前言
一个典型的机器学习过程从数据收集开始,要经历多个步骤,才能得到需要的输出。这非常类似于流水线式工作,即通常会包含源数据ETL(抽取、转化、加载),数据预处理,指标提取,模型训练与交叉验证,新数据预测等步骤。
在介绍工作流之前,我们先来了解几个重要概念:
DataFrame:使用Spark SQL中的DataFrame作为数据集,它可以容纳各种数据类型。
较之 RDD,包含了 schema 信息,更类似传统数据库中的二维表格。
它被 ML Pipeline 用来存储源数据。例如,DataFrame中的列可以是存储的文本,特征向量,真实标签和预测的标签等。
Transformer:翻译成转换器,是一种可以将一个DataFrame转换为另一个DataFrame的算法。
比如
一个模型就是一个 Transformer。它可以把 一个不包含预测标签的测试数据集 DataFrame 打上标签,转化成另一个包含预测标签的 DataFrame。技术上,Transformer实现了一个方法transform(),它通过附加一个或多个列将一个DataFrame转换为另一个DataFrame。
Estimator:翻译成估计器或评估器,它是学习算法或在训练数据上的训练方法的概念抽象。
在 Pipeline 里通常是被用来操作 DataFrame 数据并生产一个 Transformer。从技术上讲,Estimator实现了一个方法fit(),它接受一个DataFrame并产生一个转换器。如一个随机森林算法就是一个 Estimator,它可以调用fit(),通过训练特征数据而得到一个随机森林模型。
Parameter:Parameter 被用来设置 Transformer 或者 Estimator 的参数。现在,所有转换器和估计器可共享用于指定参数的公共API。
ParamMap是一组(参数,值)对。
PipeLine:翻译为工作流或者管道。工作流将多个工作流阶段(转换器和估计器)连接在一起,形成机器学习的工作流,并获得结果输出。
工作流如何工作
要构建一个 Pipeline工作流,首先需要定义 Pipeline 中的各个工作流阶段PipelineStage,(包括转换器和评估器),比如指标提取和转换模型训练等。有了这些处理特定问题的转换器和 评估器,就可以按照具体的处理逻辑有序的组织PipelineStages 并创建一个Pipeline。
引用
build.sbt
1 | name := "SparkDemo01" |
DataFrame
创建
使用class
1 | case class Rating(userId: Int, movieId: Int, rating: Float) |
使用StructType
1 | val fields = Array(StructField("name", StringType, nullable = true), StructField("age", StringType, nullable = true)) |
其中
1 | val list = Array("xiaoming,10", "xiaohong,12", "xiaogang,18") |
也可以从文件中读取
1 | val rdd = spark.sparkContext.textFile("file:///D:\\spark_study\\movie.txt") |
toDF
1 | val testData = spark.createDataFrame(Seq( |
保存文件
1 | ratings.select("userId", "movieId", "rating") |
注意
保存的路径传的是文件夹路径,不是文件的具体路径
日志配置
1 | Logger.getLogger("org").setLevel(Level.ERROR) |
简单机器计算示例-单词分析
分析句中是否包含spark
1 | package org.example |
运行结果
(4, i j k spark) –> probability=[0.3966631509161168,0.6033368490838832], prediction=1.0
(5, l m n) –> probability=[0.8763117923754867,0.12368820762451327], prediction=0.0
(6, spark a) –> probability=[0.09195287547527402,0.908047124524726], prediction=1.0
(7, apache hadoop) –> probability=[0.9583167817017002,0.041683218298299796], prediction=0.0
特征抽取
TF-IDF (HashingTF and IDF)
“词频-逆向文件频率”(TF-IDF)是一种在文本挖掘中广泛使用的特征向量化方法,它可以体现一个文档中词语在语料库中的重要程度。
在Spark ML库中,TF-IDF被分成两部分:TF (+hashing) 和 IDF。
TF: HashingTF 是一个Transformer,在文本处理中,接收词条的集合然后把这些集合转化成固定长度的特征向量。这个算法在哈希的同时会统计各个词条的词频。
IDF: IDF是一个Estimator,在一个数据集上应用它的fit()方法,产生一个IDFModel。 该IDFModel 接收特征向量(由HashingTF产生),然后计算每一个词在文档中出现的频次。IDF会减少那些在语料库中出现频率较高的词的权重。
查看词频
1 | package org.example |
我们可以看到打印


最终结果
[(2000,[240,338,369,1756],[0.5753641449035617,0.5753641449035617,0.28768207245178085,0.28768207245178085]),0]
[(2000,[183,395,951,1024,1295],[0.6931471805599453,2.0794415416798357,0.6931471805599453,0.6931471805599453,0.6931471805599453]),0]
[(2000,[240,338,369,1330,1756],[0.28768207245178085,0.5753641449035617,0.28768207245178085,0.6931471805599453,0.28768207245178085]),1]
Word2Vec
词意向量 单词的词义越接近 值也会越接近
1 | package org.example |
我们可以看到结果

单词计数
1 | package org.example |
结果

最终取”i”, “like”, “you”的单词计数

特征变换–标签和索引的转化
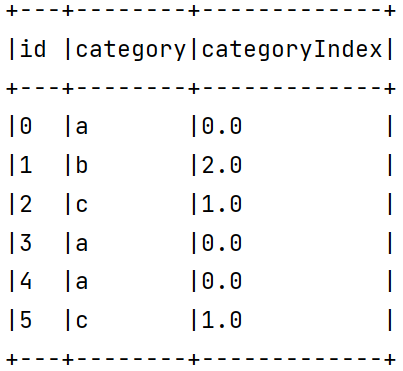
StringIndexer
1 | package org.example |
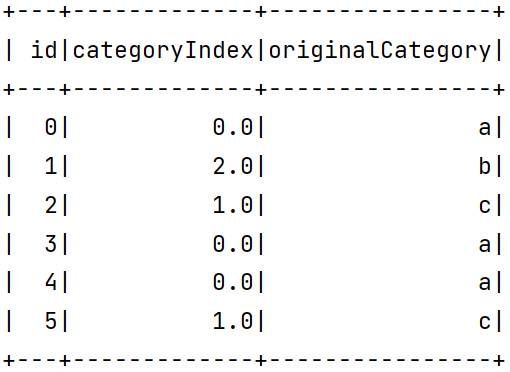
IndexToString
1 | package org.example |
VectorIndexer
之前介绍的StringIndexer是针对单个类别型特征进行转换,倘若所有特征都已经被组织在一个向量中,又想对其中某些单个分量进行处理时,Spark ML提供了VectorIndexer类来解决向量数据集中的类别性特征转换。
通过为其提供maxCategories超参数,它可以自动识别哪些特征是类别型的,并且将原始值转换为类别索引。它基于不同特征值的数量来识别哪些特征需要被类别化,那些取值可能性最多不超过maxCategories的特征需要会被认为是类别型的。
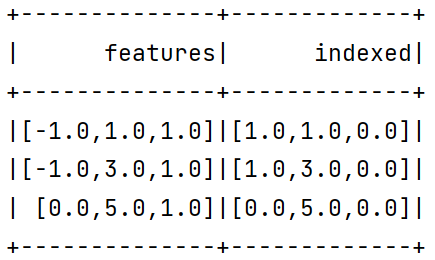
在下面的例子中,我们读入一个数据集,然后使用VectorIndexer训练出模型,来决定哪些特征需要被作为类别特征,将类别特征转换为索引,这里设置maxCategories为2,即只有种类小于2的特征才被认为是类别型特征,否则被认为是连续型特征:
1 | package org.example |
可以看到,0号特征只有-1,0两种取值,分别被映射成0,1,而2号特征只有1种取值,被映射成0。
特征选取–卡方选择器
特征选择(Feature Selection)指的是在特征向量中选择出那些“优秀”的特征,组成新的、更“精简”的特征向量的过程。它在高维数据分析中十分常用,可以剔除掉“冗余”和“无关”的特征,提升学习器的性能。
特征选择方法和分类方法一样,也主要分为有监督(Supervised)和无监督(Unsupervised)两种,卡方选择则是统计学上常用的一种有监督特征选择方法,它通过对特征和真实标签之间进行卡方检验,来判断该特征和真实标签的关联程度,进而确定是否对其进行选择。
和ML库中的大多数学习方法一样,ML中的卡方选择也是以estimator+transformer的形式出现的,其主要由ChiSqSelector和ChiSqSelectorModel两个类来实现。
1 | package org.example |
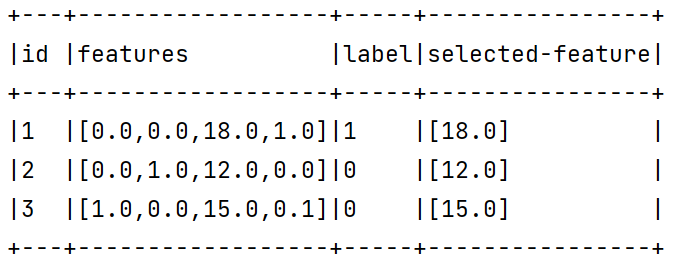
现在,用卡方选择进行特征选择器的训练,为了观察地更明显,我们设置只选择和标签关联性最强的一个特征(可以通过setNumTopFeatures(..)方法进行设置)
结果
协同过滤算法
概念
协同过滤是一种基于一组兴趣相同的用户或项目进行的推荐,它根据邻居用户(与目标用户兴趣相似的用户)的偏好信息产生对目标用户的推荐列表。
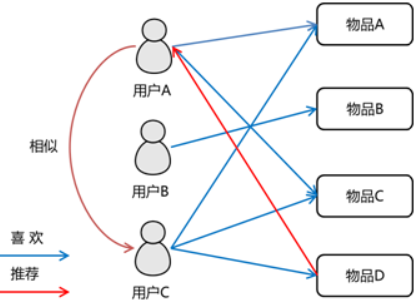
示例
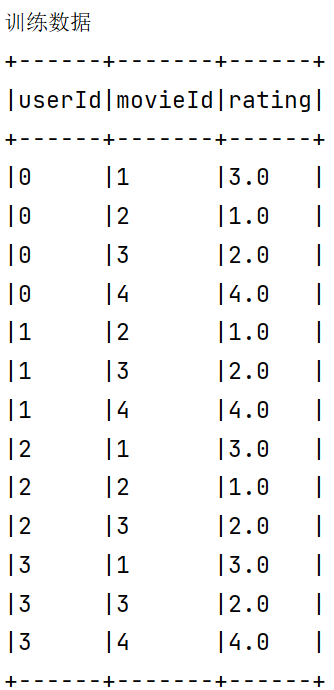
我们有这样的一个数据 分别为用户ID::电影ID::用户对电影的评分
1 | 0::1::3.0 |
我们现在要根据原有的数据进行训练来预测其他用户的打分
1 | package org.example |
结果

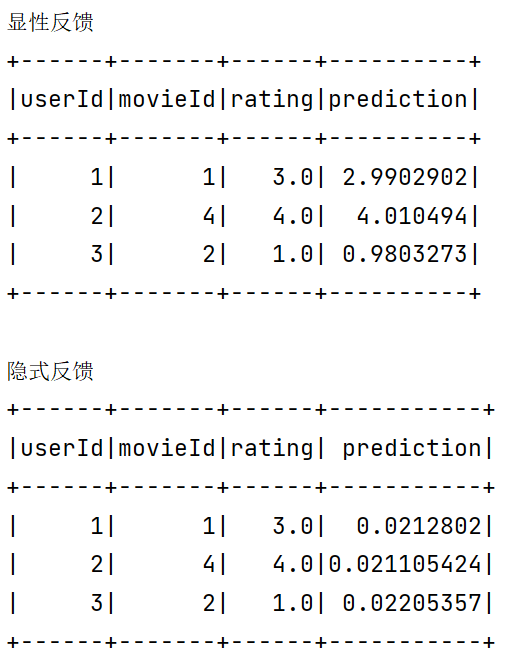

隐性反馈 vs 显性反馈
显性反馈行为包括用户明确表示对物品喜好的行为,
隐性反馈行为指的是那些不能明确反应用户喜好的行为。
在许多的现实生活中的很多场景中,我们常常只能接触到隐性的反馈,例如页面游览,点击,购买,喜欢,分享等等。
基于矩阵分解的协同过滤的标准方法,一般将用户商品矩阵中的元素作为用户对商品的显性偏好。
本质上,这个方法将数据作为二元偏好值和偏好强度的一个结合,而不是对评分矩阵直接进行建模。因此,评价就不是与用户对商品的显性评分,而是与所观察到的用户偏好强度关联起来。然后,这个模型将尝试找到隐语义因子来预估一个用户对一个商品的偏好。
参数说明
在 ML 中的实现有如下的参数:
numBlocks是用于并行化计算的用户和商品的分块个数 (默认为10)。rank是模型中隐语义因子的个数(默认为10)。maxIter是迭代的次数(默认为10)。regParam是ALS的正则化参数(默认为1.0)。implicitPrefs决定了是用显性反馈ALS的版本还是用使用隐性反馈数据集的版本(默认是false,即用显性反馈)。alpha是一个针对于隐性反馈 ALS 版本的参数,这个参数决定了偏好行为强度的基准(默认为1.0)。nonnegative决定是否对最小二乘法使用非负的限制(默认为false)。可以调整这些参数,不断优化结果,使均方差变小。比如:imaxIter越大,regParam越 小,均方差会越小,推荐结果较优。
错误
我在提交了一个mllib的als推荐算法,提示:
22/05/25 15:25:21 WARN BLAS: Failed to load implementation from: com.github.fommil.netlib.NativeSystemBLAS
22/05/25 15:25:21 WARN BLAS: Failed to load implementation from: com.github.fommil.netlib.NativeRefBLAS
22/05/25 15:25:22 WARN LAPACK: Failed to load implementation from: com.github.fommil.netlib.NativeSystemLAPACK
22/05/25 15:25:22 WARN LAPACK: Failed to load implementation from: com.github.fommil.netlib.NativeRefLAPACK
这个问题是因为als是一个分布式算法,在本地执行时失败,在–master yarn模式下执行正常
这个错误不影响执行。