前言
Rust 是一种系统级编程语言,它的设计目标是提供高性能、安全性和并发性。Rust 的主要优势包括:
- 高性能:Rust 的编译器使用 LLVM 作为后端,能够生成高效的机器代码。同时,Rust 的内存管理机制可以避免内存泄漏和不安全的指针操作,进一步提高了程序的性能。
- 内存安全:Rust 的内存安全机制通过所有权和借用规则,避免了内存泄漏、野指针和缓冲区溢出等常见的安全问题。这使得 Rust 适用于编写高性能和安全性要求较高的系统级程序。
- 并发性:Rust 的所有权和借用规则,以及线程安全的数据类型,可以帮助开发者编写安全和高效的并发程序。
- 生态系统:Rust 拥有一个活跃的社区和丰富的包管理器 Cargo,开发者可以方便地使用已有的 Rust crate 来构建项目,也可以发布自己的 crate 给其他开发者使用。
- 可移植性:Rust 的编译器支持多种操作系统和 CPU 架构,可以在各种环境下编译和运行。
总之,Rust 是一种高性能、安全和并发的系统级编程语言,它的设计理念和特性使得它成为开发高性能、安全和可靠系统的优秀选择。
Rust安装
最后,请前往 https://www.rust-lang.org/zh-CN/tools/install 来安装 rustup (Rust 安装程序)。
请注意,为了使更改生效,您必须重新启动终端,在某些情况下需要重新启动 Windows 本身。
或者,您可以在 PowerShell 中使用 winget 命令安装程序:
1 | winget install --id Rustlang.Rustup |
查看版本
1 | rustc --version |
镜像
rustup设置国内镜像
RUSTUP_DIST_SERVER (用于更新 toolchain):
1 | export RUSTUP_DIST_SERVER="https://rsproxy.cn" |
RUSTUP_UPDATE_ROOT (用于更新 rustup):
1 | export RUSTUP_UPDATE_ROOT="https://rsproxy.cn/rustup" |
cargo设置国内镜像
crates.io index失败
解决方法
使用Rust crates.io 索引镜像
编辑 ~/.cargo/config 文件,添加以下内容:
Windows下路径类似于
1 | C:\Users\Administrator\.cargo\config |
config文件默认没有新建即可。
1 | [source.crates-io] |
该镜像可加快 cargo 读取软件包索引的速度。
另一个镜像
1 | [source.crates-io] |
开发工具
VSCode中安装插件rust-analyzer
IDEA中直接添加rust即可
包管理器
Rust 的包管理器叫做 Cargo,它是 Rust 官方提供的工具,用于构建、测试和管理 Rust 项目的依赖关系。
Cargo不用另外安装,Rust内就包含。
Cargo 有以下几个主要的功能:
- 管理 Rust 项目的依赖关系,可以自动下载、编译和安装依赖项。
- 提供命令行工具来构建、运行和测试 Rust 项目。
- 管理项目的版本号和发布。
下面是一些常用的 Cargo 命令:
cargo new <project-name>:创建一个新的 Rust 项目。cargo build:编译项目,并生成可执行文件或库。cargo run:编译并运行项目。cargo test:运行项目的测试用例。cargo doc:生成项目的文档。cargo clean:清理项目的编译输出。
如果已存在文件夹,可以进入文件夹内运行
1 | cargo init |
运行
1 | cargo run |
除了管理项目本身的依赖关系,Cargo 还可以管理系统级别的 Rust 依赖库,例如 Rust 标准库和其他常用的 Rust crate。
在使用 Cargo 管理 Rust 项目时,通常需要编辑项目根目录下的 Cargo.toml 文件,这个文件包含了项目的依赖关系和其他一些配置信息。
总之,Cargo 是 Rust 生态系统中非常重要的一个组成部分,它的出现使得 Rust 项目的管理和构建变得更加简单和高效。
语法
打印
main.rs
1 | fn main() { |
变量和数据类型
Rust中的变量名必须以字母或下划线开头,并且可以包含字母、数字和下划线。变量必须先声明后使用。
Rust有以下基本数据类型:整型、浮点型、布尔型、字符型、元组和数组。
其中元组是不同类型值的集合,数组是相同类型值的集合。
声明变量
声明变量时需要使用 let 关键字,可以使用类型推断自动推断变量的类型:
1 | fn main() { |
字符串
字符串拼接
1 | fn main() { |
元组
元组是 Rust 中的一种复合类型,可以将多个不同类型的值组合在一起。元组的语法使用圆括号 (),元素之间使用逗号 , 分隔。元组的类型取决于其中元素的类型和数量。
下面是一个示例程序,演示了元组的用法:
1 | fn main() { |
这个程序定义了一个包含一个字符串和一个整数的元组 t1,并将其输出到控制台。然后程序使用元组解构语法,分别将元组中的字符串和整数赋值给变量 s1 和 n1,并将它们输出到控制台。接着程序通过下标访问元组中的元素,并将它们输出到控制台。最后,程序使用元组解构语法交换了变量 x 和 y 的值。
数组
在 Rust 中,数组的长度是固定的,一旦定义了数组,其长度就无法更改。
Rust 提供了一个类似于数组的数据结构,称为 Vec,它可以动态调整大小。Vec 内部使用堆来存储数据,因此它可以在运行时动态增加或减少其容量。与数组不同,Vec 的长度可以根据需要增加或减少,因此在需要动态大小的情况下,使用 Vec 更为常见。
如果你需要在 Rust 中使用动态大小的数据结构,可以考虑使用 Vec。如果你需要在编译时确定大小并且不需要动态调整大小,则可以使用数组。
下面是一个 Rust 数组的示例:
1 | fn main() { |
输出:
1 | 第一个元素是: 1 |
在上面的示例中,我们创建了一个包含5个整数元素的数组。然后我们访问了数组中的元素,并使用 for 循环遍历了数组中的每个元素。请注意,在 Rust 中,数组的索引从0开始,而不是从1开始。
Vec
下面是一个 Rust Vec 的示例:
1 | fn main() { |
输出:
1 | 第一个元素是: 1 |
在上面的示例中,我们创建了一个空的 Vec<i32>,然后在其中添加了5个整数元素。我们访问了 Vec 中的元素,并使用 for 循环遍历了 Vec 中的每个元素。
请注意,在这个示例中我们使用了 mut 来声明 Vec 是可变的,因为我们要向其中添加元素。此外,在访问 Vec 中的元素时,我们使用了 [] 运算符来索引 Vec。
Map
是的,Rust语言中提供了一种名为HashMap的Map实现,它允许开发人员使用键值对存储和检索数据。HashMap是Rust的标准库中的一部分,因此您无需安装任何其他库即可使用它。
要使用HashMap,您需要在Rust文件的顶部添加以下行来导入它:
1 | use std::collections::HashMap; |
然后,您可以使用HashMap来创建一个新的映射,添加键值对,查找值等。以下是一些示例代码:
1 | use std::collections::HashMap; |
请注意,在Rust中,HashMap是通过哈希表实现的,因此您可以期望在平均情况下O(1)时间复杂度下执行插入、查找和删除操作。
函数
定义函数时需要使用 fn 关键字:
1 | fn add(x: i32, y: i32) -> i32 { |
其中 x 和 y 是参数,-> i32 表示返回值类型为 i32。
方法
在 Rust 中,方法(method)和函数(function)都是非常类似的。
方法是一个与特定类型关联的函数,使用 impl 块来定义。
方法的第一个参数总是 self,表示调用这个方法的类型的实例。在方法内部,我们可以使用 self 访问这个实例的成员变量和方法。
在 Rust 中,方法参数的传递方式与函数一样,既可以传值(by value),也可以传引用(by reference)。当我们需要在方法内部修改实例的状态时,通常会使用可变引用(mutable reference)传递参数,以避免所有权的转移。
下面是一个简单的例子:
1 | struct Rectangle { |
在这个例子中,area 方法获取了 self 的不可变引用(&self),而 resize 方法获取了 self 的可变引用(&mut self)。这样可以在方法内部修改 self 的值,而不会转移所有权。如果我们使用值传递参数,那么在方法内部就无法修改 self 的值了。
需要注意的是,当我们在 impl 块内部定义方法时,必须为第一个参数使用 self 或者 &self 或者 &mut self,以指明这是一个方法。否则,它就是一个普通的函数。
控制流语句
Rust 的控制流语句包括 if、loop、while、for 等。
1 | let x = 5; |
结构体和枚举
Rust 支持定义结构体和枚举类型:
1 | struct Point { |
引用和所有权
Rust 的核心特性之一是所有权,它规定每个值都有一个所有者,只有所有者才能修改或销毁这个值。
为了让其他变量也能引用这个值,可以使用引用:
1 | let mut x = 5; |
示例2
1 | fn main() { |
结果
a:11
b:11
a:22
b:11
我们可以看出
默认的赋值是赋予的值而非引用,只有引用才考虑只有一个所有者。
类?
Rust 语言中没有类(class)的概念,而是使用结构体(struct)和枚举(enum)等数据类型来构建复杂的数据结构。
Rust 的结构体(struct)可以包含字段(field)和方法(method),类似于其他面向对象语言中的类。
1 | struct Rectangle { |
Trait(接口?)
以下是一个简单的Rust Trait示例代码:
1 | trait Printable { |
在上面的示例中,我们定义了一个名为Printable的Trait,其中包含了一个print方法。然后我们定义了一个名为Point的结构体,它实现了Printable Trait,实现了Trait中的print方法。
最后在main函数中,我们创建了一个Point结构体的实例p,并调用了它的print方法。
当我们运行程序时,它将打印出点的坐标(10, 20)。
通过Trait,我们可以定义一些共同的行为,并在不同类型之间共享这些行为。这在Rust中非常有用,因为它允许我们编写可重用的代码,并在不同的类型之间实现一致的行为。
生命周期
以下是一个简单的Rust生命周期示例代码:
1 | fn longest<'a>(x: &'a str, y: &'a str) -> &'a str { |
在上面的示例中,我们定义了一个函数longest,它接受两个字符串的引用x和y,并返回其中较长的那个字符串的引用。在函数签名中,我们使用了生命周期参数'a来表明x和y参数的生命周期与返回值的生命周期是相同的。
在main函数中,我们创建了两个字符串s1和s2,其中s1是一个String类型的变量,s2是一个字符串字面量。然后我们调用longest函数,并将s1和s2的引用作为参数传递给它。最后,我们将返回值打印到控制台上。
当我们运行程序时,它将输出“ The longest string is world”,因为“world”比“hello”更长。
通过使用生命周期,我们可以在Rust中管理内存分配和释放的方式,以确保安全和正确的内存使用。在上面的示例中,我们使用生命周期'a来表明longest函数返回的引用是x和y参数的引用之一,以便编译器可以检查引用的有效性和生命周期的正确性。
错误处理
好的,下面是在Rust中处理错误的几种方式的示例代码:
使用match表达式
1 | use std::fs::File; |
在上面的示例中,我们定义了一个函数read_file_contents,它尝试打开一个文件并将其内容读取到字符串中。在main函数中,我们使用match表达式来处理read_file_contents返回的Result。如果返回的结果是Ok,则将文件内容打印到控制台上。如果返回的结果是Err,则根据错误类型进行处理,如果错误类型是NotFound,则打印“File not found.”,否则打印错误信息。
使用if let表达式
1 | use std::fs::File; |
在上面的示例中,我们使用if let表达式来处理read_file_contents返回的Result。如果返回的结果是Ok,则将文件内容打印到控制台上。否则,将错误信息打印到标准错误流上。
使用?操作符:
1 | use std::fs::File; |
在上面的示例中,我们将main函数的返回类型改为Result<(), Error>,并在函数中使用?操作符来处理read_file_contents返回的Result。
如果返回的结果是Ok,则将文件内容打印到控制台上。否则,将错误传递给调用方处理。
使用unwrap方法
1 | use std::fs::File; |
在上面的示例中,我们定义了一个函数read_file_contents,它尝试打开一个文件并将其内容读取到字符串中。
在main函数中,我们使用unwrap方法来处理read_file_contents返回的Result。如果返回的结果是Ok,则将文件内容打印到控制台上。
如果返回的结果是Err,则会触发panic,程序会终止运行。
请注意
使用unwrap方法会使程序在出现错误时崩溃,因此在实际开发中,需要根据具体情况选择合适的错误处理方式。
使用expect方法
1 | use std::fs::File; |
在上面的示例中,我们使用expect方法来处理read_file_contents返回的Result。如果返回的结果是Ok,则将文件内容打印到控制台上。如果返回的结果是Err,则会打印错误信息并触发panic,程序会终止运行。
多线程
在 Rust 中,可以使用多线程来并发地操作 Vec。
下面是一个使用 Rust 实现多线程操作 Vec 的示例代码:
1 | use std::thread; |
该示例代码创建了一个包含 9 个元素的 Vec,然后使用 Arc 和 Mutex 包装了该 Vec。接着,我们创建了 3 个线程,每个线程负责修改 Vec 的三分之一元素的值。在每个线程的执行体中,我们使用 Mutex 来获取 Vec 的写锁,并修改 Vec 中的元素。最后,我们等待所有线程完成,并输出修改后的 Vec。
需要注意的是,在使用多线程操作 Vec 时,需要注意避免数据竞争等问题。在上述示例代码中,我们使用了 Arc 和 Mutex 来保护 Vec 的访问,并确保了多个线程不会同时访问同一个元素,从而避免了数据竞争问题。同时,由于使用了 Mutex,并发性能可能会受到一定的影响,因此需要根据具体情况进行权衡和选择。
模块依赖
总结
- mod 关键字用于声明子模块。
- 我们需要明确地将函数、结构等声明为公共的,这样它们就可以被其他模块所使用。
- pub关键字使模块公开。
- use关键字用于缩短模块的路径。
内部模块
我们按照下面的结构创建依赖结构
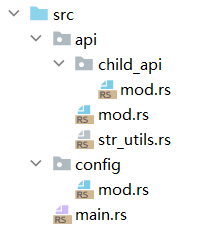
main.rs
1 | mod api; |
api/mod.rs
1 | mod str_utils; |
api/str_utils.rs
1 | pub fn zprint() { |
api/child_api/mod.rs
1 | pub fn bb_fn01() { |
config/mod.rs
1 | pub fn get_config() { |
我们可以看出
- 相邻的子模块可以直接使用
mod引用 - 如果想让外层也能访问到模块就要添加
pub a.rs和a文件夹下创建mod.rs是等效的。
use
use关键字用于缩短模块的路径
我们修改一下下面的文件
api/mod.rs
1 | mod str_utils; |
这时候main.rs就能直接调用bb_fn01方法了。
main.rs
1 | mod api; |
外部模块
添加到Cargo.toml中的依赖关系对项目中的所有模块都是可用的,我们就不需要明确地导入或声明任何东西来使用一个依赖关系。
添加依赖
1 | [dependencies] |
我们可以在我们的代码中直接使用它,例如。
1 | pub fn test() { |
我们也可以用use来缩短路径:
1 | use rand::random; |
原理与概念
内存释放机制
在 Rust 中,所有的值都有一个所有者(owner),当所有者超出作用域时,该值将被自动释放。这种方式被称为所有权(ownership)系统。
Rust 会在编译时检查所有权规则,确保在程序运行时不会出现内存错误,如空指针引用和野指针等。
当我们不再需要一个对象时,可以通过让它的所有者离开作用域来释放它。例如:
1 | fn main() { |
在上面的代码中,我们定义了一个 String 类型的对象 s,它拥有 hello 字符串的所有权。当 s 离开作用域时,Rust 会自动释放 hello 字符串的内存。
如果我们需要动态分配内存,则可以使用 Box 类型来管理内存。Box 是一个智能指针类型,它使用堆内存来存储数据,并负责释放内存。
例如:
1 | fn main() { |
在上面的代码中,我们使用 Box 类型分配内存并存储数据 5。当 x 离开作用域时,Box 类型会自动释放内存。
总之,Rust 的所有权系统保证了内存的安全和有效释放。通过在对象超出作用域时自动释放对象,Rust 避免了手动管理内存的复杂性和错误。
引用和所有权
在 Rust 中,每个值都有一个对应的所有者(owner),也就是控制这个值在内存中生命周期的变量。当这个变量离开作用域时,这个值也会被自动销毁。这样的话,就能够确保内存的安全性和避免一些常见的程序错误,比如空指针异常和数据竞争。
然而,在某些情况下,我们需要将值借用(borrow)给其他变量进行操作,而不是将所有权转移给他们。这时就需要用到 Rust 的引用(reference)机制。引用允许我们在不转移所有权的情况下,访问一个值的内部数据。
Rust 的引用有两种:可变引用(mutable reference)和不可变引用(immutable reference)。可变引用允许对值进行修改,而不可变引用则只允许读取。
为了获取一个引用,我们可以使用取引用运算符 &。比如:
1 | let x = 42; |
其中,y 是一个指向 x 的不可变引用,而 z 是一个指向 x 的可变引用。
需要注意的是,同一时间只能有一个可变引用,或者任意数量的不可变引用,但不能同时存在可变和不可变引用。这是为了避免数据竞争,保证内存安全性。
引用在函数参数传递中也很常见。
比如:
1 | fn foo(x: &i32) { |
在函数参数中传递引用时,函数不会获取所有权,而是只能使用借用的值。这样可以减少内存使用,并且避免所有权的转移。
以上是 Rust 引用的基本概念和用法。如果您还有其他问题或者需要更深入的解释,请随时提出。
str与String
在 Rust 中,str 和 String 是两种不同的字符串类型。
str 是一种不可变的字符串类型,通常作为字符串的引用来使用。str 类型的字符串通常是在代码中直接写出来的,比如 "hello"、"world" 等。
String 是一种可变的字符串类型,通常用于在运行时创建和修改字符串。我们可以使用 String::new() 方法创建一个空的 String 对象,然后使用 push_str()、push()、replace() 等方法来修改这个字符串对象的内容。通常我们会在运行时需要拼接、截取、替换等字符串操作时使用 String 类型。
需要注意的是,String 类型和 str 类型之间可以进行类型转换。我们可以使用 as_str() 方法将 String 类型转换为 &str 类型,或者使用 to_string() 方法将 &str 类型转换为 String 类型。
下面是一个示例程序,演示了 str 和 String 的用法和类型转换:
1 | fn main() { |
这个程序将输出以下内容:
1 | s1=hello, s2=world |
Vec和vec!
在Rust中,Vec是一个动态可增长的数组类型,vec则是一个Rust标准库中的宏,用于快速创建和初始化一个Vec类型的实例。
Vec类型提供了许多有用的方法,包括在数组末尾添加元素、从数组末尾删除元素、访问数组中的元素、对数组中的元素进行排序等。
vec!宏则是用于快速创建和初始化一个Vec类型的实例。
例如,下面的代码创建一个包含三个元素的Vec类型的实例:
1 | let v = vec![1, 2, 3]; |
这个代码与以下代码等价:
1 | let mut v = Vec::new(); |
使用vec!宏可以减少代码量并提高可读性。
继承
Rust语言本身没有提供类似于传统面向对象语言的继承机制,但是通过使用trait、泛型和组合等机制,可以在Rust中实现类似继承的功能。
首先,Rust中的trait可以定义一组方法,并在其他类型中实现这些方法,从而实现代码的复用和多态。因此,可以将trait看作是实现继承的一种方式。例如,我们可以定义一个trait来表示动物的基本属性和行为:
1 | trait Animal { |
然后,我们可以定义一个实现了Animal trait的结构体Dog,它拥有Animal trait中定义的方法:
1 | struct Dog { |
接下来,我们可以定义一个Cat结构体,同样实现Animal trait中定义的方法:
1 | struct Cat { |
通过这种方式,我们可以在不使用传统面向对象语言的继承机制的情况下,定义多个实现了Animal trait的结构体,从而实现类似继承的功能。
此外,Rust中还可以使用泛型和组合等机制来实现代码的复用和组合。例如,我们可以定义一个AnimalHolder结构体,它持有一个实现了Animal trait的对象,并提供一些操作这个对象的方法:
1 | struct AnimalHolder<T: Animal> { |
通过这种方式,我们可以在一个结构体中持有一个实现了Animal trait的对象,并对其进行操作,从而实现类似继承的功能。
总的来说,Rust中虽然没有传统面向对象语言中的继承机制,但通过trait、泛型和组合等机制,可以实现类似的代码复用和组合的效果。
move关键字
在 Rust 中,move 是一个关键字,用于标记一个闭包所拥有的变量应该被移动而不是被借用。通常情况下,闭包会捕获其所在环境中的变量,如果不使用 move 关键字,则捕获的变量会以借用的方式传递给闭包。如果使用 move 关键字,则捕获的变量会被移动到闭包内部,闭包在使用这些变量时就不再需要访问其所在环境中的引用了。
在 Rust 中,闭包的捕获行为可以分为三种:
- 通过引用捕获:闭包通过引用访问所在环境中的变量,这些变量不会被移动到闭包内部。
- 通过可变引用捕获:闭包通过可变引用访问所在环境中的变量,这些变量不会被移动到闭包内部。
- 通过值捕获:闭包通过值捕获所在环境中的变量,这些变量会被移动到闭包内部。
使用 move 关键字可以改变闭包的捕获方式,将原本的引用或可变引用改为值捕获。
下面是一个示例,演示了使用 move 关键字将变量移动到闭包内部:
1 | let x = 1; |
在这个示例中,变量 x 被声明为整数类型,并被赋值为 1。然后,我们定义了一个闭包,使用 move 关键字将变量 x 移动到闭包内部,闭包打印变量 x 的值。最后,我们调用闭包并尝试再次打印变量 x 的值,这会导致编译错误,因为变量 x 已经被移动到闭包内部,无法再次访问。
常用的宏
Rust是一种使用宏(macros)非常广泛的语言。宏是一种代码生成器,可以帮助我们消除重复的代码,并且可以帮助我们生成一些代码的变体,以适应不同的情况和需求。以下是一些Rust中常用的宏:
println!和format!- 用于打印输出和格式化字符串assert!- 用于测试和调试,确保一些条件是满足的vec!- 用于创建Vec类型的实例vec_deque!- 用于创建VecDeque类型的实例hash_map!- 用于创建HashMap类型的实例assert_eq!- 用于测试和调试,确保两个值相等cfg!- 用于编译时条件检查,根据不同的条件生成不同的代码env!- 用于读取环境变量的值concat!- 用于将多个字符串拼接成一个字符串include!- 用于将一个文件的内容嵌入到另一个文件中
这些宏是Rust编程中非常常用的一些宏,还有许多其他的宏可以在需要时使用。