大数据-数据中台搭建技术选型
前言
技术选型
- 分布式存储 Hadoop(HDFS)
- 分布式数仓 Hive
- 分布式数据库 Hbase
- 分布式计算 Flink
- 分布式消息队列 Kafka
- 批数据同步 DataX
- 实时Mysql Canal 其他的数据库后续支持。
- 作业调度 crontab 先实现简单的定时任务,之后再考虑任务流处理。
- 数据湖 暂不考虑。
数据处理流程及分层
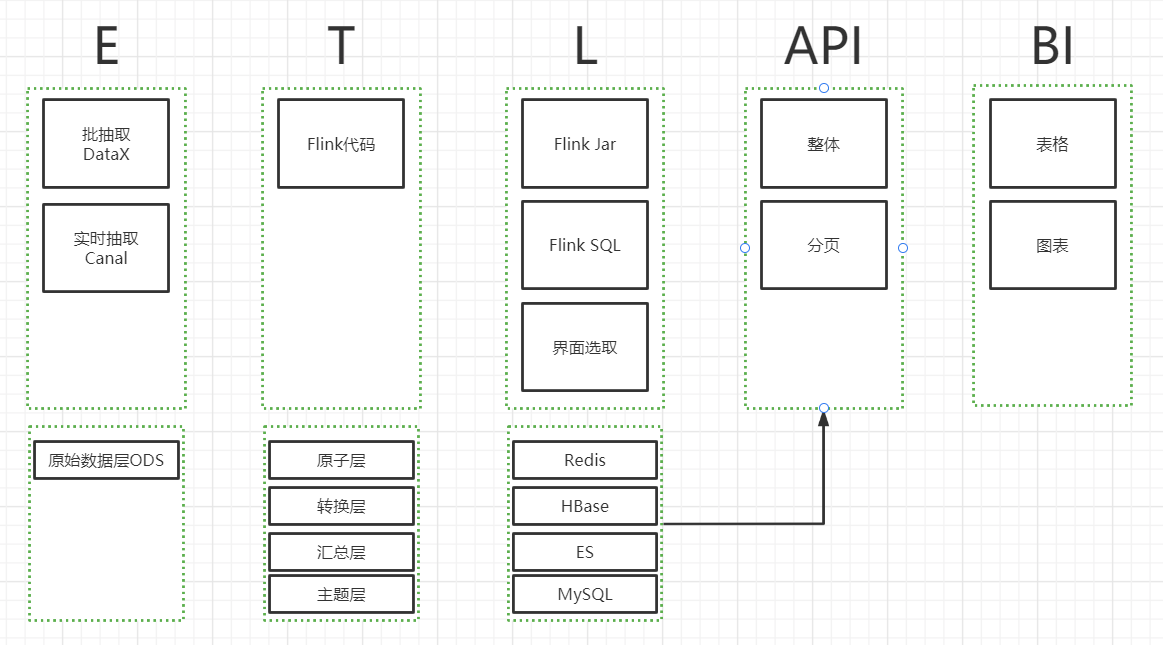
其中数据分层
- 原始数据层 其他源的原始数据不进行处理
- 原子层 数据附加来源标签
- 转换层 数据字段转换为统一的形式
- 汇总层 把不同来源的相同数据进行按策略汇总
- 主题层 把数据分为不同的主题
API接口
对外提供API接口采取如下方式
- Redis
- Redis+Hbase
数据转换
- 截取
- 对应转换 例如:男=>1 女=>2
- 日期字符串 => 时间戳
- 数据类型转换 如 字符串转数字 数字转字符串
推荐项目
DataX ETL项目
https://gitee.com/psvmc/datax-web
对比
Taier
文档:https://dtstack.github.io/Taier/docs/guides/introduction/
视频:https://www.bilibili.com/video/BV13L4y1L71w/
源码:https://github.com/DTStack/Taier
推荐资源
数据中台是什么?
https://www.bilibili.com/video/BV1e3411W7f1?vd_source=e0fcc7abaacc3af8b556e0441cd6d47a
DataX Java集成
https://developer.aliyun.com/article/642896
自己实现DataX
https://www.bilibili.com/video/BV1MP4y1F7qE?vd_source=e0fcc7abaacc3af8b556e0441cd6d47a
【网易大数据专家,为你剖析数据中台的现状及未来】
https://www.bilibili.com/video/BV1EQ4y1M7fW?vd_source=e0fcc7abaacc3af8b556e0441cd6d47a
Spark
UDF:User Defined Function,用户自定义函数。