup="value=value.replace(/[^\d]/g,'')"/> |
禁止点击数字意外的操作
1 | $("input[name=userPhone]").keydown(function(event){ |
验证手机号
1 | var pattern = new RegExp("^1[0-9]{10}$", "i"); |
去除空格
1 | var mystr= ' https://www.psvmc.cn/ '; |
剔除
1 | "escaping ".replace(/( )*$/g, ""); |
找到匹配项
方式1
这种方式只能获取匹配的项。
1 | let source_text = "我的城市在中国-河南-郑州;你的城市在中国-四川-成都"; |
方式2
这种方式可以获取到匹配的项及其索引。
1 | let source_text = "我的城市在中国-河南-郑州;你的城市在中国-四川-成都"; |
其中下面的代码是防止匹配的时候死循环:
1 | if (endIndex < startIndex) { |
匹配的语法高亮
1 | let source_text = "我的城市在中国-河南-郑州;你的城市在中国-四川-成都"; |